
에서 마저 OpenAI API 프로토콜의 Create chat completion를 마저 코드화를 진행하고자 한다.
1. OpenAI API - Chat Completion
https://platform.openai.com/docs/api-reference/chat/create
위 페이지에 소개하는 chat completion을 코드화를 Pydantic 를 통해 진행하고자 한다.
1.1 Request
chat completion의 요청부분은 총 5개의 Task
Default / Image input / Streaming / Functions / Logprobs
이 존재하나, 이 중 Default, Streaming만을 구현한다.
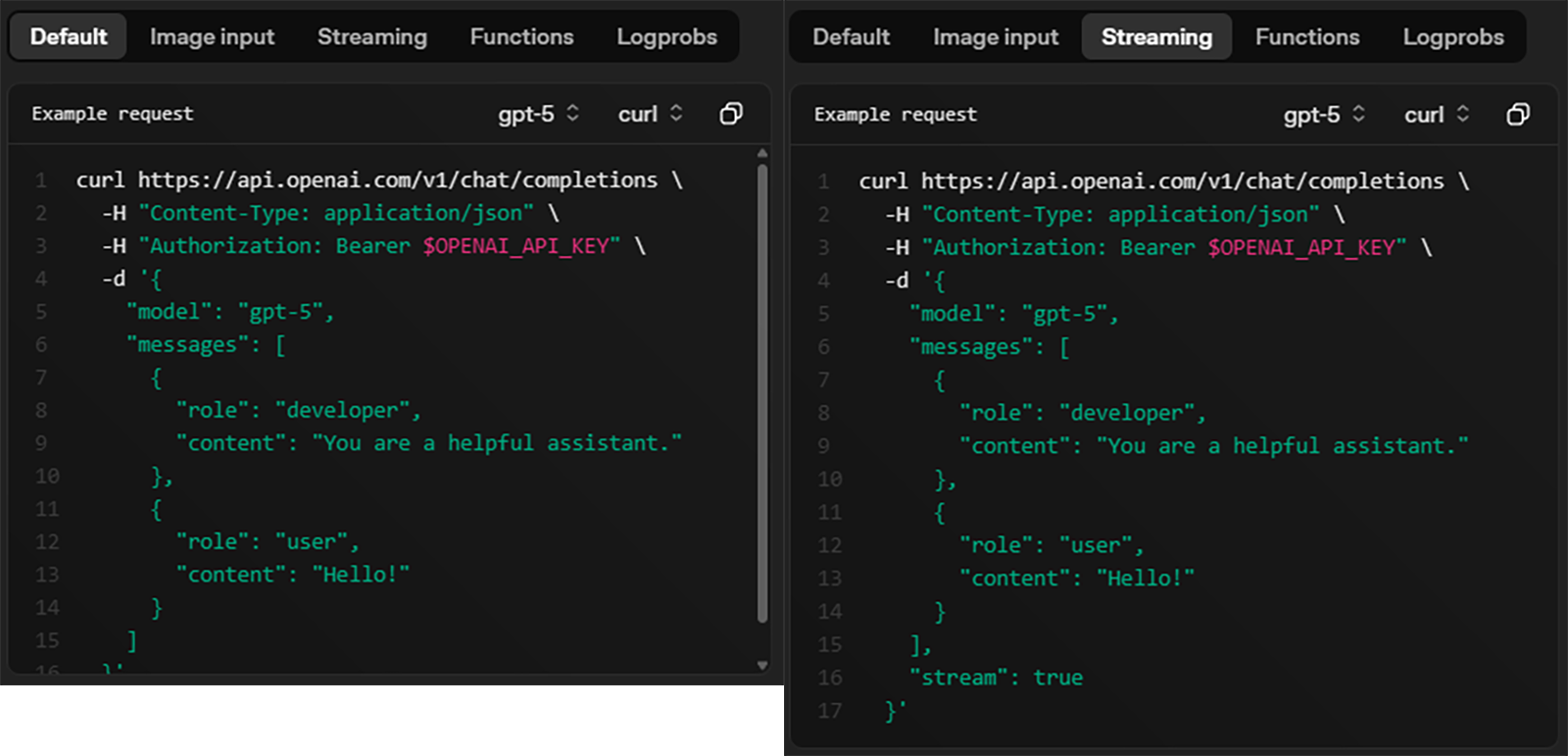
따라서 구현하고자 하는 항목은 Request body에서
message, model, stream 3가지만 필수로 구현하면 되지만
Sampling Output Configuration에 해당하는
temperature, top_k, top_p, presence_penalty 4가지 항목은 메뉴얼에는 없지만 따로 구현을 해두는 것을 권장한다.
제일 먼저 message 내 항목을 구현하고자 하는데
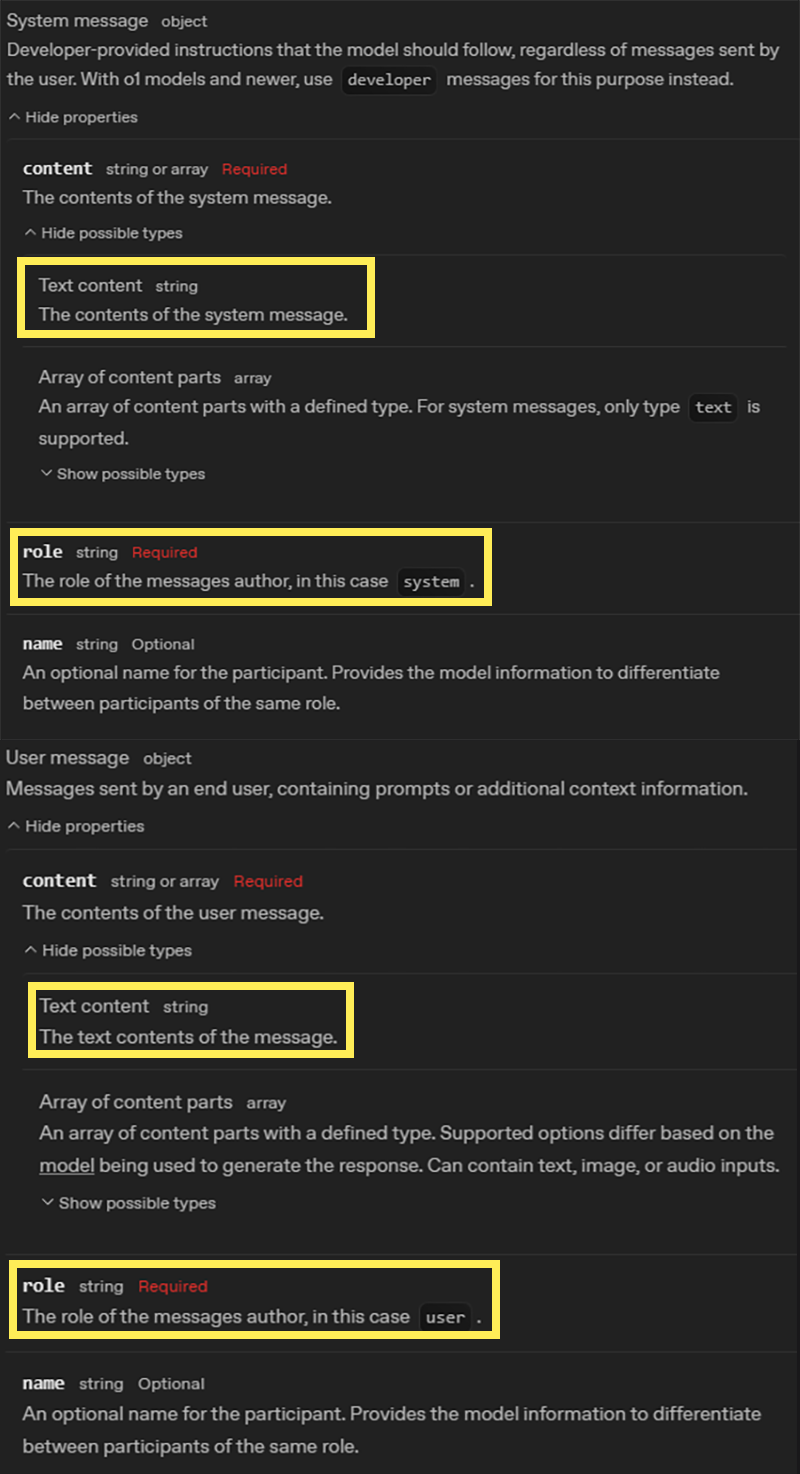
message내 content, role만 구현하고, content도 Text content만 구현한다.
이 내용을 코드화 하면 아래와 같다.
from typing import List, Optional
from pydantic import BaseModel, Fieldclass ChatCompletionRequestMessage(BaseModel):
role: str
content: strclass GenerationConfig(BaseModel):
templature: float
top_p: float
top_k: int
repetition_penalty: float이렇게 Request의 가장 하위 메세지 프로토콜을 정의한 뒤
Request 메세지 프로토콜을 명세화 하면 된다.
class ChatCompletionRequest(BaseModel):
model: str
messages: List[ChatCompletionRequestMessage]
stream: bool = False
generation_config: GenerationConfig위 3개의 클래스를 class diagram으로 표현하면 아래와 같다.
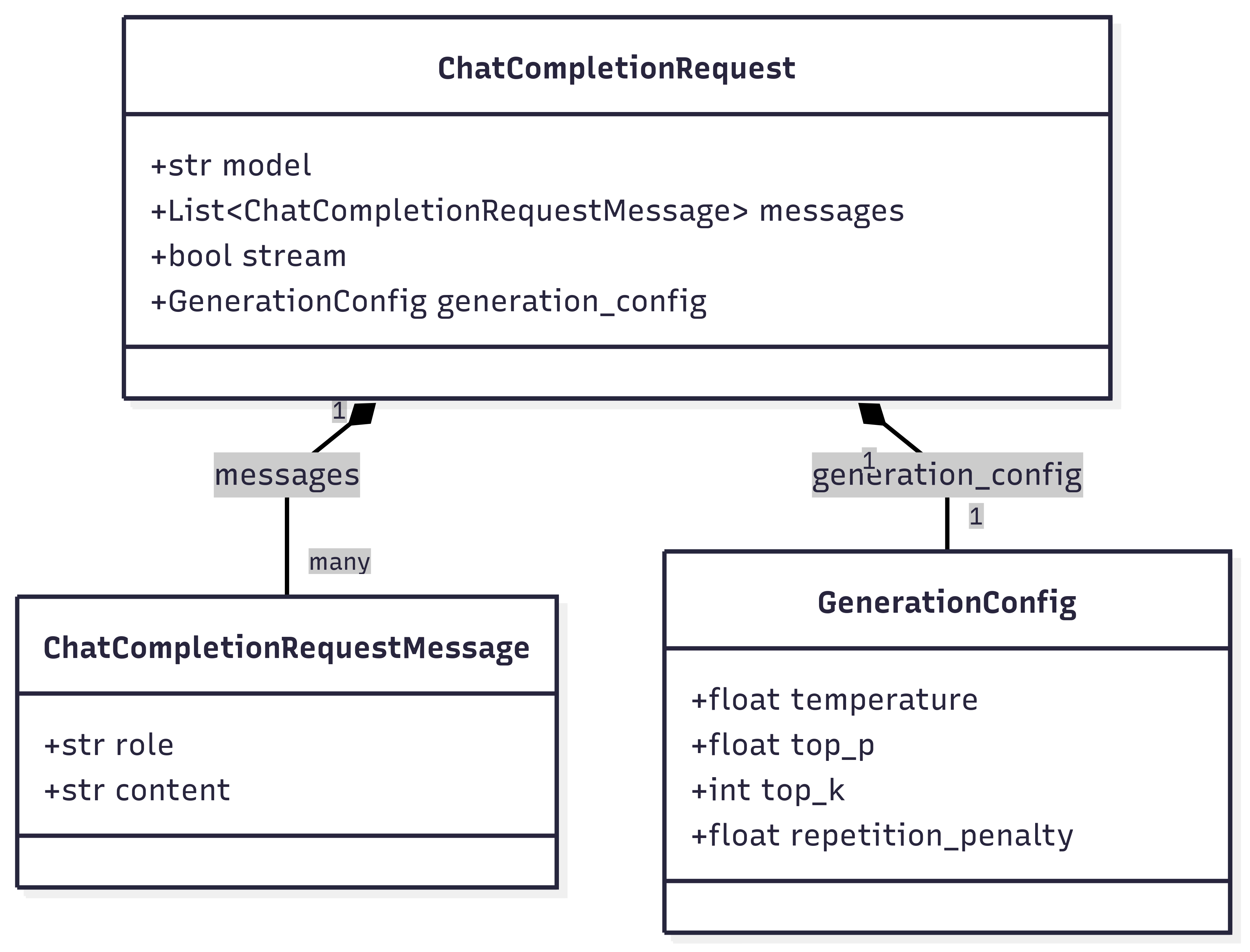
1.2 Response
다음으로 chat completion의 Response 프로토콜을 분석한다.
공통으로 필요한 body 정보는 https://platform.openai.com/docs/api-reference/chat/object 여기에서 좀 찾아봐야 하는데
1) choices : LLM모델이 추론작업을 통해 응답을 생성할 때 이게 1개만 생성되는 경우가 일반적이지만 Beam Search 같은 기능을 활성화 시켱서 여러 개의 응답을 생성하라고 하면 응답이
choices[0], choices[1], ... , choices[n] 이렇게 여러개 생성 가능해진다.
참고로 위 기능을 가능케 하려면 chat completion - Request에 n이라는 body가 포함되어 있는데
지금의 포스트에는 해당 기능을 구현하지는 않았다.
음.. 이거는 request에서는 구현을 안하고, response에서는 구현을 하는 식으로 코드화 한다.
이유는 choices가 가장 하위 컨텐츠가 아니라 그 아래 또 포함시켜야 할 여러 항목이 있는 중간 컨텐츠라서 빼버리면 구조가 깨져버린다.
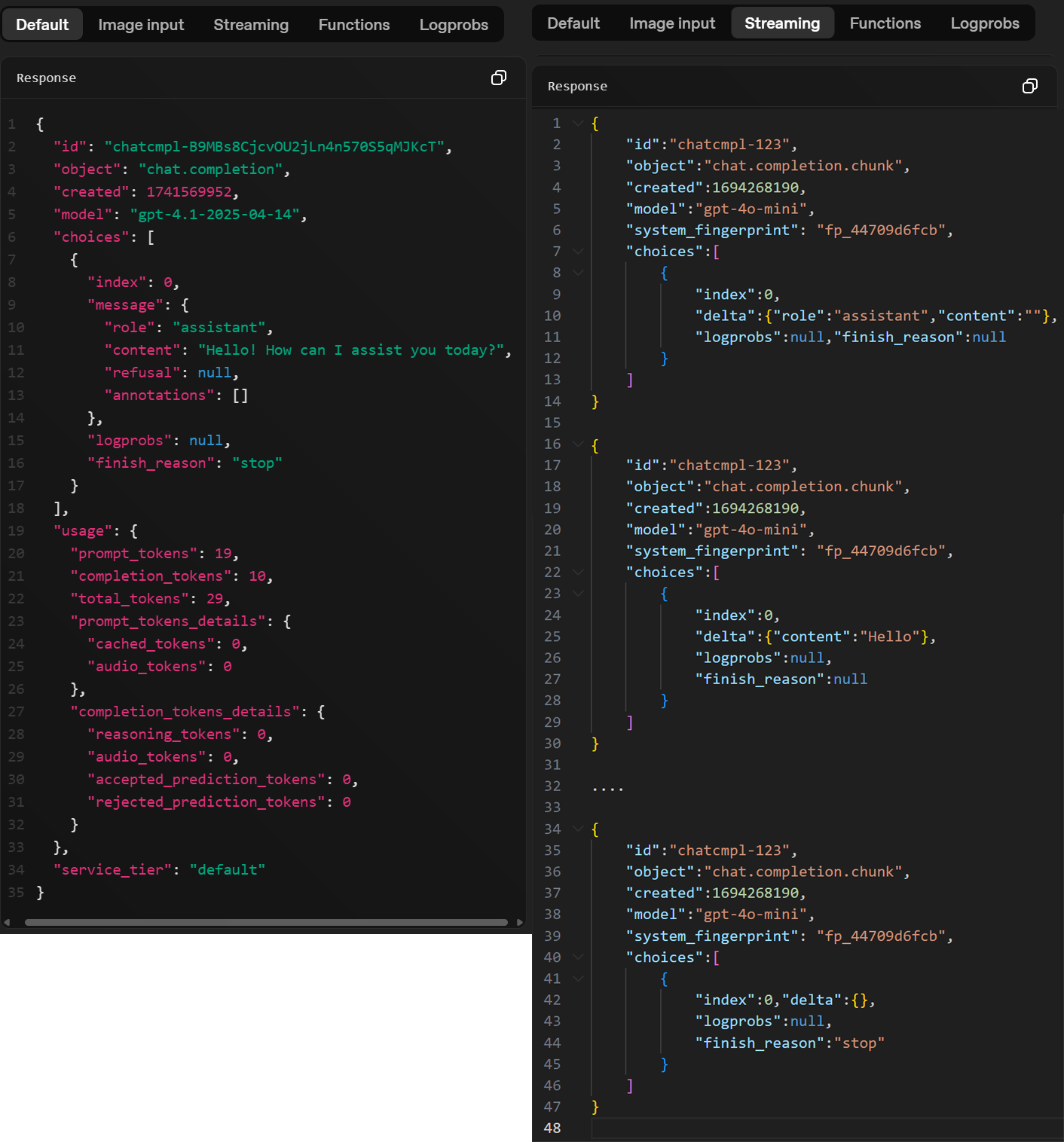
아무튼 choices에는 stream 옵션이 False / True에 따라서 하위 컨텐츠 항목이 조금 변경되는데
1-1) stream = False 비동기 추론 방식일 때 하위 컨텐츠
index : choices[0], choices[1], ... , choices[n] 이런 여러 응답일 때의 응답 번호
message : 추론 응답 내용 -> request의 message보다 더 많은 항목이 있지만 필수로 role, content만 구현하여 동일하게 구성
finish_reason : 응답이 종료된 이유를 주석처럼 기재
1-2) stream = True 비동기 스트리밍 방식일 때 하위 컨텐츠
index, finish_reason두개 항목은 필수로 포함되며,
message와 항목은 배치되나 입력되는 데이터가 살짝 달라지는게 delta이다.
delta도 구성하는 컨텐츠 정보는 role, content로 같으나, content에 입력되는 데이터가 스트리밍으로 생성되는 '토큰' 이 기입된다. message - content에는 LLM이 추론한 완성된 문장이 기입되지만 스트리밍이니 문장이 아닌 생성된 토큰이 기입되는 차이가 있다.
2) usage : 이 항목은 stream = False 비 동기 추론일때만 발생하는 컨텐츠인데 입력 및 출력에 관련된 모든 토큰정보가
prompt_tokens, completion_tokens, total_tokens로 표현된다.
3) response header body : 위 1, 2 하위 컨텐츠를 모두 취합하는 최 상위 body는 id, object, created, model 4가지 정보가 포함된다
id : chatcmpl 접두어가 붙은 뒤 메세지 정보를 식별할 수 있도록 뒤에 고유 정보를 붙인다. 이때 난수나 아니면 숫자 uuid 등을 활용하여 정보값을 생성하여 붙인다.
object : stream = False 일때는 chat.completion 만을 붙이고, stream = True 일때는 chat.completion.chunk를 기입하여 메세지 종류에 대한 설명정보를 기재한다.
model : 해당 응답을 생성하는데 사용한 모델 이름을 기재
그 외로 system_fingerprint, service_tier등이 있지만 자잘한건 빼고 구현한다.
class ChatCompletionMessage(BaseModel):
role: Optional[str]
content: Optional[str]class ChatCompletionChoice(BaseModel):
index: int
message: ChatCompletionMessage
logprobs: Optional[dict]
finish_reason: strclass ChatCompletionUsage(BaseModel):
prompt_tokens: int
completion_tokens: int
total_tokens: intclass ChatCompletionStreamChoice(BaseModel):
index: int
delta: ChatCompletionMessage
finish_reason: Optional[str]class ChatCompletionResponse(BaseModel):
id: str
object: str
created: int
model: str
choices: List[ChatCompletionChoice]
usage: ChatCompletionUsageclass ChatCompletionStreamResponse(BaseModel):
id: str
object: str
created: int
model: str
choices: List[ChatCompletionStreamChoice]이렇게 response는 3개의 계층으로 구조화하여 프로토콜을 명세할 수 있으며, 전체 코드의 클래스 구조도는 아래와 같다.
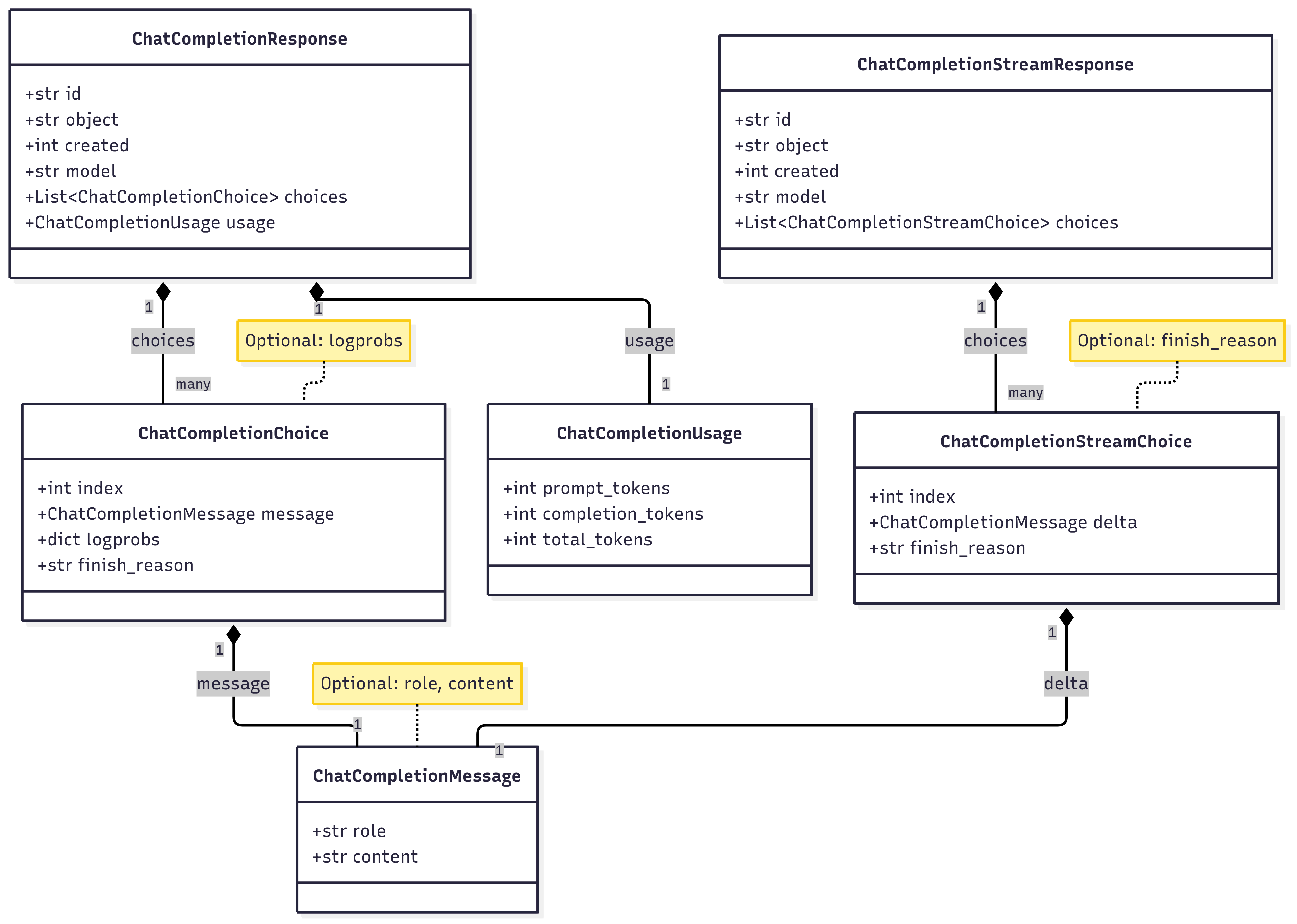
이렇게 2개의 통신 프로토콜
chat completion - request
chat completion - response
를 구현하고 각각의 분기로 stream 옵션을 추가하면 LLM과의 기본 통신 프로토콜 구현은 완료가 된다.
2.
