
이번 포스트는
WSL-우분투에서
UV패키지 매니저로 개발환경을 구성하고vllm추론엔진으로gpt-oss모델을 구동하는데RTX 5000시리즈(SM 12.0 아키텍쳐)로
구동하는 과정을 설명하는 포스트이다.
1. gpt-oss 깃허브 분석
https://github.com/openai/gpt-oss
첨부한 깃허브는 OpenAI가 GPT-OSS시리즈를 출시하면서 사용방법 및 예제코드가 포함된 깃허브인데
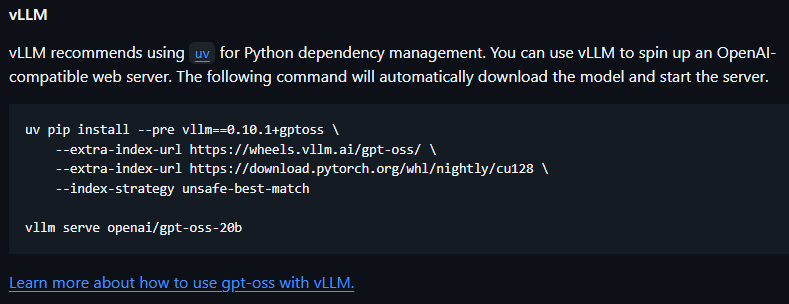
이렇게 vllm 추론엔진으로 uv 패키지 매니저를 통해 설치하면 간단하게 gpt-oss를 서빙이 가능하다고 하지만
실제로 저 명령어로 wsl-우분투에서 하면 안된다.
1.1 uv로 실패조건 확인하기
- uv 설치
curl -LsSf https://astral.sh/uv/install.sh | sh- 프로젝트 폴더에서 uv초기화
mkdir [프로젝트 폴더]
cd [프로젝트 폴더]
uv init- 가상환경 생성
# 시스템에 설치된 파이썬이랑 파이썬 패키지를 그대로 가져온다
uv venv --python $(which python3) --system-site-packages- 공식 가이드북의 uv - vllm 설치 수행
uv pip install --pre vllm==0.10.1+gptoss \
--extra-index-url https://wheels.vllm.ai/gpt-oss/ \
--extra-index-url https://download.pytorch.org/whl/nightly/cu128 \
--index-strategy unsafe-best-match
# 설치 이후 모델 실행
uv run vllm [허깅페이스 체크포인트 gpt-oss모델 경로]위와 같은 공식 가이드북의 vllm실행 명령어를 수행하면

첨부한 사진처럼 FlashAttention 3오류가 발생한다
이 오류는 해소하기가 여간 힘든게 아니라서 결국 문제의 해결책으로 귀결되는건
https://docs.vllm.ai/en/stable/deployment/docker.html
첨부한 웹페이지의 vllm/vllm-openai:latest
https://hub.docker.com/r/vllm/vllm-openai/tags
이 vllm 도커 컨테이너를 설치해서 gpt-oss를 구동하는 방식이다.
그러나 필자에게 있어 현재 wsl-우분투 라는 가상OS환경이 있는데 컨테이너를 또 올려서 gpt-oss를 구동하는건 자존심이 허락하는 상황은 아니다...
그래서 깃허브 내용을 분석을 했으니
아에 첨부한 도커 컨테이너를 리버스 엔지니어링을 해서 WSL-우분투에서 vllm 추론엔진으로 gpt-oss를 구동하고자 한다.
2. vllm-openai 컨테이너 분석
먼저 윈도우 환경에서 도커 데스크탑을 설치했다면 아래의 그림처럼
WSL-우분투 에서 도커 데스크탑이 사용가능하게끔 WSL Integration을 수행하자
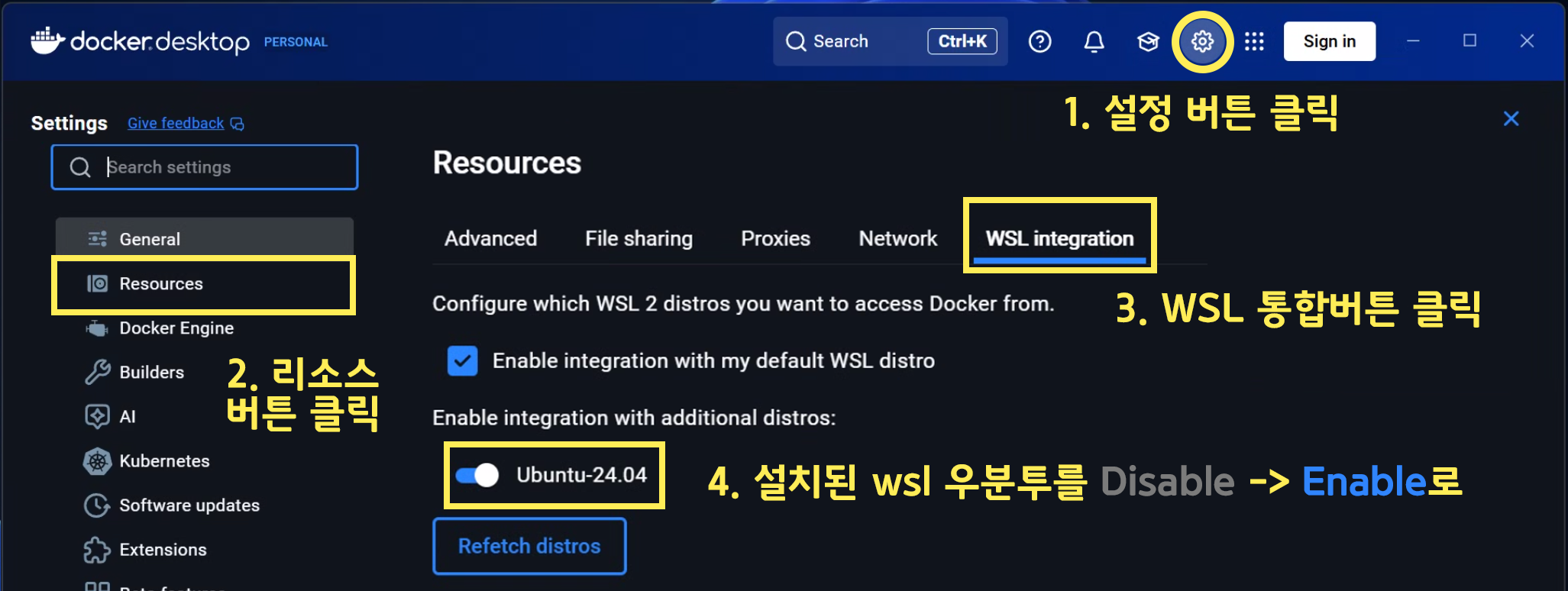
위와 같이 설정하면 WSL에서 바로 도커를 연결하여 사용이 가능해진다
# wsl과 docker 연동 후 wsl환경에서 도커 버전 확인
docker --version
위 사진처럼 버전이 출력되면
아래의 명령어로 vllm-openai 최신버전 컨테이너를 다운로드 후 gpt-oss모델을 구동해보자
docker run --gpus all -p 8000:8000 \
vllm/vllm-openai:latest \
--model openai/gpt-oss-20b \
--gpu-memory-utilization 0.6 \
--max-model-len 4096만약 허깅페이스에서 미리 gpt-oss모델을 다운받았다면 아래와 같이 수행하면 된다
# 허깅페이스에서 다운로드 받은 경로를 컨테이너 내 app/model에 마운트
docker run --gpus all -p 8000:8000 -d \
--name [적용하고 싶은 gpt-oss 컨테이너 이름] \
-v [허깅페이스에서 미리 다운받은 경로]:/app/model \
vllm/vllm-openai:latest \
--model /app/model \
--served-model-name gpt-oss-20b \ # 이걸 추가해야 모델명이 정상등록
--gpu-memory-utilization 0.6 \
--max-model-len 4096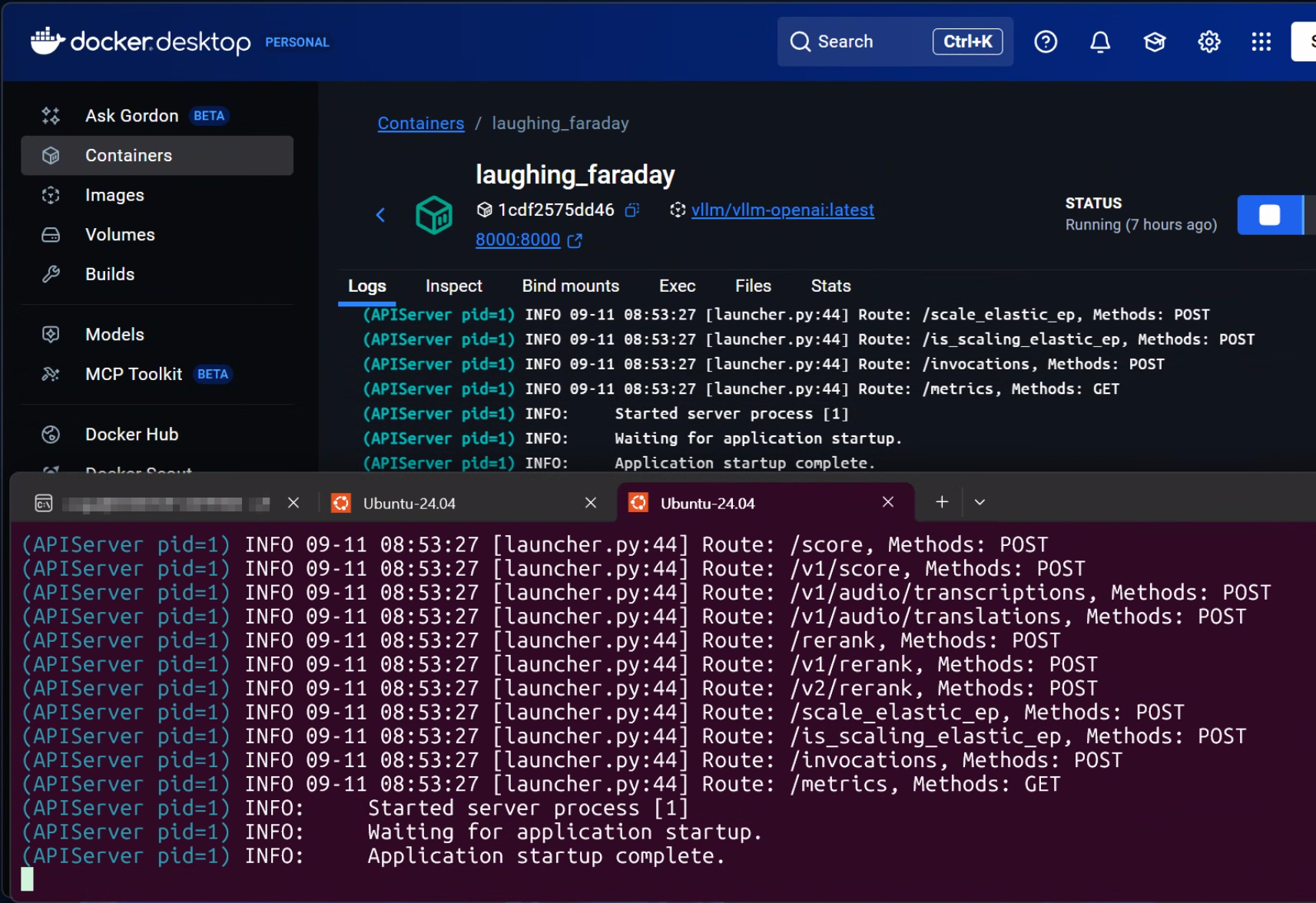
첨부한 사진처럼 vllm-openai 최신 컨테이너는 정상동작하고 gpt-oss 모델을 FlashAttention 3 오류 없이 정상 서빙하는 것을 확인할 수 있다.
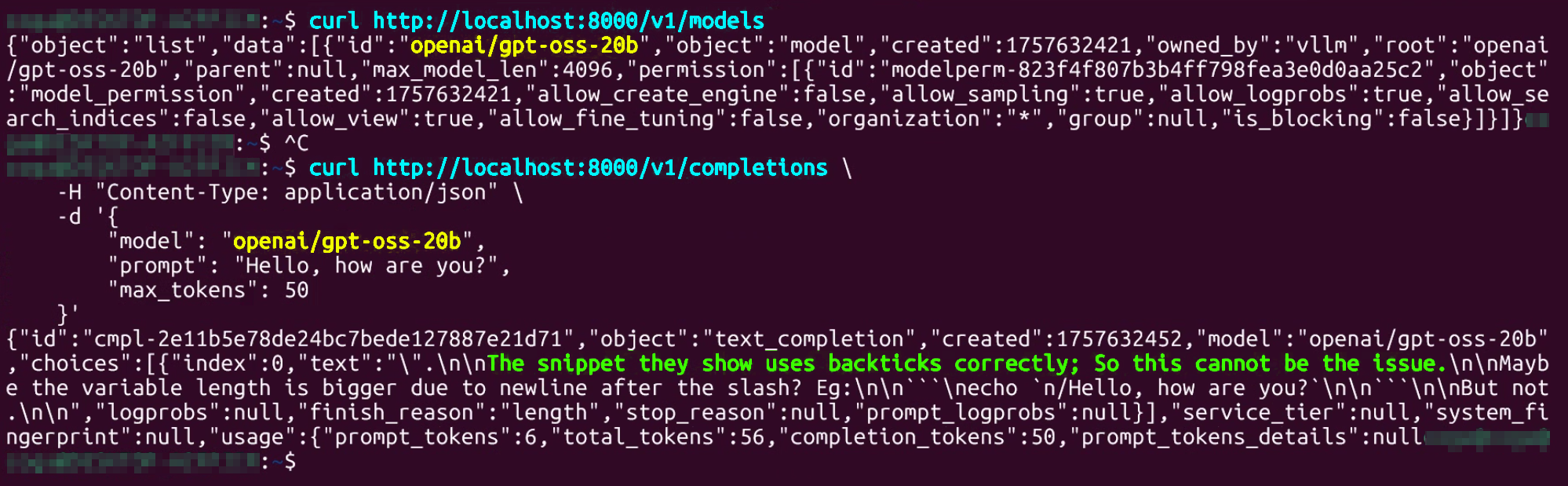
그리고 위 사진처럼 현재 서빙중인 모델, 모델의 추론테스트도 정상적으로 기능하고 있다.
이 컨테이너에 설치된 패키지의 버전 및 설정 정보를 확인한다면 동일하게 컨테이너 없이 wsl-우분투에서 gpt-oss를 기동하는것이 가능하다.
먼저 컨테이너 분석을 위해서는 컨테이너에 접속을 해야 한다.
# 실행 중인 컨테이너 정보 확인
docker ps
# 컨테이너에 접속
docker exec -it [컨테이너 ID] bash
컨테이너에 접속해서 확인할 내용은 vllm 추론엔진이 gpt-oss를 구동하기 위해 적용한 파이썬 패키지 라이브러리들이 어떤 버전으로 구성되어 있는지 확인하는 것과
RTX 5000번대 GPU에 해당되는 CUDA 아키텍쳐인 sm_120이 지원되는지를 확인하는 것이다
pip list | grep -E "(torch|vllm|flash|triton)"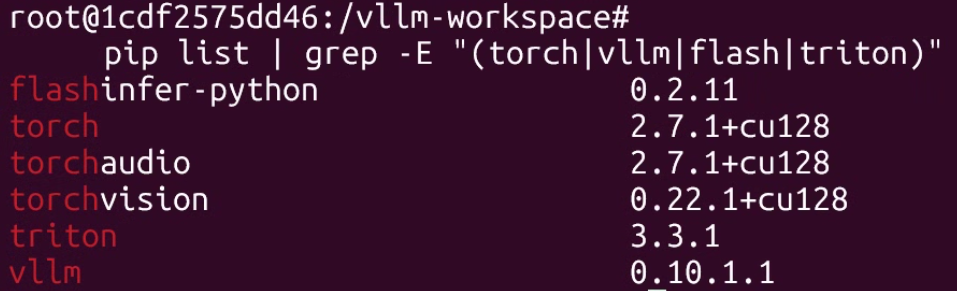
python3 -c "
import torch
print('CUDA archs:', torch.cuda.get_arch_list())
print('SM120 support:', 'sm_120' in torch.cuda.get_arch_list())
"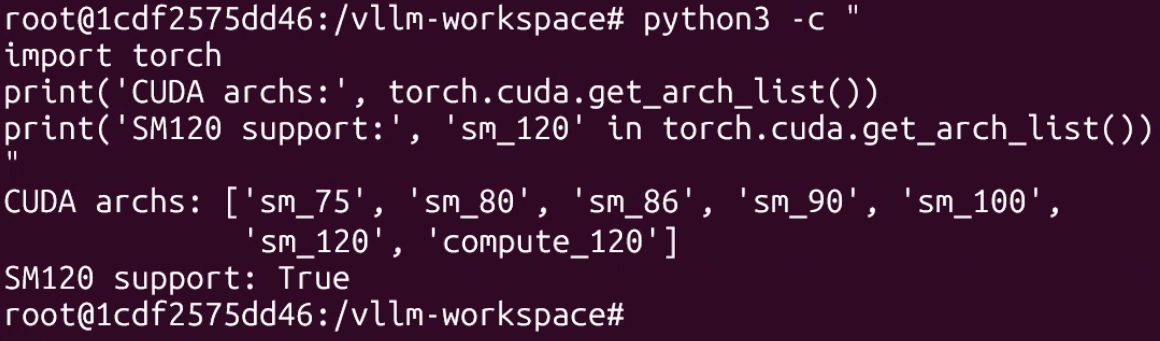
첨부한 사진처럼 docker에서는 sm_120이 지원되게 컴파일 되어 있고 파이토치, triton, flashinfer이 특정 버전이 설치된 것을 확인할 수 있다.
이를 바탕으로 uv로 동일하게 미러하면 된다.
3. uv로 docker환경 미러링
미러링 과정은 라애릐 과정을 순차로 수행하면 된다.
cd [uv 프로젝트 폴더]
# 기존 uv설치 내역 제거 및 재 초기화
rm -rf .venv pyproject.toml uv.lock
uv init# uv위에서 가상환경 설치 및 활성화
uv venv
source .venv/bin/activate# 도커에 기재된 파이토치 버전 설치
uv pip install torch==2.7.1+cu128 torchvision==0.22.1+cu128 torchaudio==2.7.1+cu128 \
--index-url https://download.pytorch.org/whl/cu128# triton과 관련된 추론 엔진 의존 라이브러리 설치
uv pip install nvidia-ml-py
uv pip install triton==3.3.1
uv pip install flashinfer-python==0.2.11# 허깅페이스 체크포인트 모델 구동 관련 라이브러리 설치
uv pip install transformers==4.55.2
uv pip install accelerate# 도커 컨테이너에 기재된 vllm 설치
uv pip install vllm==0.10.1.1
# 주의사항 : 기존 설치된 패키지들 특히 torch가 버전변경되면 안됨여기까지 설정하고 실행검증을 진행하자
python3 -c "
import torch
print('PyTorch version:', torch.__version__)
print('CUDA available:', torch.cuda.is_available())
print('CUDA archs:', torch.cuda.get_arch_list())
print('SM120 support:', 'sm_120' in torch.cuda.get_arch_list())
print('GPU name:', torch.cuda.get_device_name(0))
"python3 -c "
import vllm
print('vLLM version:', vllm.__version__)
from vllm import LLM
print('vLLM import successful')
"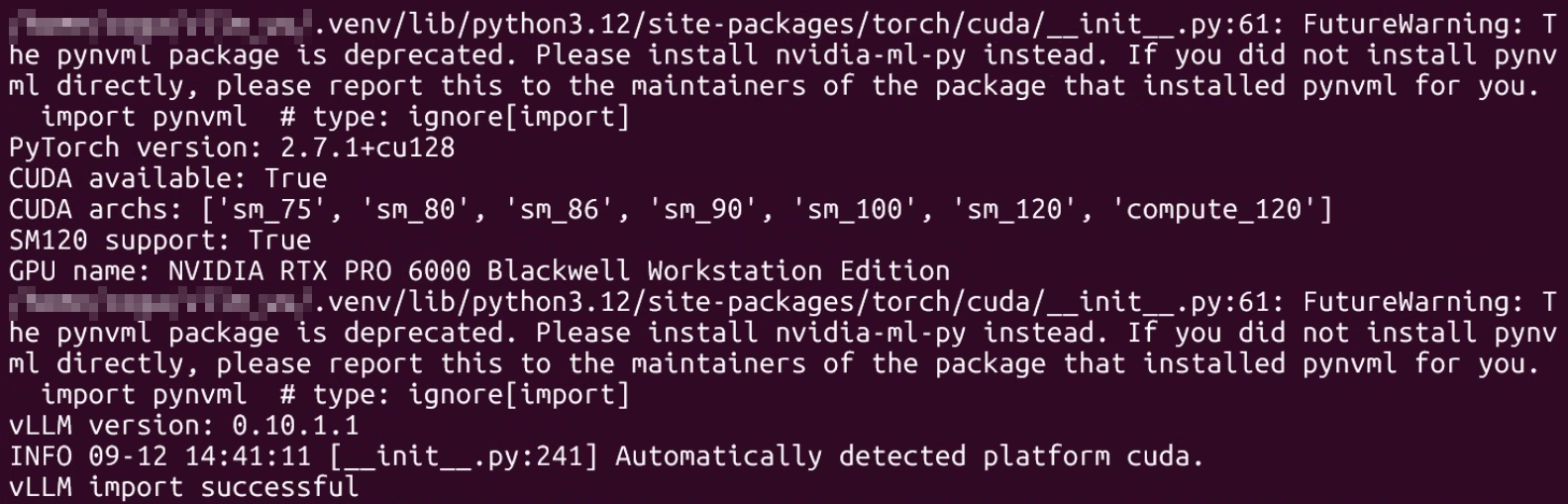
대략 이렇게 뜨면 정상이다.
이제 모델 서빙명령어는 아래와 같다
uv run vllm serve [다운받은 gpt-oss 모델 경로] \
--trust-remote-code \
--max-model-len 4096 \
--gpu-memory-utilization 0.6 \
--port 8001 \
--served-model-name gpt-oss-20b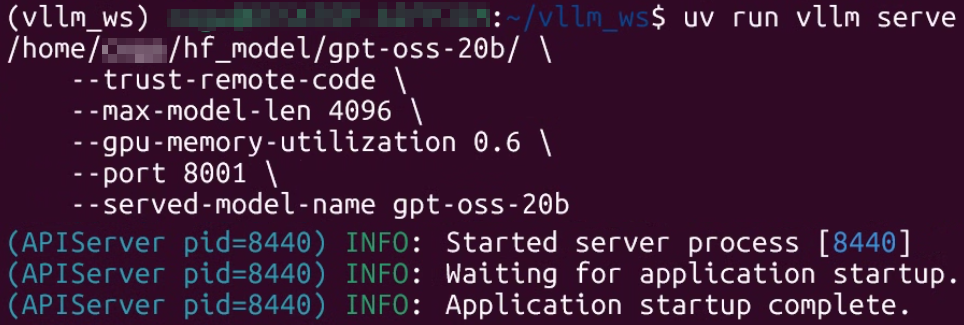
명령어 실행결과가 마지막에 위 3개 글자가 뜨면 정상이다
이제 추론 테스트이다.
# 구동중인 모델 정보 확인
curl http://localhost:8001/v1/models# 간단한 동기 추론 테스트
curl http://localhost:8001/v1/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "gpt-oss-20b",
"prompt": "안녕 너는 누구야?",
"max_tokens": 50
}'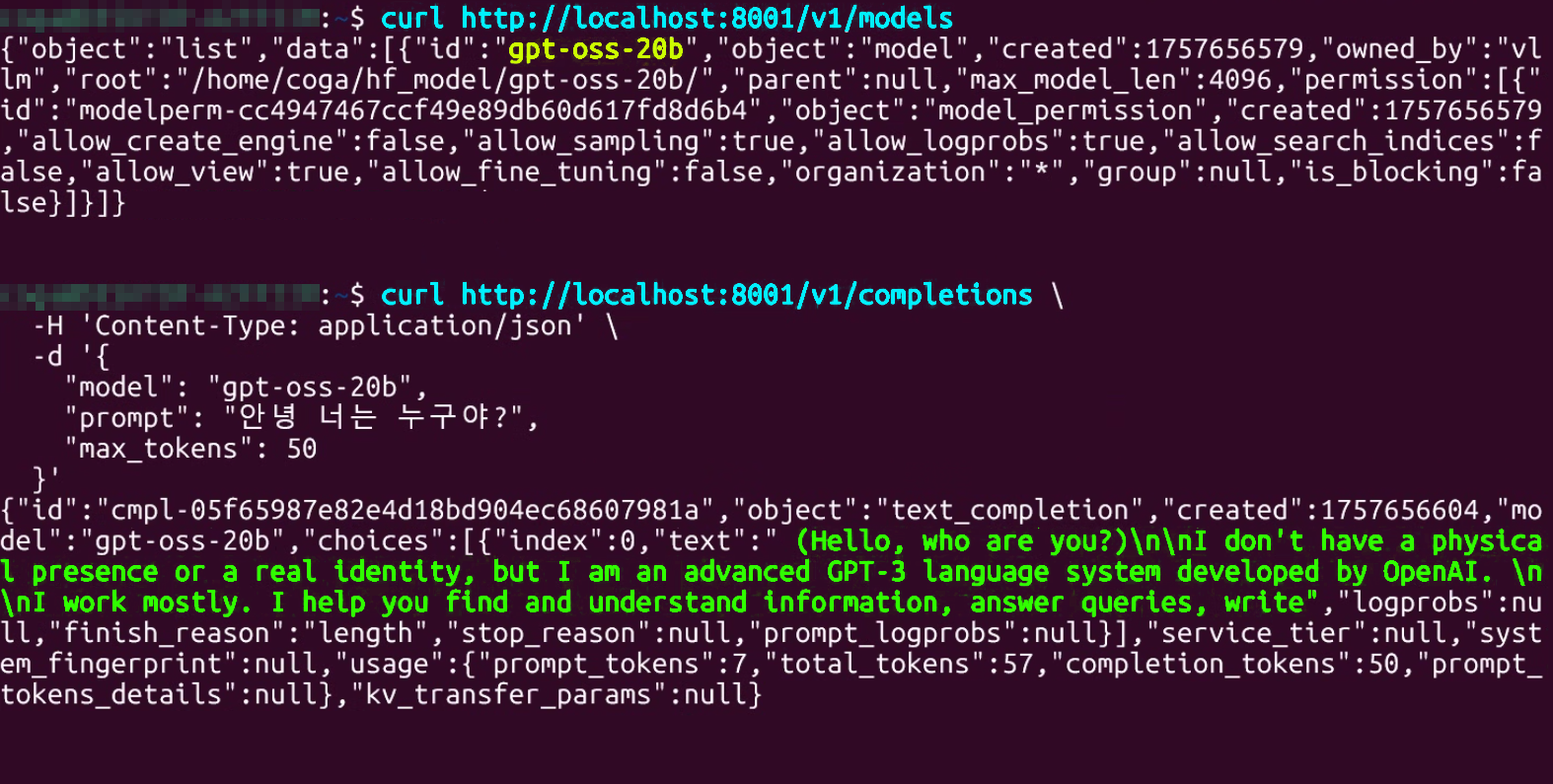
뭔가 참.. 더럽게 안되긴 하는데
아무튼 성공!
