
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. Pooling 기법 이란?
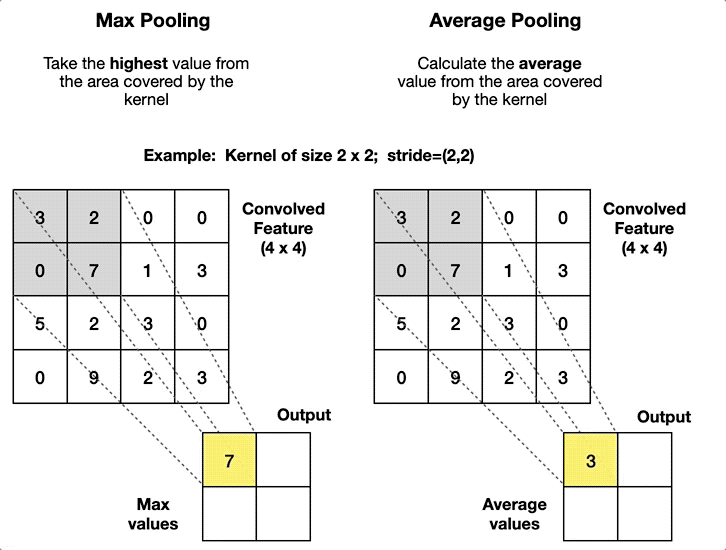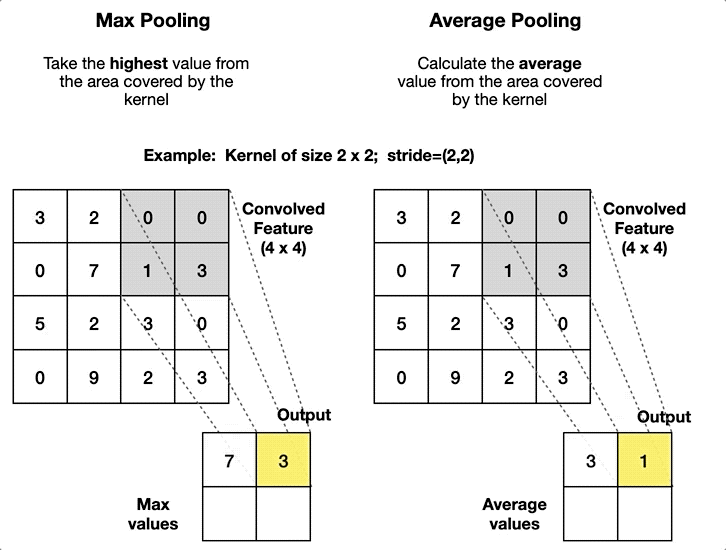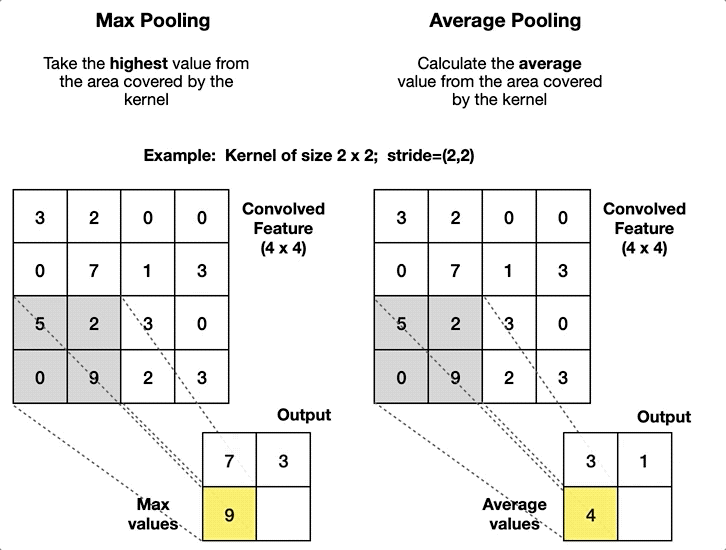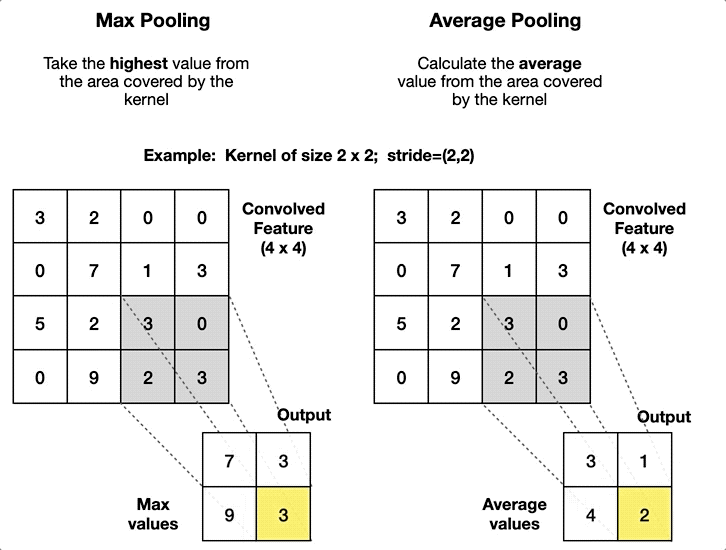
CNN에서 주로 사용되는 Pooling 기법은 입력 이미지의 결과로 나오는 특성 맵(Feature Map)의 크기를 줄이면서 동시에 중요한 정보를 유지하는 효과를 보여준다.
앞선 합성곱 연산인 Conv는 '전체 이미지의 특징을 함축'시키는 효과를 보여주는데
이 함축하는 과정이 '정보를 먼저 선별하고 함축' 하고 싶다면 Pooling 기법을 사용하는 것이다.
통상적으로 Pooling기법은 Noise를 제거하는데 효율이 좋으며,
그 외로
네트워크의 파라미터 수 감소 ->
이로인한 연산량 절감 ->
과적합 방지 효과를 기대할 수 있다.
토막상식
Conv는 전체 이미지의 특징을 '함축'시키는 효과가 있으며, 극단적으로 1x1커널을 사용하는 1x1 Conv는 전체 이미지의 특징을 모두 함축하는 효과를 낸다
-> 이를 잘 활용하는 것이 BottleNeck block
또 Pooling기법의 특징은 매개변수(가중치 Weight와 Bias)가 없으며,
채널 수의 증감이 발생하지 않는다.(input_dim과 output_dim이 일치함)
적용하는 커널(필터)의 개수로 output_dim이 결정되는 Conv와는 다른 점이다.
Pooling 기법도 기본적으로는 합성곱 연산과 동일하게
1) 입력 이미지 외각에 픽셀을 추가하는 Padding
2) 입력 이미지를 훓고 지나가는 Kernel_size
3) 이 Kernel이 지나가는 step단위인 stride
3가지 항목으로 출력 이미지의 크기를 결정할 수 있으며, 공식은 Conv 공식과 동일하다

이때 통상적으로 Pooling기법을 도입할 시 Kernel_size와 Stride의 값을 같게 하여 커널이 입력 이미지를 훑을 때 겹치는 부분이 없게 인자값을 조정한다.
만약 커널이 입력이미지를 겹치면서 훑는다면 이를 Overlapping pooling이라 따로 부르는데 AlexNet 외에는 적용된 사례가 적은 편이다.
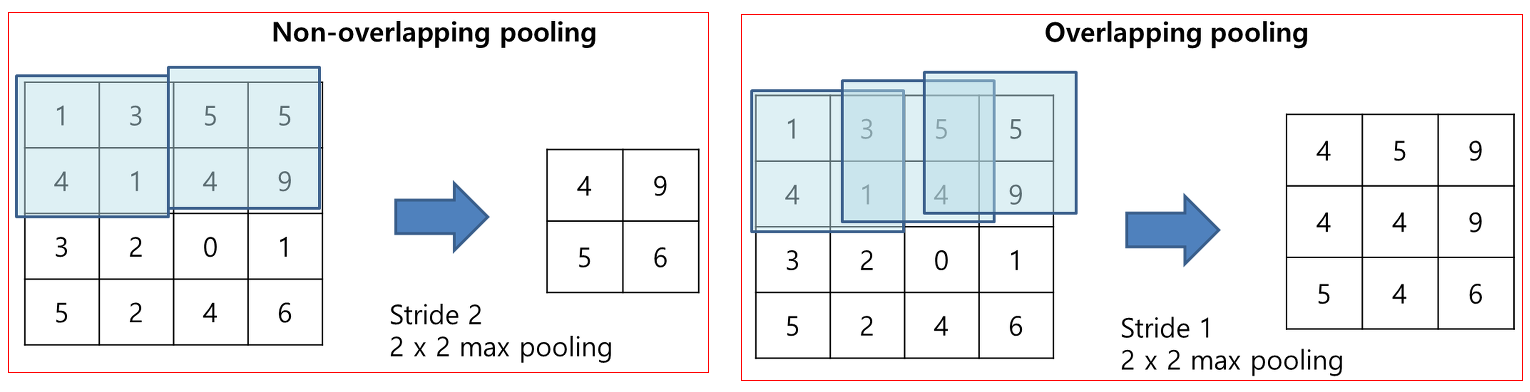
또 Pooling 기법을 사용할 때는 padding을 0을 주거나 아니면 입력 이미지 크기 == 출력 이미지 크기가 되게끔 알아서 padding을 주는 same를 주로 사용한다.
따라서 Pooling기법으로 출력되는 이미지의 크기는 아래 2가지 수식으로 정리된다.
-
, kernel size = stride
-
2. Avg Pool, Max Pool 함수 구현
import numpy as np
def Avg_pool2d(img, pool_size=2, stride=2): #크기를 반 줄이는 AVG_pool
height, width = img.shape
out_h = int((height - pool_size) / stride + 1)
out_w = int((width - pool_size) / stride + 1)
out_img = np.zeros((out_h, out_w), dtype=np.float32)
for y in range(out_h):
for x in range(out_w):
out_img[y,x] = np.mean(img[y*stride : y*stride+pool_size,
x*stride : x*stride+pool_size])
return np.clip(out_img, 0, 255).astype(np.uint8)def Max_pool2d(img, pool_size=2, stride=2): #크기를 반 줄이는 AVG_pool
height, width = img.shape
out_h = int((height - pool_size) / stride + 1)
out_w = int((width - pool_size) / stride + 1)
out_img = np.zeros((out_h, out_w), dtype=np.uint8)
for y in range(out_h):
for x in range(out_w):
out_img[y,x] = np.max(img[y*stride : y*stride+pool_size,
x*stride : x*stride+pool_size])
return np.clip(out_img, 0, 255).astype(np.uint8)두 코드 동일하게 출력 이미지의 크기를 계산하고
계산된 이미지 크기를 기반으로 np.array 자료형 초기화
그 후 이중 for 구문으로 pooling 연산 수행
이 3가지 구조로 이뤄져 있다.
이때 Pooling 기법이 Average(평균), Max(최대값)으로 나뉘는데, 통상 Max Pool 기법이 Noise를 더 잘 제거하는 편이다.

3. 멀티채널 Pooling
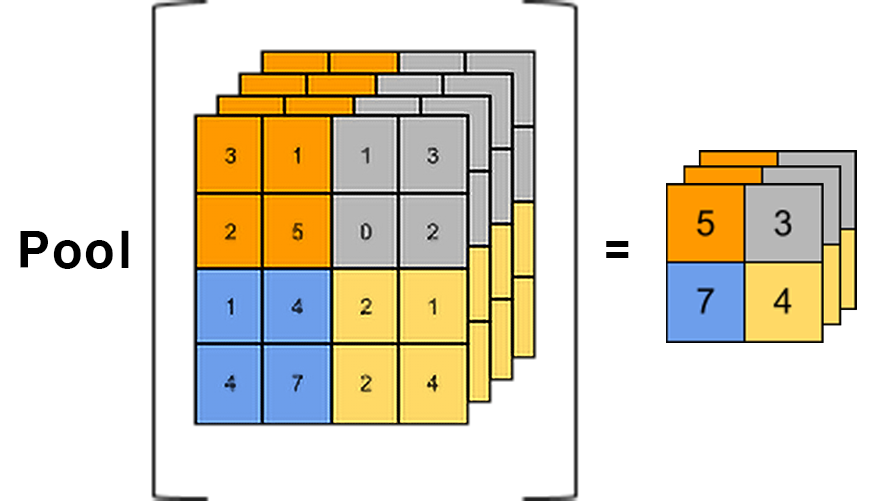 단순하게 위 이미지의 연산을 수행하겠다는 의미지만
단순하게 위 이미지의 연산을 수행하겠다는 의미지만
Pytorch 라이브러리에서 제공하는 torch.nnMaxPool2d, torch.nn.AvgPool2d 메서드를 활용하고자 한다.
 Pytorch라이브러리의 Pool2d메서드의 설명을 보면 입력되는 자료형은 Tensor자료형만 입력이 가능하며, 구조는 아래와 같아야 한다.
Pytorch라이브러리의 Pool2d메서드의 설명을 보면 입력되는 자료형은 Tensor자료형만 입력이 가능하며, 구조는 아래와 같아야 한다.

따라서 이미지를 불러오면
1) 이미지 -> Tensor자료형으로 차원변환
2) Pooling 연산 수행
3)다시 이미지(numpy 자료형)으로 복원
의 과정을 수행해야 한다.
import cv2
import torch
import torch.nn as nn
import numpy as np# MaxPooling 메서드 인스턴스화
max_pooling = nn.MaxPool2d(kernel_size=2)
# AveragePooling 메서드 인스턴스화
average_pooling = nn.AvgPool2d(kernel_size=2)
#nn.Pool2d 메서드는 기본적으로 stride = kernel_size이다.#이미지 불러오고 텐서 자료형 변환
img_file = '../00_pytest_img/opencv/mountain.jpg'
img = cv2.imread(img_file, cv2.IMREAD_GRAYSCALE)
#cv2.imread에서 cv2.IMREAD_GRAYSCALE옵션을 주면 img의 차원은 [H, W]만 남는다
print(img.shape) #[H = 700, W = 1024]# 이미지를 4차원의 Tensor자료형으로 변환 [N, C, H, W]
img_tensor = torch.tensor(img, dtype=torch.float32).unsqueeze(0).unsqueeze(0)
print(img_tensor.shape) #[1, 1, 700, 1024]# 풀링 레이어 정의 ()
max_pooling = nn.MaxPool2d(kernel_size=2)
average_pooling = nn.AvgPool2d(kernel_size=2)
# 풀링 연산 적용
max_pooled_tensor = max_pooling(img_tensor)
avg_pooled_tensor = average_pooling(img_tensor)
# 결과를 시각화하기 위해 numpy 배열로 변환
max_pooled_img_np = max_pooled_tensor.squeeze().numpy()
avg_pooled_img_np = avg_pooled_tensor.squeeze().numpy()
#squeeze()메서드는 크기가 1인 차원은 모두 제거한다
#따라서 [N, C, H, W]에서 N, C가 1이니 이를 제거한 [H, W]만 남는다
#이후 Tensor자료형을 numpy.array 자료형으로 변환한다.
# float32 데이터 타입을 uint8 범위로 변환 (0-255)
max_pooled_img_np = np.clip(max_pooled_img_np, 0, 255).astype(np.uint8)
avg_pooled_img_np = np.clip(avg_pooled_img_np, 0, 255).astype(np.uint8)
print(max_pooled_img_np.shape) #[H, W]
print(avg_pooled_img_np.shape) #[H, W]위 코드에서 Img -> Tensor -> Pooling cal -> Img의 일련의 자료형+차원변환에 관련된 실습이 중요하며,
 실행 결과는 앞서 설계한
실행 결과는 앞서 설계한 Avg_pool2d, Max_pool2d와 동일한 결과를 도출한다.
