
마지막 세 번째 알고리즘 시험을 보는 날이 되었다. 이제는 내가 선택한 주특기를위해 따로 공부하는 1주일을 보내게 될 것이다. 비록 1주일이라는 짧은 시간이었지만 그래도 꾸준히 알고리즘을 공부하는 것은 그래도 의미있는 시간이었다고 생각한다. 물론 앞으로도 알고리즘은 계속 공부할 것이긴 하지만 온전히 알고리즘을 공부하는 데에만 시간을 보낸 것은 처음이기에 더 기억에 남을 듯 하다.
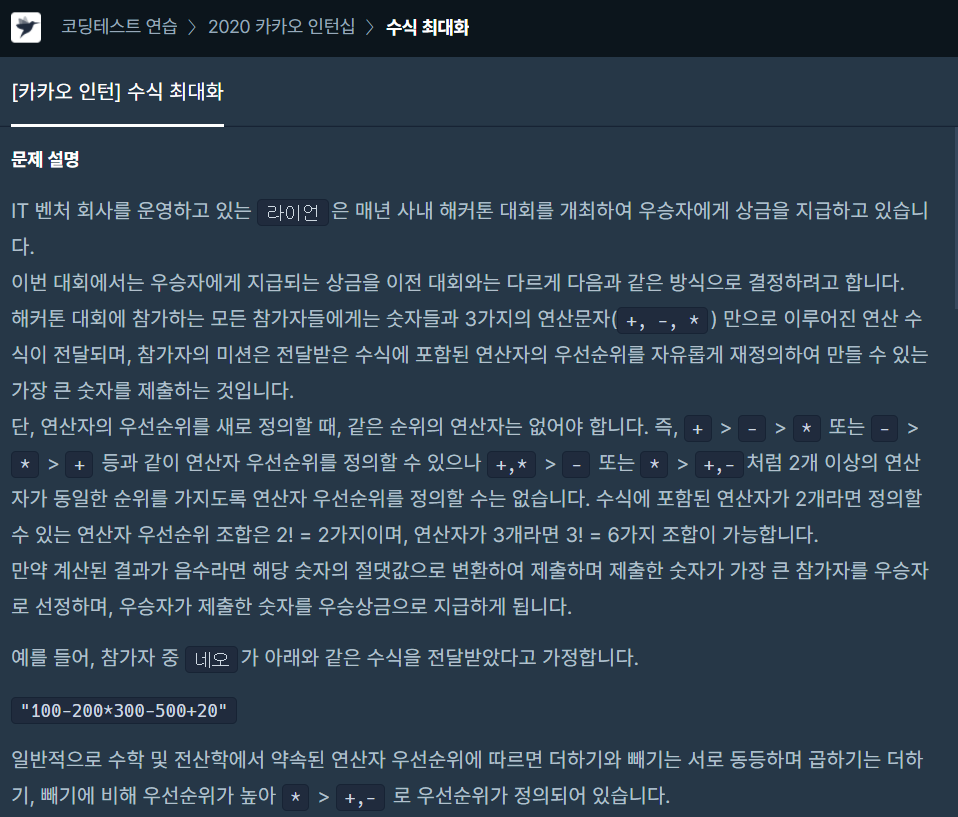
문제에서 구하는 것
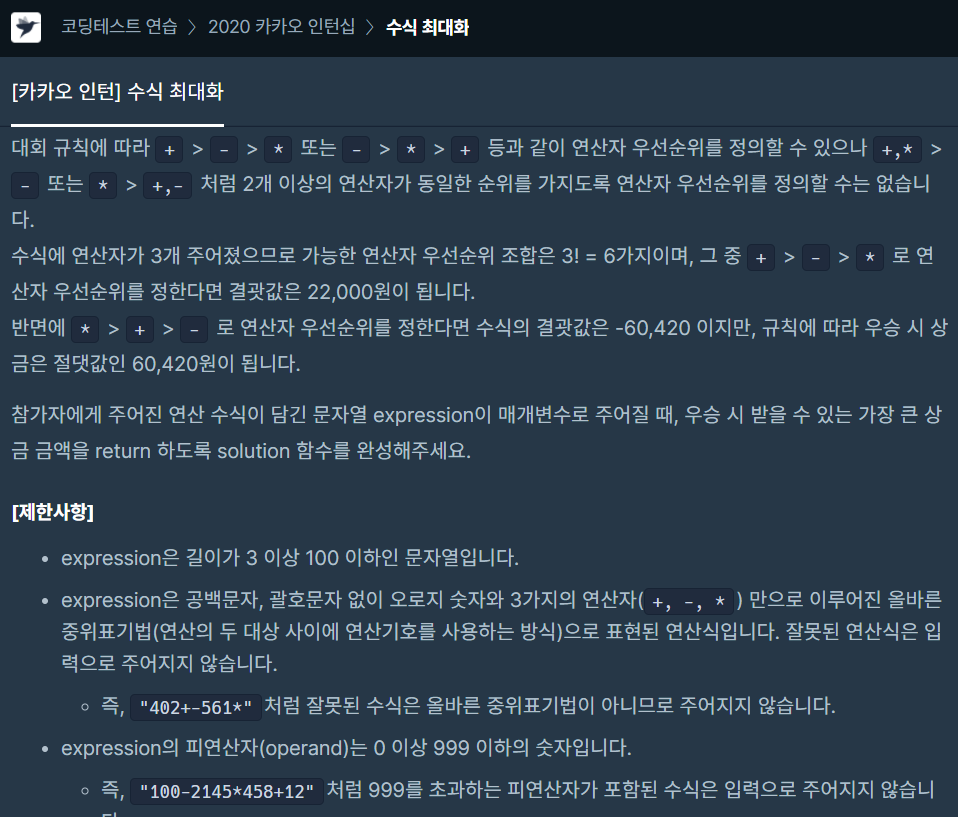
연산자의 우선순위를 새로 정의해서 만들 수 있는 가장 큰 상금 금액의 절댓값. * 를 해야 가장 크지 않을까 생각했으나, 입출력 예시를 보면 아닌 경우도 있기에 일반적인 규칙은 없는 듯함.
▶ 따라서, 이런 경우에는 우선 순위의 모든 경우를 다 해봐야함.
생각해보면 *, + , - 이 3가지를 순서를 바꿔봤자 어차피 6가지 밖에 없기 때문에, 이 경우들을 모두 시도해서 expression 을 계산한 뒤에 가장 절댓값이 큰 값을 반환해주면 됨.
* > + > - , * > - > + , + > * > - , + > - > *, - > * > +, - > + > *
☝ 구현하기 전에, 알고 있으면 조금 더 좋은 코드를 만들기 위한 선행 개념
1. 순열
2. 정규표현식
1. 순열
* > + > - , * > - > + , + > * > - , + > - > *, - > * > +, - > + > *
위처럼 순서가 부여된 임의의 집합. 즉, 순열이 있음. 파이썬에서는 순열을 쉽게 만들 수 있는 방법이 있는데 바로 itertools 라는 라이브러리를 이용하는 것.
다음과 같이 모든 경우의 수를 쉽게 구할 수 있음.
from itertools import permutations
operation_list = ["*", "+", "-"]
operation_permutations = list(permutations(operation_list))
print(operation_permutations) # [('*', '+', '-'), ('*', '-', '+'), ('+', '*', '-'), ('+', '-', '*'), ('-', '*', '+'), ('-', '+', '*')]2. 정규표현식
expression 을 보면 다음과 같이"100-200*300-500+20"로 되어 있는데 이 문자열에서 문자와 연산자를 구분해야 함.
문자열을 돌면서 - * + 중 하나를 뽑아서 나눌수도 있는데 이런 작업을 하려면 여러줄의 반복문과 분기문이 필요할 것.
문자열을 보면서 숫자가 나오지 않을 때까지 탐색 길이를 늘리고, 연산자가 나올 때까지 탐색한다. 라는 코드를 작성해야 하기 때문임.
이 긴 요구사항을 단 한 줄로 표시하는 방법이 정규표현식. 정규 표현식은 문자열에 나타나는 특정 문자 조합과 대응시키기 위해 사용되는 패턴으로 주로 문자열의 검색과 치환을 위한 용도로 쓰이고 있음.
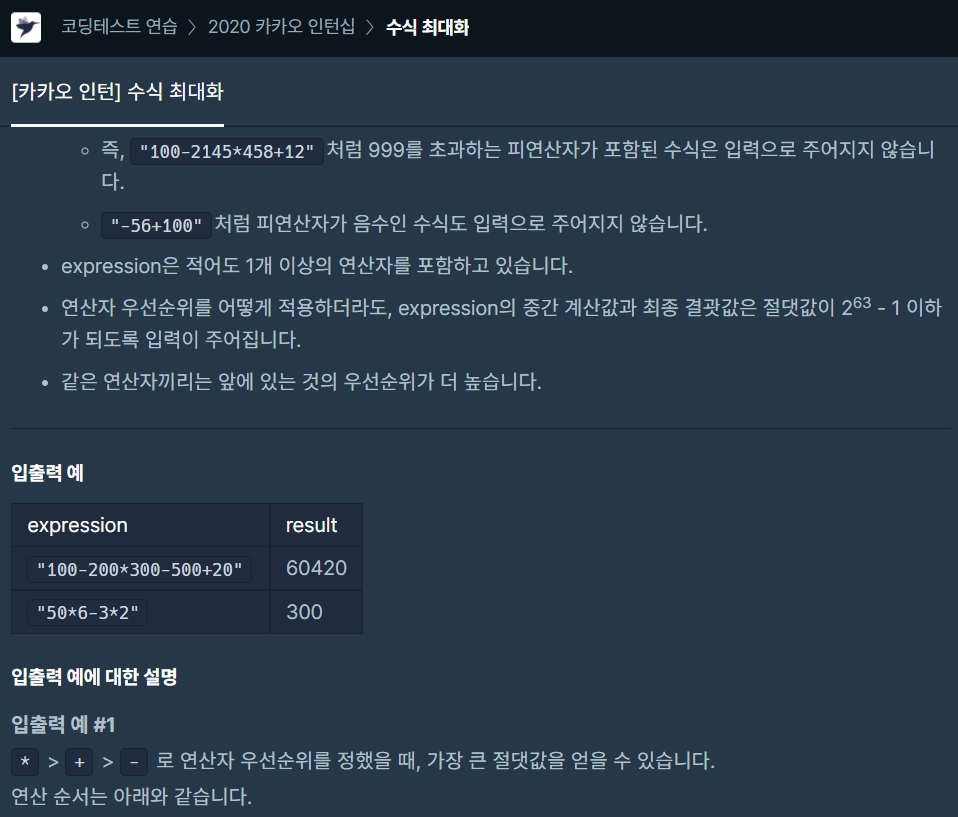
▶ 우선 반환해 줘야 하는 것 : 연산자의 우선순위를 새로 정의해서 만들 수 있는 가장 큰 상금 금액의 절댓값이므로 answer = 0 을 만들어서 반환해 줄 것.
def solution(expression):
answer = 0
return answer그리고 itertools 를 이용해서 순열을 만들어 줌.
from itertools import permutations
def solution(expression):
answer = 0
operation_list = ["*", "+", "-"]
operation_permutations = list(permutations(operation_list))
return answer순열이 준비가 되면, 정규표현식을 이용해서 expression 을 숫자와 연산자로 분리해 주는데 re 라는 모듈을 가져와서, 다음과 같이 코드를 작성.
참고 : [^0-9] 는 0~9를 제외한 문자 하나를 찾는 다는 의미로 * 이나 + 이나 - 를 찾을 수 있으며 그 기준으로 입력된 문자열을 잘라 배열에 저장하게 됨.
import re
from itertools import permutations
def solution(expression):
answer = 0
operation_list = list()
if '*' in expression:
operation_list.append('*')
if '+' in expression:
operation_list.append('+')
if '-' in expression:
operation_list.append('-')
operation_permutations = list(permutations(operation_list))
expression = re.split('([^0-9])', expression)
return answer👉 이제 각각의 연산자 우선순위에 따라 연산값이 얼마가 나오는지 파악하고, 그 연산값 중 절댓값이 가장 높은 경우의 값을 반환하면 됨. 이를 위해서 연산자의 우선순위 순열에서 하나의 값을 뽑고, 그 순열에서 정해진 순서대로 계산을 진행하면 됨.
import re
from itertools import permutations
def solution(expression):
answer = 0
operation_list = list()
if '*' in expression:
operation_list.append('*')
if '+' in expression:
operation_list.append('+')
if '-' in expression:
operation_list.append('-')
operation_permutations = list(permutations(operation_list))
expression = re.split('([^0-9])', expression)
for operation_permutation in operation_permutations:
for operator in operation_permutation:
# ????
return answer👉 계산을 하는 방법은 다양한 방법들이 있을 수 있지만, 여기서는 계산할 때마다 기존 계산식에 있는 연산자와 숫자를 제거하는 방식으로 진행할 것.
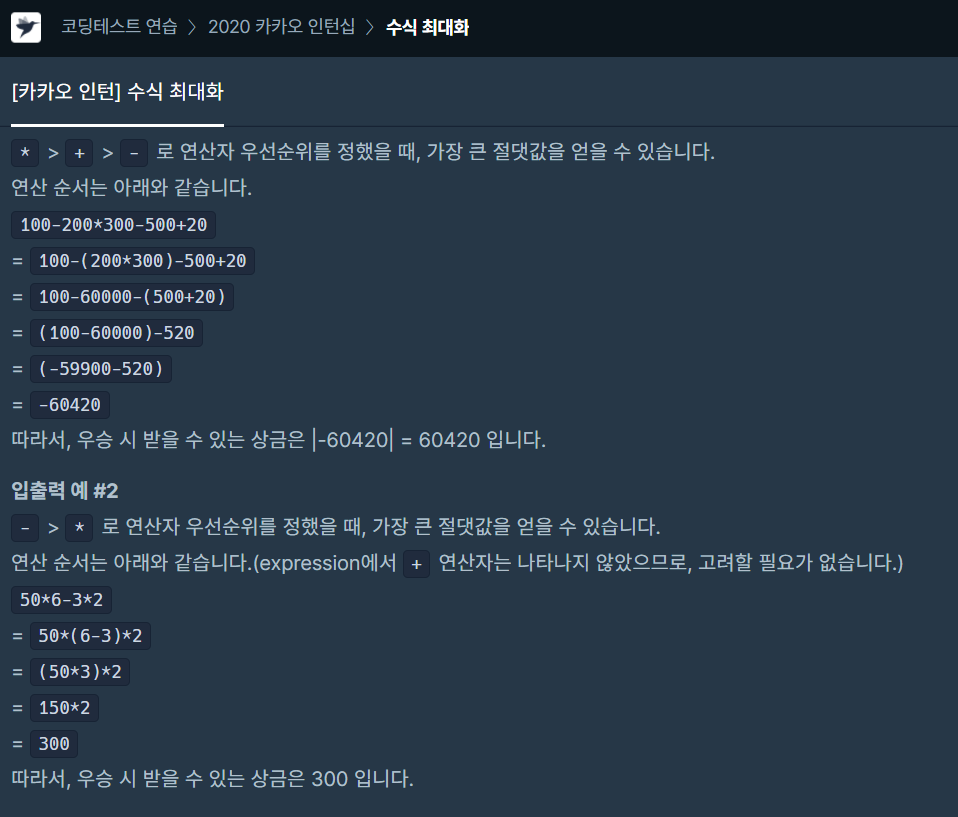
예를 들어 "100-200*300-500+20" 라는 입력값이 들어왔을 때, 연산자 우선순위가 * > + > - 라고 한다면 다음과 같이 연산할 것임.
1) 우선 [*]를 찾음.
2) [*] 기준으로 앞 뒤의 숫자들을 연산한 뒤 연산 결과를 제외한 연산자와 숫자들은 제거함.
3) 그리고 다시 [*]를 찾고, 없다면 다음 연산자를 찾음.
1) 런타임의 값들로 보면, 현재 expression 변수가 다음과 같이 되어 있음.
["100", "-", "200", "*", "300", "-", "500", "+", "20"]
2) 여기서 [*] 를 찾고 앞 뒤에 있는 문자열인 "200"과 "300"을 연산하면 숫자 60000이 됨.
3) 그리고 "200", "*", "300"을 없애고 60000을 넣으면 expression 변수가 다음과 같이 되어 있음. ["100", "-", "60000", "-", "500", "+", "20"]
3) 이제 다음 연산자인 +로 다시 반복.
위의 작업을 진행하려면, 우선 기존 expression 배열을 복사해야 하며 왜냐면 우리는 연산한 작업을 하면서 배열을 잘라서 붙이는 작업을 해야 하기 때문에 원본 배열이 아닌 복사된 배열로 연산 작업을 한다는 것.
따라서 copied_expression 을 만든 후, 현재 가장 높은 우선순위의 연산자가 해당 표현식에 있을 때까지 반복함. 해당 연산자와 앞 뒤의 숫자들을 기준으로 연산을 할 예정이고 어떤 연산을 하는지는 연산자의 내용에 따라서 달라잠. 여기서는 이렇게 if 문을 사용하도록 구현했으나, 다른 방식으로 구현이 가능함.
import re
from itertools import permutations
def solution(expression):
answer = 0
operation_list = list()
if '*' in expression:
operation_list.append('*')
if '+' in expression:
operation_list.append('+')
if '-' in expression:
operation_list.append('-')
operation_permutations = list(permutations(operation_list))
expression = re.split('([^0-9])', expression)
for operation_permutation in operation_permutations:
copied_expression = expression[:]
for operator in operation_permutation:
while operator in copied_expression:
op_idx = copied_expression.index(operator)
if copied_expression[op_idx] == "*":
cal = int(copied_expression[op_idx - 1]) * int(copied_expression[op_idx + 1])
elif copied_expression[op_idx] == "+":
cal = int(copied_expression[op_idx - 1]) + int(copied_expression[op_idx + 1])
elif copied_expression[op_idx] == "-":
cal = int(copied_expression[op_idx - 1]) - int(copied_expression[op_idx + 1])
return answer👉 자 이제 3번째 단계인 연산자와 앞 뒤의 숫자를 없애고 결괏값을 배열에 넣어야 함.
즉, ["100", "-", "200", "*", "300", "-", "500", "+", "20"]
op_idx 라고 한다면,
["100", "-", "200", "*", "300", "-", "500", "+", "20"]
op_idx - 1 에 60000을 넣고
["100", "-", "60000", "*", "300", "-", "500", "+", "20"]**
여기까지의 배열과 여기까지의 배열을 합치는 것인데 그렇게 되면 연산에 사용된 값들과 연산자는 제거되기 때문임.
import re
from itertools import permutations
def solution(expression):
answer = 0
operation_list = list()
if '*' in expression:
operation_list.append('*')
if '+' in expression:
operation_list.append('+')
if '-' in expression:
operation_list.append('-')
operation_permutations = list(permutations(operation_list))
expression = re.split('([^0-9])', expression)
for operation_permutation in operation_permutations:
copied_expression = expression[:]
for operator in operation_permutation:
while operator in copied_expression:
op_idx = copied_expression.index(operator)
cal = str(
eval(copied_expression[op_idx - 1] + copied_expression[op_idx] + copied_expression[op_idx + 1])
)
**copied_expression[op_idx - 1] = cal
copied_expression = copied_expression[:op_idx] + copied_expression[op_idx + 2:]**
return answer그리고 나서 copied_expression 의 첫번째 원소를 뽑는데 이는 모든 연산이 끝났다면 전부 계산이 완료되어서 하나의 원소값만 가지고 있을 것이기 때문임. 따라서 이 값과 answer 를 비교해서 가장 큰 값만 남도록 하면, 연산자의 우선순위를 새로 정의해서 만들 수 있는 가장 큰 상금 금액의 절댓값을 구할 수 있게 된 것임.
import re
from itertools import permutations
def solution(expression):
answer = 0
operation_list = list()
if '*' in expression:
operation_list.append('*')
if '+' in expression:
operation_list.append('+')
if '-' in expression:
operation_list.append('-')
operation_permutations = list(permutations(operation_list))
expression = re.split('([^0-9])', expression)
for operation_permutation in operation_permutations:
copied_expression = expression[:]
for operator in operation_permutation:
while operator in copied_expression:
op_idx = copied_expression.index(operator)
cal = str(
eval(copied_expression[op_idx - 1] + copied_expression[op_idx] + copied_expression[op_idx + 1])
)
copied_expression[op_idx - 1] = cal
copied_expression = copied_expression[:op_idx] + copied_expression[op_idx + 2:]
answer = max(answer, abs((int(copied_expression[0]))))
return answer이 문제에서 사용되는 개념인 순열과 정규표현식을 알면 문제를 더욱 수월하게 풀 수 있었음. 그러나 이런 개념들이 중요한 것은 아니고, 문제의 요구사항을 분석해서 구현해나가는 과정이 더욱 중요함.
