학부 시절 구현해보았던 CAM.
다시 한 번 구현해보았다.
이게 뭐라고 그렇게 어려워했을까?
CAM, GRAD CAM을 지나 GAIN을 구현하고자 함.
Learning Deep Features for Discriminative Localization - 논문 링크
CAM-github
1. 설명 가능한 AI(Explainable AI, XAI)
기존의 AI는 블랙박스라는 이야기가 많았다. 이는 특정한 판단에 대해 모델을 제안한 사람도, 코드를 짠 사람도 설명할 수 없는 이유에서 였다. 이러한 우려는 인공지능이 성장해감에 따라 커졌을 것이라 생각한다.
초기 우편번호 분류, 차량 번호판 인식 등 간단한 문제를 풀기 위해 적용되었을 때와 달리 자율 주행, 자동 수술 등 섬세하고 인간의 안전과 생명에 영향을 미치는 문제에도 ai가 자리를 차지하기 시작하면서 AI에 대한 우려가 커졌다. AI가 이런 핵심적인 영역에서 내린 결정의 근거와, 그 타당성을 제공하지 못 하고 있다는 이유에서다.
이에 따라 XAI에 대한 관심이 커졌다. 이를 통해 AI의 판단 결과를 논리적으로 설명하는 것이 가능해졌기 때문이다.
컴퓨터 비전의 XAI 모델 중 하나인 CAM에 대해 얘기하고, 구현한 코드를 공유하려 한다.
2. CAM
CAM이란 CNN이 입력으로 들어온 이미지를 분류할 때 "어떤 부분을 보고" 예측을 했는지를 알려주는 역할을 한다. 아래 사진을 보면 이해가 쉬울 것이다. 입력 이미지에 히트맵을 씌워 주어진 단어를 예측하는 데에 있어 중요한 부분에 가까워질수록 가시광선의 파장에서 파란색에서 빨간색(온도가 높은 = 활성화가 많이 된 = 중요도가 높은)으로 변해감을 확인할 수 있다.

기본적인 아이디어는 다음과 같다.
CNN으로 이미지 분류를 할 때 마지막 단의 출력값이 클수록 softmax를 거친 뒤 1에 가까워 지는데, 그렇다면 입력 이미지의 label에 해당하는 채널마지막 conv layer의 출력이 크게 하는 클래스에 크게 반응했단 거겠지?
위의 발상에 따라 예측한 클래스에 해당하는 Linear layer의 weight을 가져온 뒤 heatmap을 그려 "과연 어떤 부분을 보고 이런 예측을 한 걸까?"에 대해 답을 주는 그림이 바로 CAM(Class Activation Map)이다.
이런 걸 하는 친구인데, 코드를 보자!
3. 코드 설명
1. 필요한 모듈을 가져온다.
import torch
from torchvision import models
from torchvision import datasets
from torchvision import transforms
from torch.utils.data import DataLoader
from torch import optim
from torch import nn
from torch.nn import functional as F
import matplotlib.pyplot as plt
import numpy as np2. 필요한 모듈을 가져온다.
- 처음부터 필요한 걸 생각해서 이렇게 한 번에 적는 사람도 있을까? 예쁘게 torch 관련 모듈만 묶어놓은 걸 볼 수 있지만, 사실 생각나서 쓸 때마다 하나씩 추가했다 ㅎㅎ
class vgg_cam(nn.Module):
def __init__(self, features, num_classes, init_weights=True):
super(vgg_cam, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classfier = nn.Linear(512, num_classes)
def forward(self, x):
x = self.features(x)
map = x
x = self.avgpool(x)
x = torch.squeeze(x)
x = self.classfier(x)
return x, map3. vgg_cam 모델을 선언한다.
- 저 features는 뭐야? 라고 물어보려고 하는 당신! 좋은 지적이다.
- 이는 사실 별로 좋은 방법은 아닌 것 같은데.. pytorch 공식 도큐먼트에서 vgg 시리즈를 선언할 때 사용한 방법이다.
class VGG(nn.Module):
def __init__(
self,
features: nn.Module,
num_classes: int = 1000,
init_weights: bool = True
) -> None:
super(VGG, self).__init__()
self.features = features
# 중략
cfgs: Dict[str, List[Union[str, int]]] = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg16(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
r"""VGG 16-layer model (configuration "D")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`._
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg16', 'D', False, pretrained, progress, **kwargs)- 보이는가? cfgs dictionary를 선언해두고, 거기서 layer 정보를 불러온다는 것이!
- 조금 얍삽하지만, 이를 사용하기로 했다.
- 내가 선언한 클래스에서 features를 어떻게 가져왔는지? 이건 다음 코드에 나온다.
4. cam 모델 생성
vgg16 = models.vgg16(pretrained=True)
features = vgg16.features
model = vgg_cam(features=features,
num_classes = 10,
init_weights=True)
PATH = '/content/drive/MyDrive/vgg_cam.pth'
model.load_state_dict(torch.load(PATH))- vgg16을 가져온 뒤 거기서 features 부분만을 떼오는 방식으로 짠 건데..
- 분명 나쁜 코드다. 이건 고쳐야 하는 게 맞고, 하지만 직접 선언하면 pretrained model의 weight를 가져올 수 없으니, 상속 받아 forward부분만 수정해주는 게 맞겠다.
<All keys matched successfully>- 이는 앞서 학습해놓은 vgg_cam 모델의 가중치를 불러왔는데, 그게 잘 됐다는 뜻이다.
5. 데이터 로더 생성
- ImageNet을 너무나도 사용하고 싶었지만, 이제 url을 통해 다운로드 하는 방식은 막혔으니 직접 다운 받으라는 말에 포기했다.
- CIFAR10이라는 데이터셋을 대신 사용했는데, 이는 10개의 클래스를 가지고 32 * 32의 shape을 가지는 3채널 RGB이미지를 클래스 당 5000장 가지고 있다.
- 모델의 성능보다는 CAM을 그려보고 싶은 것이므로, augmentation은 해주지 않았다.
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
])
train_dataset = datasets.CIFAR10(root='./', train=True, transform=transform, download=True)
test_dataset = datasets.CIFAR10(root='./', train=False, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
len_train = len(train_loader) # to be used for logging loss
len_test = len(test_loader) # to be used for logging loss6. 모델 device할당 및 hyper parameter 설정
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
epochs = 10- 제곧내!
- 흔하게 쓰이는 CrossEntropyLoss와 SGD를 각각 loss function과 optimizer로 사용하였다.
7. 학습
for epoch in range(epochs):
train_loss = 0
test_loss = 0
for data_, target_ in train_loader:
data = data_.to(device)
target = target_.to(device)
output_, _ = model(data)
output = torch.squeeze(output_)
optimizer.zero_grad()
loss = criterion(output, target)
train_loss += loss.item()
loss.backward()
optimizer.step()
print("{}epoch train loss : {}".format(epoch + 1, round(train_loss / len_train, 2)))
for data_, target_ in test_loader:
data = data_.to(device)
target = target_.to(device)
output_, _ = model(data)
loss = criterion(output, target)
test_loss += loss.item()
print("{}epoch test loss : {}".format(epoch + 1, round(test_loss / len_test, 2)))- 학습시키는 과정이다.
- 해보면 알겠지만, 잘 됐다.
8.CAM!
- 드디어 본론이다.
- 여기서 할 일을 크게 보면 아래와 같다.
1. 우선 cam_vgg에 이미지를 하나 넣어준 뒤 conv layer의 마지막 단에 의해 활성화된 feature map을 가져온다. 이는 512 7 7의 shape을 가진다.
2. 512 10의 shape을 가지는데 label의 index에 해당하는 값만 가져온다.(=512 1)
3. 1에서 나온 feature map과 2에서 얻은 벡터를 channelwise로 곱해준다.
4. 3에서 512 7 7의 shape을 가지는 텐서를 얻을 수 있는데, 이를 7 7 의 shape을 가지도록 sum해준다. - 큰 과정은 위와 같은데, 이에 해당하는 코드를 순서대로 따라가보겠다.
8 - 1. 모델의 forward에서 값을 얻는다.
img = test_dataset[0][0]
label = test_dataset[0][1]
batch_img = img[None, :, :, :].to(device)
x, map = model(batch_img)- test_dataset의 첫 번째 사진을 모델에 넣어주고 512 1 1 tensor와 512 7 7 feature를 받는다.
- x는 위 설명에 없는 output으로, classification에 사용됐다. 이는 10 1의 shape을 가지는데, logit 처럼 사용된다.
- map은 512 7 7 의 shape을 가지는 feature map으로, 위 설명의 1에 해당된다.
8 - 2. feature map과 class weight의 곱을 구한다.
class_weight = model.classfier.weight[int(label)].unsqueeze(-1).unsqueeze(-1)
cam_ = torch.squeeze(map) * class_weight-
512 10의 크기를 가지는 nn.Linear에서 입력 이미지의 라벨에 해당하는 벡터를 빼온 뒤, 이를 8-1에서 구한 map과 channel wise로 곱해준다.
-
코드 설명을 해보자면, class_weight은 512의 shape을, map은 512 7 7 의 shape을 가진다.
-
이를 channelwise로 곱해주려면 class_weight을 512 1 1 의 shape을 가지게 해주어야 했고, 두 번의 unsqueeze를 통해 shape을 맞추어주었다.
8 - 3. 512 channel의 성분을 모두 더해준다.
cam = torch.sum(cam_, axis=0)
cam = cam.detach().cpu().numpy()
# print(cam.shape) # DEBUG- 512 7 7 의 shape을 가지는 tensor cam_을 axis=0을 주고 sum해주면 7 7 shape으로 싹 더해진다. 이게 cam!
- 해당 텐서를 numpy로 바꾸어주었다.
9 .결과
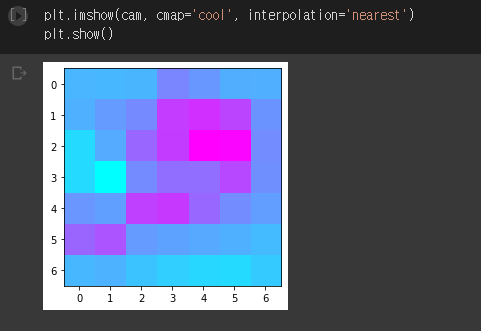
- heatmap을 뽑아보았다.
- shape이 7 7 이므로 해상도가 많이 떨어져보인다.
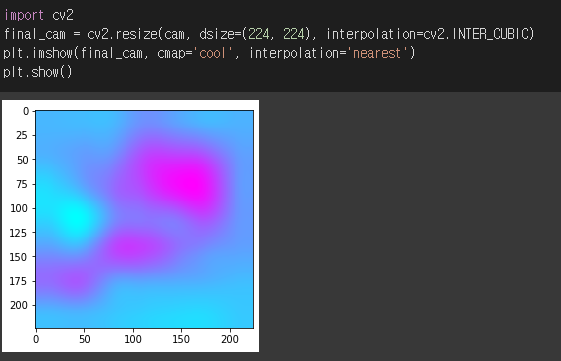
- 이를 224, 224로 resize한 뒤, interpolation해주었다.
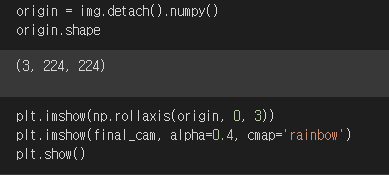
- tensor로 뽑힌 img를 numpy로 바꿔준 뒤, shape을 뽑아보니 앞서 dataloader를 구성할 때 설정해준대로 잘 되었음을 확인할 수 있다.
- 이를 앞서 만들어준 CAM과 하나의 figure에 같이 출력해주면..

- 이렇게 되는 걸 볼 수 있다.
5. 고찰
- 아쉬운 점은 이미지를 너무 키워(49배나 키웠으니..) 해상도가 많이 떨어진다는 점이다.
- 또 조언을 받은대로 상속받아 모델을 작성하지 않고 야매로 했다는 점이 좀 걸리는데, 이는 우선 미뤄두고 다음 코드를 짜겠다.
- 다음 코드는 CAM의 상위 호환, Grad-CAM이다.
- 간단하게 작성해보기 좋은 코드이니, 조금 어려워보이더라도 논문과 도큐먼트, 각종 커뮤니티에 질문을 구해가며 코드를 짜보자.
- 사실 구글에 CAM을 치면 정말 많이들 구현해두신 것을 확인할 수 있다.
- 그렇지만 나같이 못 짜는 사람도 헤매면서 짜보니 이틀만에 짰는데, 구현된 것을 보지 않아도 분명 나보다 빨리 짤 수 있을 것이라 생각한다.
- 도움을 받은 오픈채팅방이 있는데 바로 PyTorchKR이다.
- 친절하게 질문을 받아주신 덕분에 오랜 시간 걸리지 않아 코드를 구현할 수 있었다.
6. reference
1. 설명 가능한 인공지능(XAI), 왜 주목하나?
2. Learning Deep Features for Discriminative Localization
3. torchvision.models.VGG
