
이번 게시물에서는 제가 파이썬을 공부하면서 자주 등장하고 저에겐 생소했던 iterable,iterator와 generator에 대해서 정리해보려고합니다.
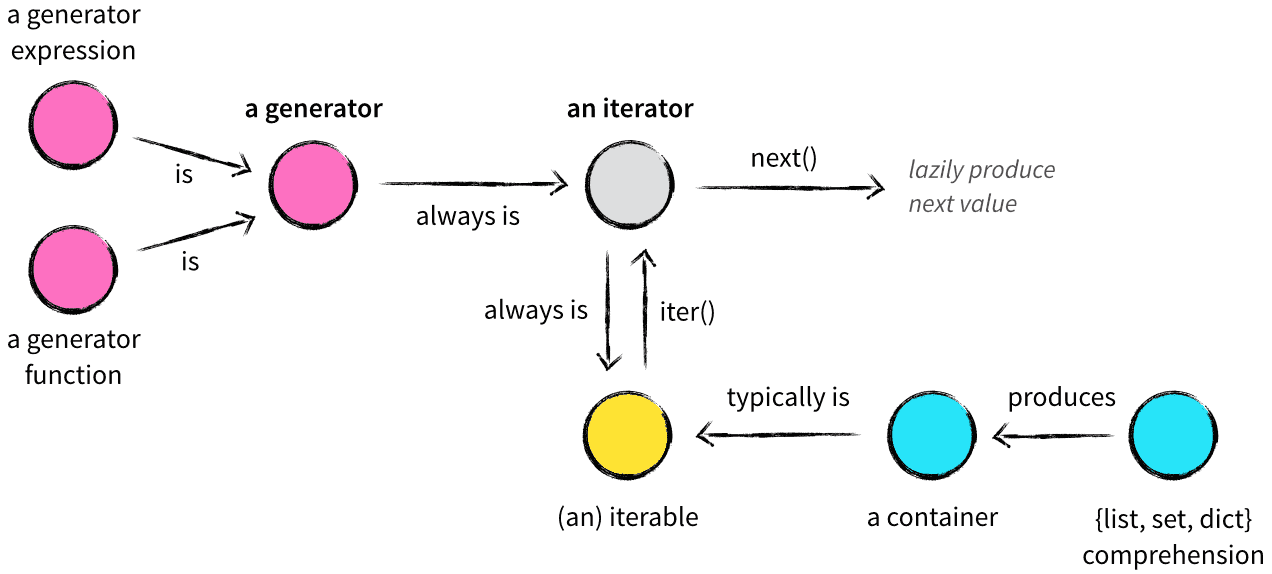 이미지 출처: https://nvie.com/posts/iterators-vs-generators/
이미지 출처: https://nvie.com/posts/iterators-vs-generators/
이 그림은 앞으로 소개할 개념들을 간단하게 정리한 이미지입니다. 지금은 이해가 하나도 안되겠지만 이 게시글을 다 읽으면 모든 것을 선명하게 이해하게 될 겁니다.
1. Container
Container란 영어 그대로 무엇을 담은 것을 나타냅니다. 물건을 담아 운송하는 컨테이너를 생각하면 쉽게 이해할 수 있습니다.
Container는 데이터를 담아두는 자료구조입니다.
list처럼 안에 여러개의 데이터를 담을 수 있는 객체들이 바로 Container입니다.
Container는 시퀀스형과 비시퀀스형 두가지로 나눌 수 있습니다.
시퀀스형 컨테이너는 list, str처럼 순서가 있는 자료구조를 말합니다.
즉 index가 가능합니다.
비시퀀스 컨테이너는 set이나 dict처럼 순서가 없는 자료구조를 뜻합니다.
즉 index가 불가능합니다.
여기까지 설명을 들으면 비시퀀스형은 for문이 사용이 불가 할것 같지만 그것은 아닙니다.
비시퀀스형 컨테이너는 순서가 없지만 for문안에 사용은 가능합니다.
비시퀀스형 컨테이너는 순서가 없기 때문에 사용될때마다 그 안의 요소들의 무작위로 순서로 반환됩니다.
로또통을 생각해보면 이해가 쉬울 것 같습니다. 로또통에는 매주 다른 번호를 가진 동일한 갯수의 공들이 있지만 추첨을 할때마다 그 순서가 달라지는 것과 같습니다. (모든 공들을 뽑든다는 가정)
이를 아래의 예제로 실제로 어떻게 출력되는지 확인해봅시다.
a = {"B","a","e","t","c","h"}
print(a)
#1.출력
{'h', 't', 'a', 'c', 'e', 'B'}
#2.출력
{'a', 'h', 'c', 't', 'B', 'e'}
#3.출력
{'h', 'B', 't', 'a', 'e', 'c'}이처럼 set을 print할 때마다 다른 값을 출력한 다는 것을 확인 할 수 있습니다.
정리하자면
시퀀스형: 순서가 있는 데이터 (ex. list, tuple, str)
- 인덱싱이 가능하다.
비시퀀스형: 순서가 없는 데이터 (ex. set, dict)
- 인덱싱이 불가능하다.
- 하지만 요소를 차례로 접근할 수는 있다. (실행할 때마다 다른 순서)
2. Iterable
iterate는 반복이라는 뜻을 가지고 있습니다.
그렇다면 iterable은 반복할 수 있는 것을 나타낸다고 유추할 수 있습니다.
iterable은 반복할 수 있는 객체를 말합니다.
좀 더 자세히 말하자면
반복이 가능한 즉 iterate over가 가능한 객체를 말합니다. 여기서 iterate over이 가능하다는 것은 요소들을 한 번에 하나씩 돌려줄 수 있는 객체를 말합니다.
즉 iterable은 그 곳에 들어있는 것을 하나씩 꺼낼수 있는 것이라고 생각하면 됩니다.
그렇기에 for문에 사용할 수 있는 객체라고 생각하면 이해가 쉽습니다.(list,str,set,dict)
정확하게 iterable한지 알고 싶다면 해당 객체에 __iter__메소드가 있는지 확인하면 됩니다.
myset = {"B","a","e","t","c","h"}
mylist = [1,2,3,4]
mydict = {'name':'bae','age':25}
myint = 150
print(hasattr(myset,"__iter__"))
print(hasattr(mylist,"__iter__"))
print(hasattr(mydict,"__iter__"))
print(hasattr(myint,"__iter__"))
#출력
True
True
True
False이처럼 list,set,dict은 __iter__메소드가 있기 때문에 iterable입니다.
반면에 int는 그렇지 않기에 iterable하지 않습니다.
그렇다면 이 __iter__는 대체 뭘까요.
__iter__메소드는 객체를 iterator로 반환해주는 메소드입니다.
그럼 __iter__메소드가 있으면 왜 iterable일까요.
그 이유는 iterable은 iterator를 생성할 수 있는 모든 것을 뜻하기 때문입니다.
iterable은 iterator을 반환하는 객체
아니 아까는 iterable이 반복할 수 있는 객체 어쩌고 하더만 갑자기 iterator를 반환하는 객체라니 이게 무슨 소리인가 싶죠? 이는 iterator를 이해하면 반복할 수 있다는 게 iterator를 반환하는 것과 같은 의미인 걸 알 수 있게 될겁니다.
iterator란 단어가 나와서 당황스러울 수 있지만 iterator에 대해선 다음 문단에서 자세히 다룰 예정이므로 여기선 iterator가 뭔진 모르겠지만 iterable은 iterator가 될 수 있나보다 정도만 이해하시면 됩니다.
3. Iterator
iterator이란 값을 순서대로 반환 할 수 있는 객체입니다.
여기까지 설명하면 iterable과 뭐가 다른가 싶지만 둘은 다릅니다.
iterator는
next()함수로 다음 값을 호출 해야만 다음 값을 반환하는 객체입니다.
list와 같은 iterable은 처음부터 끝까지의 값들을 생성해 놓는거와 상반되는 특징입니다.
iterator는 모든 데이터 값들을 모두 생성해 놓고 있지 않습니다. next()을 통해 다음 값만을 불러올 뿐입니다.
예를들어 iterable과 iterator를 출력하고 싶다고 한다면
iterable의 경우 가지고 있는 모든 요소들을 생성해놓기 때문에 한번에 출력이 가능하지만 iterator는 next()함수를 통해 그 안의 요소 하나씩 접근하여 출력하게 됩니다.
또한 iterable은 재사용이 가능하지만 iterator는 재사용이 불가합니다.
iterator는 마지막 요소까지 사용하면 그 뒤 새로 선언하지 않는 한 재사용을 할 수 없습니다.
두 특성을 예를 들어 좀 더 쉽게 이해해봅시다.
1부터 5까지의 카드가 있다고 생각해봅시다. 이 카드들은 각 카드의 숫자대로 순서가 존재합니다.

이 카드들은 숫자가 보이고 당신은 이 카드들을 모두 한번에 볼 수 있습니다.
그리고 당신은 이 각 카드을 사용 하고 제자리에 돌려 놓습니다. 5번 카드까지 사용하고 나서도 또 같은 사이클을 도는 것이 가능합니다. 즉 재사용이 가능합니다. 이것은 iterable입니다.
이번에도 똑같이 5장의 카드가 있습니다. 하지만 이번엔 딜러가(iterator) 카드를 모두 가져가고 요청하면 하나씩 주겠다고 합니다.
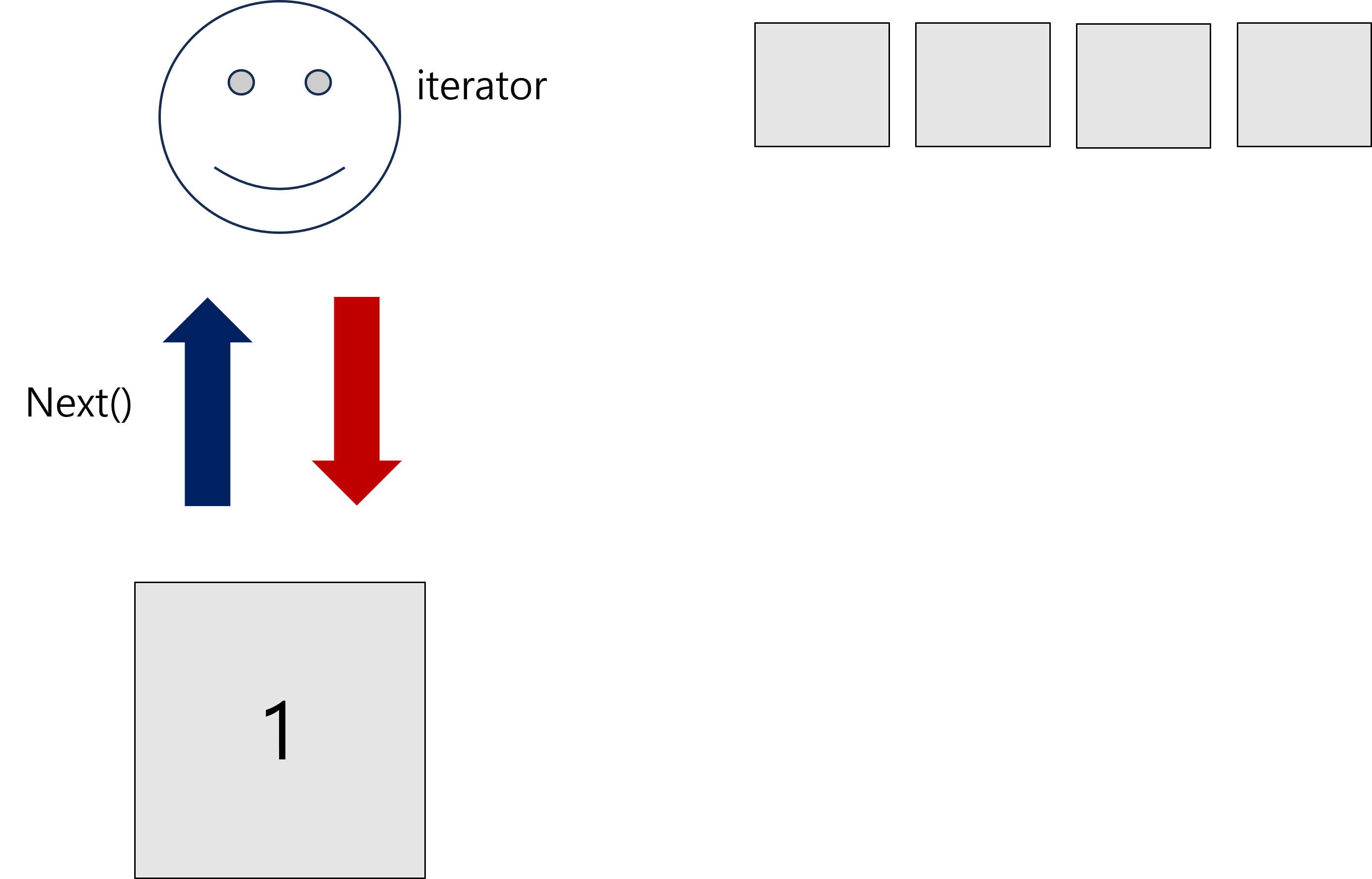
당신이 딜러한테(iterator) 다음 카드를 달라는 요청(next())를 하면 딜러는 카드를 한 장씩 당신에게 줍니다.
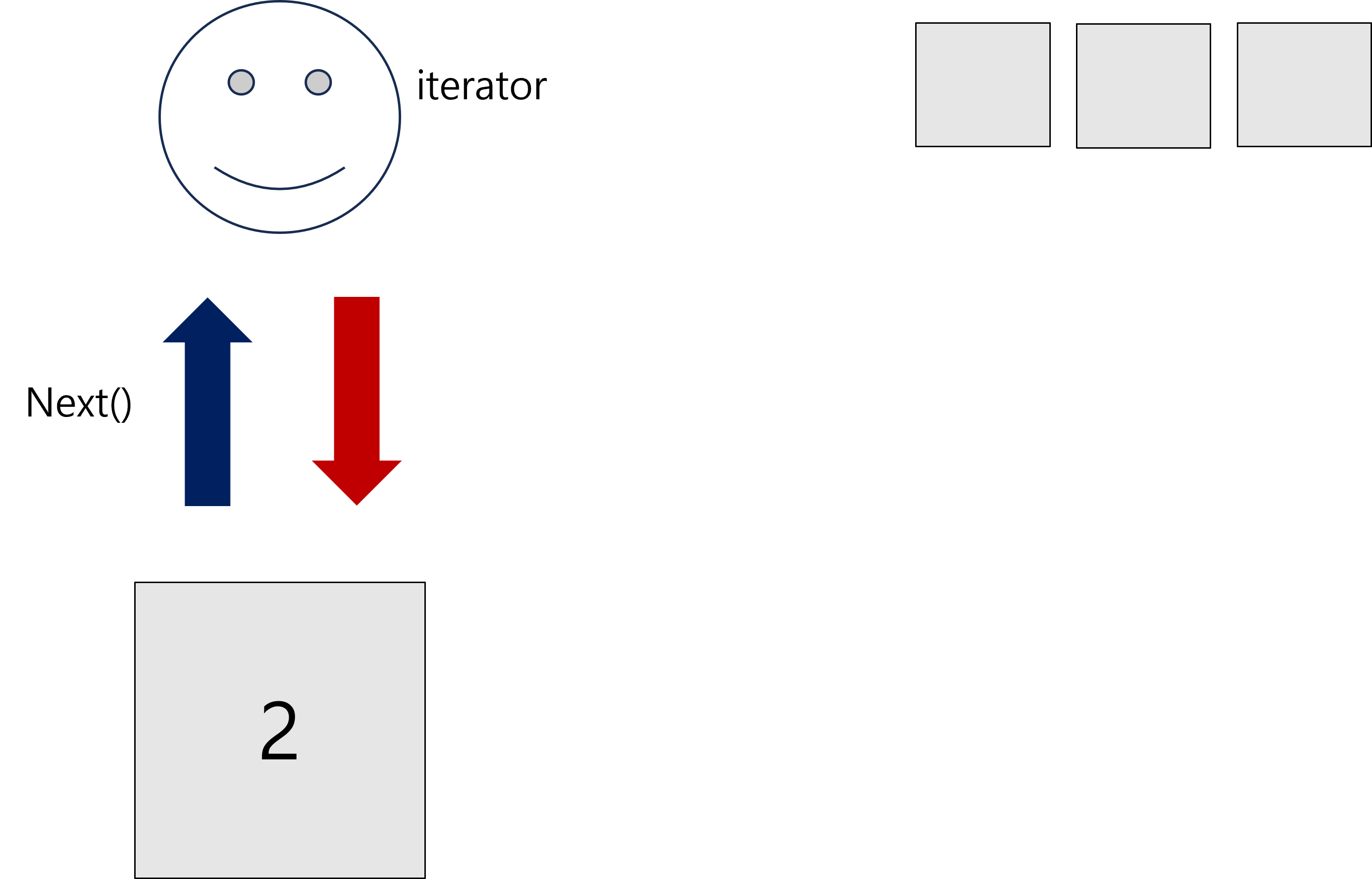
두번째 카드도 같은 방법으로 가져오면 전에 가져왔던 카드는 버려져 더 이상 사용할 수 없게 됩니다.
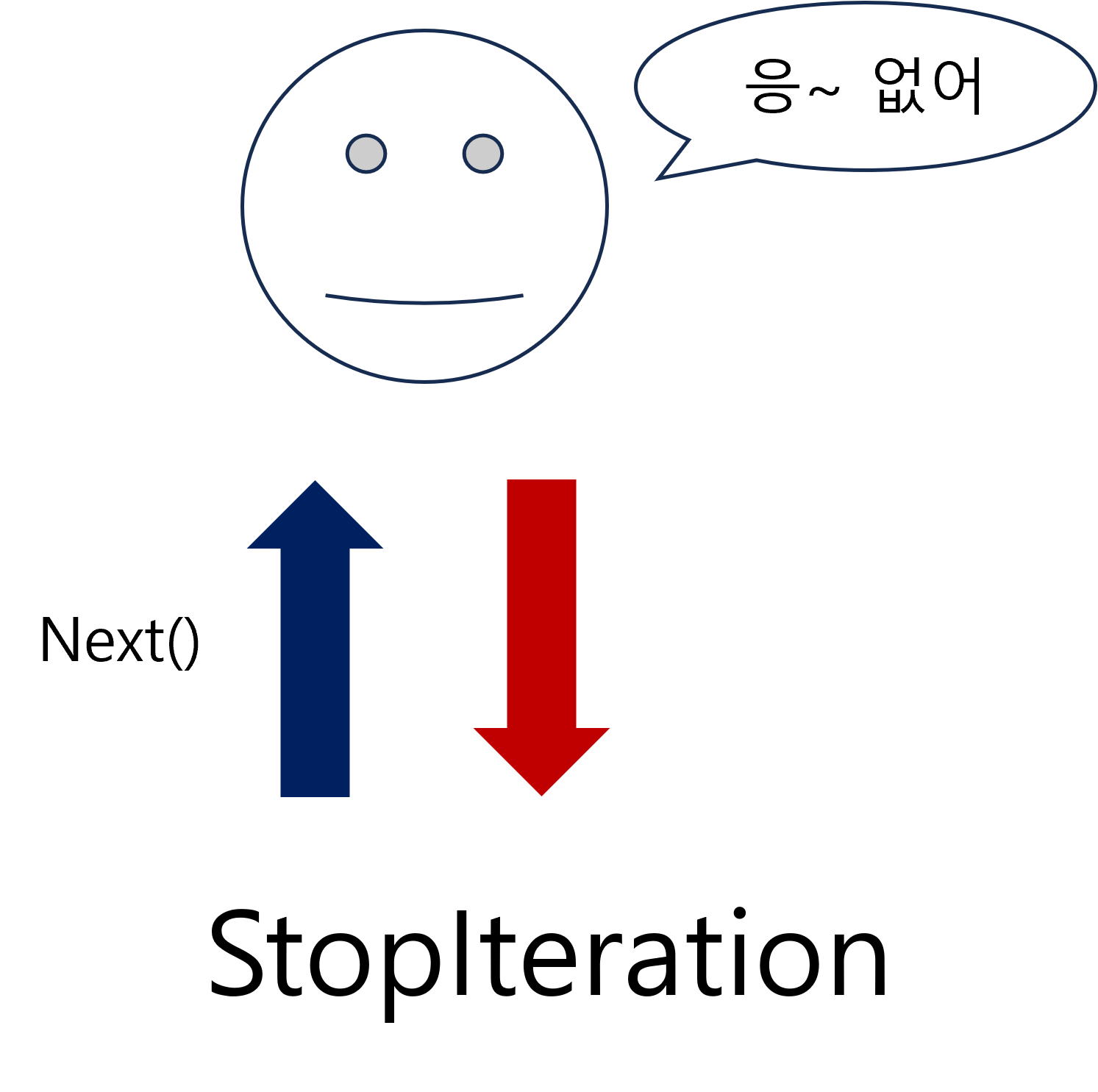
이 과정을 반복하다가 더 이상 다음 값이 없는 순간이 오면 iterator는 StopIteration이라는 예외를 발생시킵니다.
또한 전에 사용 했던 카드들(값들)은 소비되었기 때문에 더 이상 요청할 수 없습니다. 즉 재사용을 하지 못합니다.
정확한 예가 아닐 수 있지만 iterable과 iterator의 차이를 대충은 이해가 되었기를 바랍니다.
그렇다면 이 iterator는 어떻게 생성할 수 있을까요?
iterable을 설명할 때 iterable은 iterator가 될 수 있다고 했습니다.
iterable은
iter()를 사용하여 iterator를 반환 할 수 있습니다.
이제 iterator를 만드는 방법도 알았으니 직접 코딩으로 이를 좀 더 알아봅시다.
우선 iter()를 사용해서 실제로 iterator를 만들어 보겠습니다.
mylist = [1,2,3,4,5]
myiter = iter(mylist)
print(type(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
print(next(myiter))
#출력
<class 'list_iterator'>
1
2
3
4
5
Traceback (most recent call last):
, line 12, in <module>
print(next(myiter))
^^^^^^^^^^^^
StopIteration위 코드에선 mylist에 iter()를 사용하고 타입을 확인하니 iterator로 반환 되었다는 것을 확인할 수 있습니다.
그 뒤 next()를 사용하여 myiter의 값들을 하나 씩 호출하고 더 이상 불러올 값이 없을 때 StopIteration이 발생하는 것도 확인할 수 있습니다.
계속해서 이번엔 위에서 설명한 iterator의 재사용이 불가하다는 특징을 직접 코딩을 통해 보여드리겠습니다.
mylist = [1,2,3,4,5]
myiter = iter(mylist)
def recycle(num, what):
for i in range(num):
print(f'{i+1}번째 for')
for j in what:
print(j,end=' ')
print("\n")
recycle(3,mylist)
#출력
1번째 for
1 2 3 4 5
2번째 for
1 2 3 4 5
3번째 for
1 2 3 4 5
recycle(3,myiter)
#출력
1번째 for
1 2 3 4 5
2번째 for
3번째 for위 코드에서 recycle함수는 for문을 몇 번 반복할지 결정하는 매개변수 num와 무엇을 for문에 사용하는 지를 결정하는 매개변수인 what을 가지고 있습니다.
nums에 3을 인수로 설정했기에 for문은 세 번 반복실행 됩니다.
위에서 볼 수 있듯이 iterable인 리스트를 사용하면 첫번째 for문으로 모든 요소를 사용 했음에도 for문은 다시 실행할때마다 리스트의 요소들을 계속 불어와 출력합니다. 즉 재사용이 가능합니다.
반면에 iterator인 myiter를 for문에 사용하면 첫번째 for문을 사용했을 때만 값들이 출력되고 그 다음에 for문에 다시 사용하게 되면 아무런 값도 출력하지 않습니다. 즉 재사용이 불가합니다.
근데 뭔가 이상하지 않습니까? 분명 위에서는 iterator는 next()를 통해서만 값들을 하나씩 불러올 수 있다고 했는데 위 코드에서는 next()를 사용하지도 않았는데 iterator의 값들을 불러왔습니다.
그 이유는 for문은 next()함수를 자동으로 호출해 사용하기 때문입니다.
아래에서 자세히 설명하겠습니다.
x = [1,2,3]
for i in mylist:
print(i)
위의 for문을 실행시키면 아래 그림과 같은 일이 일어납니다.
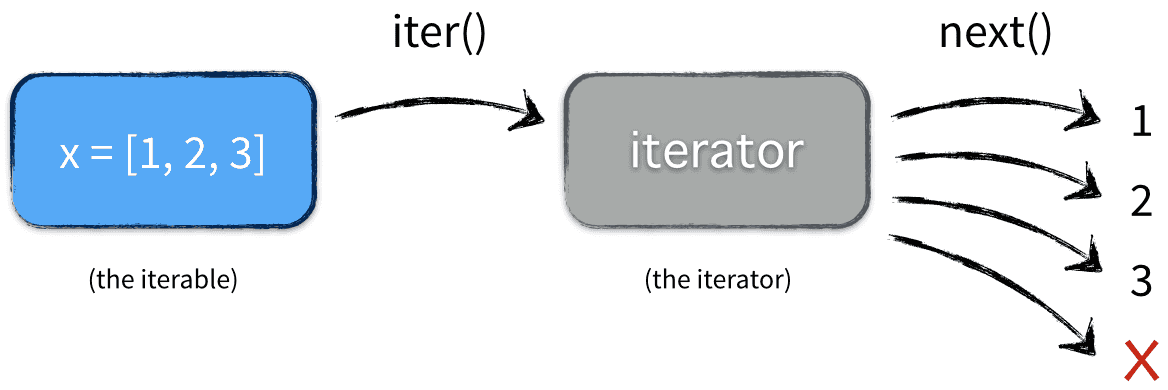
for문은 iterable을 사용해야하는 것을 기억하고 있을겁니다.
for문은 내부에서 iter()를 통해 iterator를 반환해 사용 하기 때문에 그렇습니다.
위의 for문을 실행할때 일어나는 일을 while을 사용해 표현하면 아래와 같습니다.
x = [1,2,3]
it = iter(x)
while True:
try:
i = next(it)
except StopIteration:
break
else:
print(i)for문은 실행되면 위와 같은 단계를 거쳐 실행됩니다.
1. iterable을 iter()를 사용해 iterator로 반환합니다.
2. 그후 하나씩 next()를 사용하여 값을 하나씩 가져와 사용합니다.
3. 더 이상 가져올 값이 없으면 StopIteration이 발생합니다.
결론적으로 for문은 자동으로 iterable을 iterator로 반환 후 next()함수를 호출하여 사용합니다.
iterator를 간단하게 정리하면 아래와 같습니다.
-
iterator객체는
next()함수를 통해 값을 차례대로 꺼낼 수 있는 객체입니다.- 더 이상 불러올 수 있는 요소가 없으면
StopIteration이라는 예외 발생
- 더 이상 불러올 수 있는 요소가 없으면
-
iterator는 "소비"됩니다. 그렇기 때문에 재사용이 불가능 합니다.
(위 예에서 확인한 카드를 버리는 것) -
iterator한 객체를 내장함수 또는
iterable객체의 메소드(__iter__)로iterator를 반환 할 수 있습니다.
4. Generator
generator는 제가 공부하면서 도대체 iterator와 뭐가 다른지 이해가 힘들었던 개념입니다. 제가 이해한대로 정리를 해보겠습니다. 사실 이 글의 위에 있는 iterable이나 iterator는 generator를 이해하기 위한 초석입니다. 실제로 개발을 할 때 generator가 더 자주 더 실용적으로 사용이 가능해 보입니다.
generator는 iterator 기능을 가지는 함수나 수식입니다.
generator는 보다 세련된 iterator입니다.
(단 반대는 성립하지 않습니다.)
이 두 설명이 당장은 이해가 되지 않을 수 있습니다.
하나씩 자세히 설명드리겠습니다.
4.1 generator 함수
generator 함수는 크게 두 가지로 그 자체로 generator인 함수와 yield키워드를 사용하여 직접 만드는 함수가 있습니다.
대표적으로 enumerate()나 zip()같은 함수는 그 자체로 generator함수입니다. 이 글에선 enumerate()를 예로 설명하겠습니다.
enumerate함수는 iterable한 객체의 인덱스와 값을 함께 반환하는 함수입니다.
좀 더 자세히 알고 싶다면 전에 작성한 게시글이 있으니 확인하시면 도움이 될 겁니다.
[Python] enumerate에 관하여
enumerate는 인덱스와 해당 값을 iterator로 반환합니다. 그래서 enumerate함수가 generator함수인 것이죠. 아래의 코드로 알아봅시다.
mylist = ['a','b','c','d']
enum = enumerate(mylist)
print(next(enum))
#출력
(0, 'a')이처럼 enumerate는 iterator를 반환하므로 next()를 통해 다음 값으로 접근이 가능합니다.
enumerate함수처럼 iterator를 생성하는 함수는 그 자체로 generator함수입니다.
반면에 yield키워드를 사용하여 generator함수를 직접 만들 수 있습니다.
그럼 yield는 무엇일까요.
yield라는 영단어는 '양보하다'의 뜻이 있습니다.
yield 키워드는 해당 키워드 라인을 실행하고 함수를 호출한 쪽으로 프로그램의 제어를 양보합니다. 솔직히 와닿진 않죠? 먼저 예제로 천천히 알아보도록 합시다.
def number_generator():
yield 0 # 0을 함수 밖으로 반환하고 호출한 쪽으로 코드 실행을 양보
yield 1 # 1을 함수 밖으로 반환하고 호출한 쪽으로 코드 실행을 양보
yield 2 # 2을 함수 밖으로 반환하고 호출한 쪽으로 코드 실행을 양보
gen = number_generator()
a = next(gen) #yield를 사용하여 함수 바깥으로 전달한 값은 next로 반환됨.
print(a)
b = next(gen)
print(b)
c = next(gen)
print(c)
#출력
0
1
2위 코드처럼 함수 내에서 yield키워드를 사용하면 값을 함수 바깥으로(호출한 쪽) 전달하고 코드 실행을 양보합니다. 즉 yield는 현재 함수를 잠시 중단하고 함수 바깥의 코드가 실행되도록 합니다.
위의 코드를 그림으로 살펴보겠습니다.
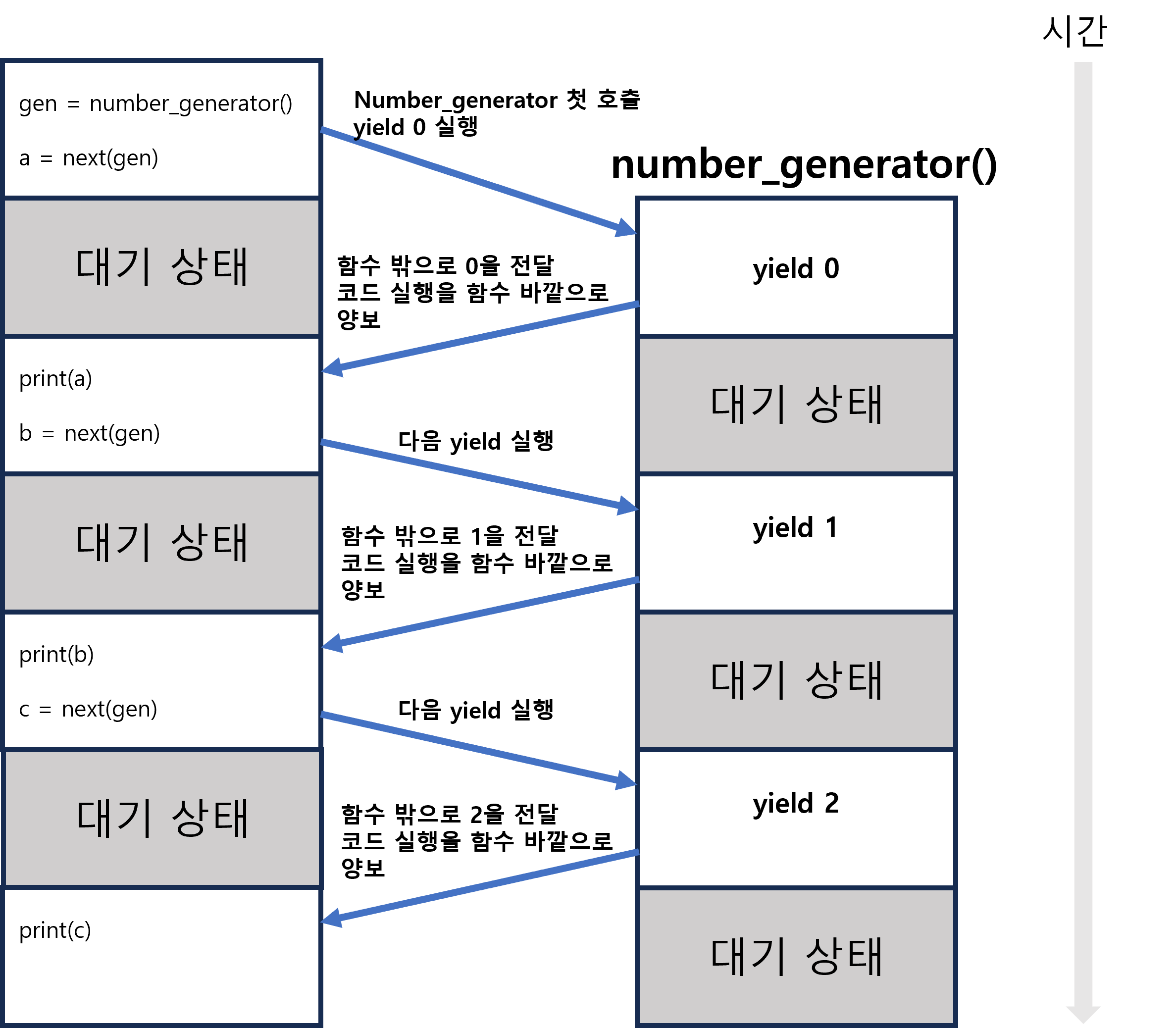
위 그림처럼 next(gen)으로 number_generator함수의 yield를 실행하면 값을 함수의 바깥으로 전달하고 함수는 다음 실행이 있을 때까지 대기상태가 됩니다. 이를 반복하는 것이 yield의 동작과정입니다.
yield의 값은 next()로 반환되는 iterator의 기능을 가지고 있기 때문에 generator함수 인 것 입니다.
이처럼 yield키워드를 사용하여 간단하게 함수를 generator함수로 만들어 사용할 수 있습니다.
4.2 generator수식: Generator Expresstions
저번 for문 게시글에서 list comprehension(리스트 내포)에 대해서 알아봤었습니다.
이 list comprehension과 generator expresstions(generator 수식)은 닮은 점이 많으니 아래 링크로 list comprehension을 이해하고 오시면 도움이 될 겁니다.
파이썬 반복문 관하여(for, while)
list, set, dict comprehension과 generator expresstions는 구조가 동일합니다. 그러나 차이는 []와 {}을 쓰느냐 ()을 쓰느냐고 생성하는 값의 type이 다릅니다. 결론적으로 list comprehension은 이름처럼 list을 반환하고 generator expresstions는 generator를 반환합니다.
※ ()를 쓴다고 tuple comprehension이라고 오해하면 안됩니다.(그런거 없습니다.)
먼저 list comprehension을 통해 20까지의 짝수의 리스트를 생성해보겠습니다.
list_odd = [x for x in range(20) if x%2 == 1]
print(list_odd)
#출력
[1, 3, 5, 7, 9, 11, 13, 15, 17, 19]generator expresstions으로도 동일한 값을 가진 generator을 만들 수 있다.
gen_odd = (x for x in range(20) if x%2 == 1)
print(next(gen_odd))
print(list(gen_odd))
#출력
1
[3, 5, 7, 9, 11, 13, 15, 17, 19]list comprehension과 다르게 generator expresstions는 generator이므로 next()를 통해 첫번째 값에 접근하고 그 뒤에 list을 사용해서 전체 값을 받아올 때는 처음 값을 제외하고 반환하는 걸 볼 수 있다.
그렇다면 list comprehension과 generator expresstions의 차이는 무엇일까요. 반환하는 것이 다르지만 그것만 다르다면 generator expresstions을 굳이 써야하는 이유는 무엇일까요.
list(set, dict) comprehension은 list 즉 iterable한 객체를 반환합니다. 즉 모든 값들을 전부 생성합니다.
이에 반해 generator expreestions은 generator 반환합니다. 즉 값을 하나씩 요청이 있을 때만 생성합니다.
이러한 특징은 데이터가 대용량일 경우 매우 효율적으로 사용이 가능합니다. 왜 그럴까요?
코드로 직접 비교해보겠습니다.
import sys
gen = (i ** 2 for i in range(100000) if i % 3 == 0 or i % 5 == 0)
print(sys.getsizeof(gen))
li = [i ** 2 for i in range(100000) if i % 3 == 0 or i % 5 == 0]
print(sys.getsizeof(li))
#출력
200
394968위 코드에선 sys.getsizeof()를 이용해서 동일한 데이터를 생성하는 list comprehension과 generator expresstions의 크기를 비교했습니다.
보시다시피 generator expresstions는 크기가 200, list comprehension은 크기가 394968입니다.(단위는 bite)
list comprehension은 수식에 해당하는 모든 데이터를 계산해 생성하기 때문에 크기가 큽니다.
generator expresstions는 요청이 오기 전에는 계산을 진행하지 않기 때문에 매우 크기가 작은 것 입니다.
그렇다면 속도는 어떨까요. 이젠 generator의 특성을 알기 때문에 예측할 수 있을 겁니다.
아래 코드로 비교해보겠습니다.
import cProfile
cProfile.run('sum((i ** 2 for i in range(10000000) if i % 3 == 0 or i % 5 == 0))')
cProfile.run('sum([i ** 2 for i in range(10000000) if i % 3 == 0 or i % 5 == 0])')
#출력
""" 4666672 function calls in 2.913 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
4666668 1.938 0.000 1.938 0.000 <string>:1(<genexpr>)
1 0.000 0.000 2.912 2.912 <string>:1(<module>)
1 0.000 0.000 2.913 2.913 {built-in method builtins.exec}
1 0.974 0.974 2.912 2.912 {built-in method builtins.sum}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
4 function calls in 1.530 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 1.356 1.356 1.530 1.530 <string>:1(<module>)
1 0.000 0.000 1.530 1.530 {built-in method builtins.exec}
1 0.175 0.175 0.175 0.175 {built-in method builtins.sum}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} """generator expresstions가 list comprehension에 비해 모든 값은 합치는(sum)의 실행시간이 두배 정도 느리게 결과가 나왔습니다. 이젠 왜 이런 결과가 나왔는지 짐작이 됩니다. generator는 값을 next()를 통해 하나하나 불러와 계산해야 하기 때문에 모든 데이터를 생산해 놓는 list와 속도가 차이가 나는 것 입니다.
단, 이것은 가용메모리에 비해 데이터의 양이 적을 때 해당됩니다. 가용메모리보다 크기가 큰 데이터를 다룰 땐 list를 사용조차 하지 못하기 때문입니다.
정리하자면
- 수식의 결과 크기는 list comprehension보다 generator expresstions가 훨씬 작다.
- 데이터의 크기가 상대적으로 작을 때 실행시간은 list comprehension가 더 빠를 수 있다.
이젠 우리가 이러한 generator의 특징들을 생각해보면 이를 왜 사용하면 좋은지 사용해야 할 땐 언젠지 알 수 있습니다.
데이터가 너무 많거나 심지어 무한할 때(데이터의 크기가 가용메모리보다 클 때)나 데이터가 실시간으로 계속 생성되는 경우에 사용하기 좋습니다. 요즘 저는 빅데이터에 관심이 많은데 왜 데이터업종에서 python이 사용되는지 알 수 있었습니다.
4.3 지연평가(Lazy evaluation/loading)
지연평가? 왜 이렇게 번역을 했는지 모르겠지만 지연계산이라고 이해하면 좋습니다.
근데 말이죠 우리는 이미 이걸 알고 있습니다. generator를 이해했다면 말이죠.
일단 사전적 의미부터 보여드리겠습니다.
컴퓨터 프로그래밍에서 느긋한 계산법(Lazy Evaluation)은 계산의 결과 값이 필요할 때까지 계산을 늦추는 기법이다.
느긋하게 계산하면 필요없는 계산을 하지 않으므로 실행을 더 빠르게 할 수 있고, 복합 수식을 계산할 때 오류 상태를 피할 수 있고, 무한 자료 구조를 쓸 수 있고, 미리 정의된 것을 이용하지 않고 보통 함수로 제어 구조를 정의할 수 있다.
generator를 설명하면서 주구장창 얘기한 특징이죠? 어느정도 이해가 되실 겁니다.
계산 방식에는 크게 두 가지가 있습니다.
- list comprehension처럼 모든 계산을 해 모든 데이터를 생산하는 방식 (Eager evaluation/loading)
- generator처럼 요청이 있을 때만 계산을하는 지연계산 (Lazy evaluation/loading)
사실 이에 대해선 위에서 많이 설명을 했기 때문에 이 단원은 용어소개에 가깝습니다.
요청이 있을 때만 계산(lazy evaluation) 하고 메모리에 할당(lazy loading)이라고 하는구나만 아시면 됩니다.
예를들어 일반적인 comprehension은 식을 모두 한번에 계산하고 이를 메모리에 미리 모두 할당합니다.
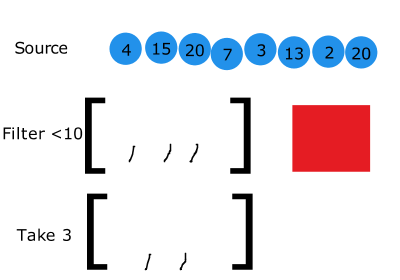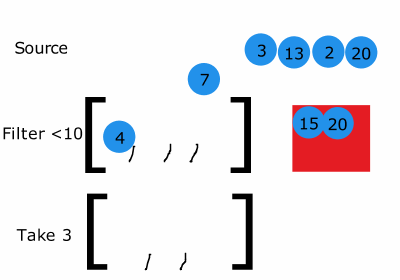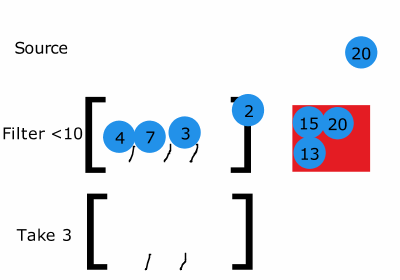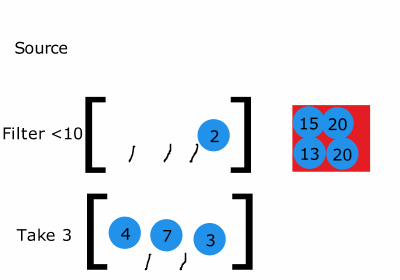 이미지 출처:http://filimanjaro.com/blog/2014/introducing-lazy-evaluation/
이미지 출처:http://filimanjaro.com/blog/2014/introducing-lazy-evaluation/
반면에 generator expresstions은 지정한 규칙과 어디까지 반환했는지 등을 관리하는 여러 상태값은 담고 있습니니다. 하지만 generator expresstions는 generator를 생성할 때 요청이 없다면 계산을 하지 않고 데이터를 메모리에 할당 하지 않습니다.
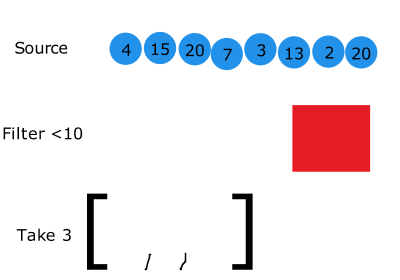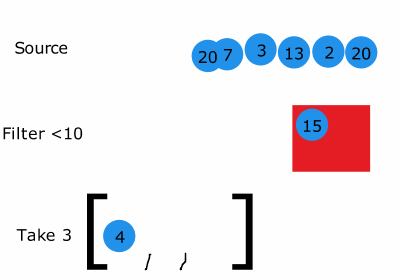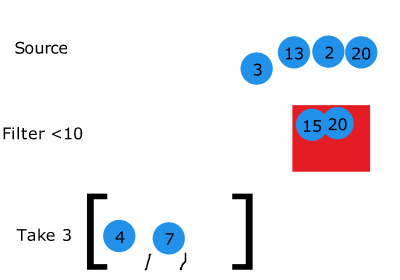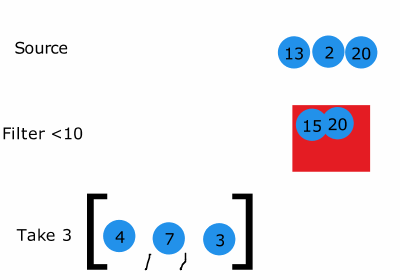
근데 한가지 생각해야 하는 것은 어떤 함수의 실행 시간을 측정할 때 만약에 그 함수가 generator라면 lazy-evaluation이 적용되기 때문에 측정된 결과가 그 함수에 적용된 알고리즘 고유의 수행시간(시간복잡도)가 아닐 수 있습니다.
정리하자면
lazy한 연산과 로딩을 하는 generator는 스트리밍 코드를 가능하게하고 거대한 데이트를 다룰 때 유용합니다. 게다가 메모리와 CPU의 효율이 좋습니다. 또한 코드의 길이도 줄여주는 효과가 있습니다.

글이 쉽게 읽히고 쉽게 설명해주셔서 감사합니다.