
백준문제를 풀때 정렬을 위해 sort()나 sorted() 사용할 일이 있다. 그 때마다 스스로 이 둘의 차이점과 사용법을 제대로 알지 못하는 거 같아서 이를 정리하여 게시해놓으려고 한다.
sort()
sort()의 기본문법은 아래와 같습니다.
<list>.sort(key = <function>, reverse = <bool>
- sort()는 기존의
list를 정렬합니다.list에만 사용 할 수 있습니다.key를 통해 정렬기준을 정합니다.reverse값이True면 내림차순,False은 오름차순입니다.
(기본값은False)
nums = [13,2,11,5,4,7,1]
nums.sort()
print("오름차순",nums)
nums.sort(reverse = True)
print("내림차순",nums)#출력
오름차순 [1, 2, 4, 5, 7, 11, 13]
내림차순 [13, 11, 7, 5, 4, 2, 1]위 코드에서 보이듯 sort()를 사용하면 원본 list가 정렬되어 수정됩니다.
sorted()
sorted()의 기본문법은 아래와 같습니다.
sorted(<iterable>, key = <function>, reverse = <bool>)
- 어떠한
iterable을 정렬된list로 새로 만듭니다. (새로 정의 or 출력 필요)- 모든
iterable에 사용이 가능합니다.key와reverse의 기능은 sort()의 것과 동일합니다.
nums = [13,2,11,5,4,7,1]
sorted_nums = sorted(nums)
print("sorted: ",sorted_nums)
print("original: ",nums)
#출력
sorted: [1, 2, 4, 5, 7, 11, 13]
original: [13, 2, 11, 5, 4, 7, 1]위와 같이 sorted()를 사용하면 새로운 정렬된 list가 생성되는 것을 알 수 있습니다.
sorted()는 sort()와 다르게 list뿐만아니라 모든 iterable에 사용이 가능합니다.
_dict = {5:'A', 13:"E", 1:"B", 3:"G", 12:"C"}
_set = set([5,13,1,3,12])
sorted_dict = sorted(_dict)
sorted_set = sorted(_set)
print("dict: ",sorted_dict)
print("set: ",sorted_set)#출력
dict: [1, 3, 5, 12, 13]
set: [1, 3, 5, 12, 13]key 매개변수
sort()와 sorted()모두 key매개변수를 사용하여 정렬 기준을 세울 수 있습니다.
key매개 변수에는 함수가 입력되어아하며 이 함수에 따라 정렬의 기준이 달라집니다.
보통 lambda를 많이 이용합니다.
lambda를 주로 많이 사용하지만 이를 사용하지 않는 예부터 살펴보겠습니다.
disorder = ["i'm","so","sorry","but","i","love","you"]
disorder.sort(key = len)
print(disorder)#출력
['i', 'so', "i'm", 'but', 'you', 'love', 'sorry']위와 같이 key에 len을 사용하면 글자 수를 기준으로 오름차순 되어 정렬됩니다.
len함수에 정렬할 리스트의 요소들이 하나씩 들어가 반환되는 값을 기준으로 정렬이 되는 것입니다.
lambda 사용하기
key매개변수는 함수를 입력해야하므로 lambda를 사용해 정렬기준을 정할 수 있습니다.
student = {"Kim":80, "Lee": 70, "Bae": 15, "Park": 60, "Oh": 0}
sorted_student_1 = sorted(student, key = lambda x : student[x])
sorted_student_2 = sorted(student.items(), key = lambda x : x[0]) #items는 (key,value)을 쌍으로 가져옵니다
sorted_student_3 = sorted(student.items(), key = lambda x : x[1])
reversed_student = sorted(student, key = lambda x : -student[x])
print(sorted_student_1)
print(sorted_student_2)
print(sorted_student_3)
print(reversed_student)#출력
['Oh', 'Bae', 'Park', 'Lee', 'Kim']
[('Bae', 15), ('Kim', 80), ('Lee', 70), ('Oh', 0), ('Park', 60)]
[('Oh', 0), ('Bae', 15), ('Park', 60), ('Lee', 70), ('Kim', 80)]
['Kim', 'Lee', 'Park', 'Bae', 'Oh']-
첫번째 예시는
key = lambda x : student[x]를 사용하여 딕셔너리의 value값을 비교하여 정렬된 key값을 가지는 리스트을 반환합니다. -
두번째 예시는
items()를 사용하여 key와 value를 쌍으로 가져와key = lambda x : x[0]을 통해 key값을 정렬기준으로 하고 이를 (key, value)리스트로 반환합니다. -
세번째 예시는 두번째와 비슷하지만
key = lambda x : x[1]을 통해 value값을 정렬기준으로 하고 (key, value)리스트로 반환합니다. -
마지막은 첫번째 예시에 마이너스 부호(-)를 사용하여 내림차순으로 정렬합니다.
(reverse = True와 동일)
다중조건 정렬
lambda를 이용해 정렬기준을 여러개로 설정할 수도 있습니다.
예를들어 나이와 이름이 기록된 명부 리스트가 있을때, 먼저 나이를 고려해서 정렬하고 만약 나이 같다면 이름 순대로 정렬해야 하는 경우 정렬기준을 튜플로 묶어 다음과 같이 설정하면 됩니다.
key = lambda x : (x[나이], x[이름])
people = {"Kim":54, "Lee": 25, "Bae": 25, "Park": 25, "Oh": 15}
sorted_people = sorted(people.items() , key= lambda x : (x[1],x[0]))
print(sorted_people)
#출력
[('Oh', 15), ('Bae', 25), ('Lee', 25), ('Park', 25), ('Kim', 54)]위 코드를 보면 나이를 기준으로 오름차순으로 정렬되어있고, 나이가 같은 Bae,Lee,Park는 이름을 기준으로 오름차순으로 정렬되었습니다.
안정 정렬
안정정렬이란 같은 값을 정렬할때 기존 위치를 유지하여 정렬하는 것을 의미합니다.
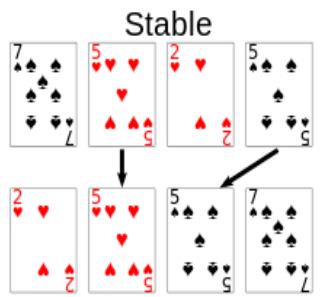
위 그림처럼 정렬이 안정적(Stable)하면 정렬하기 전의 중복된 값들의 위치가 정렬 후에도 유지됩니다.
(불안정하다면 기존의 위치의 유지가 보장되지 않습니다.)
sort()와 sorted()모두 정렬의 안정성(Stability)이 보장됩니다.
마지막으로 위의 그림을 직접 코딩해보며 이 글을 마치겠습니다. 감사합니다.
cards = [("♠",7),["♥",5],["♥",2],["♠",5]]
cards.sort(key = lambda x : x[1])
print(cards)#출력
[['♥', 2], ['♥', 5], ['♠', 5], ('♠', 7)]
쉽게 설명해두셨네요. 감사합니다.