데이터를 병렬로 처리하는 방법에는 크게 두 가지가 있다.
- 동기 훈련: 모든 worker 가 입력 데이터를 나누어 갖고 동시에 훈련, 각 단계마다 gradient 를 모음.
- 비동기 훈련: 모든 worker 가 독립적으로 입력 데이터를 사용해 훈련하고 비동기적으로 parameter 를 갱신
동기 훈련
All-Reduce Algorithm
내용 참고 : https://tech.preferred.jp/en/blog/technologies-behind-distributed-deep-learning-allreduce/
AllReduce is an operation that reduces the target arrays in all processes to a single array and returns the resultant array to all processes.
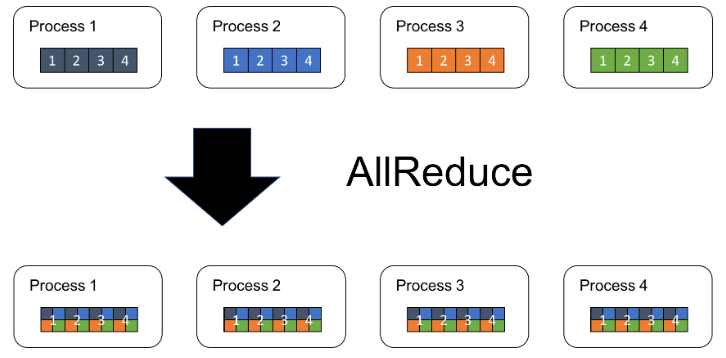
A straightforward implementation is to select one process as a master, gather all arrays into the master, perform reduction operations locally in the master, and then distribute the resulting array to the rest of the processes. Although this algorithm is simple and easy to implement, it is not scalable.
Ring-AllReduce Algorithm
Let us focus on the process [p]. The process sends chunk[p] to the next process, while it receives chunk[p-1] from the previous process simultaneously.
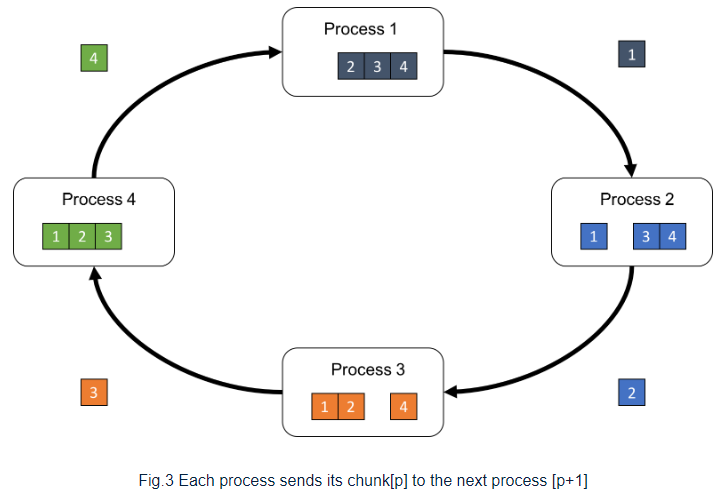
Then, process p performs the reduction operation to the received chunk[p-1] and its own chunk[p-1], and sends the reduced chunk to the next process p+1
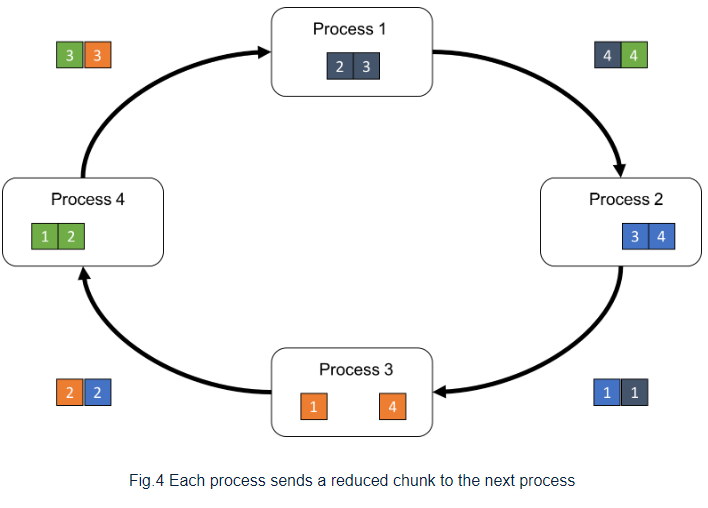
By repeating the receive-reduce-send steps P-1 times, each process obtains a different portion of the resulting array.
받은 chunk 를 그대로 다음 process 에 건네주고 하다보면 모든 각각의 chunk 는 ring 전체를 한번씩 돌게 되고 각 process 에 쌓이게 된다.
비동기 훈련
Parameter Server Architecture
내용 참고: https://medium.com/coinmonks/parameter-server-for-distributed-machine-learning-fd79d99f84c3
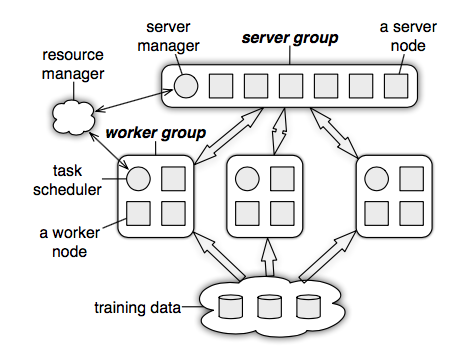
Server Group 안에 multiple server nodes 를 구성할 수 있음. Each server node in the server group is responsible for a partition of the keyspace/data.
Multiple worker nodes constitute worker groups which communicate with the sever groups for pulling of parameters and pushing of gradients as mentioned in the last section. Worker groups don’t need to communicate with each other.
- 각각의 worker 는 서로 다른 a subset of data 에 대해 gradient 를 계산하고 서버로 push 한다.
- 끝나면 서버에서 새로운 sets of weight 를 받는다.
