아직 원하는 결과에 도달하지 못한 이야기입니다.
조금은 어려운 글입니다.
참고로 목표는, 이용자가 등록한 위치정보와, 가전재품 정보를 등록한 후,
자신과 가까운 순으로 다른 유저들의 (같은 종류의) 가전제품 정보를 동적으로 불러와서 비교해주는 것입니다.
1. 서론
가장 가까운 이용자 100명의 정보를 얻어내기
PostgreSQL의 Indexing
글을 두가지 작성했는데,첫번째 글에서 제가 당도한 문제에서 레이턴시를 2000ms가 넘는 결과에서 400ms까지 줄이고 마무리 했습니다.
두번째 글에서는, 가장 가까운 유저들의 정보를 빠르게 추출가능한 GIST 인덱싱에 대해 학습했는데요.
첫번째 글에서 제가 취한 성능개선 전략은 명확한 한계가 존재합니다. 적응형 메모리를 활용하여 탐색 범위를 줄여도 O(N/k)의 시간복잡도를 가지게 됩니다. 이는 즉, 데이터가 늘어남에 따라 선형적으로 latency가 증가한다는 문제점은 사라지지 않는다는 한계점을 보여줍니다.
두번째 글에서의 GIST 인덱싱은 결과물을 추출하는 데에 있어 GeoHash를 사용해서 O(logN)의 시간복잡도를 가지게 됩니다.
그렇다면 GIST indexing을 실제로 적용하여 기존 서비스를 개선해보도록 합시다.
2. 본론
- 적응형 메모리가 필요없는 이유
- 메모리 캐싱의 의의는 I/O connection 타임을 줄이는 것에 의미가 더 크지, I/O sequence 자체의 시간을 줄이는데, 선형적인 시간을 유지하면 의미가 없다고 생각합니다.
실제로 캐싱이라는 전략은 자주사용하는 데이터를 메모리에 저장하므로써, DB connection(I/O connection) 자체를 줄이기 위한 전략도 포함되기 때문에,구역별 가중치를 메모리에 저장한다는 개념은 좋은 접근이 아니라고 생각합니다. - Node.js 기반이기에, 연산 코드가 늘어날 여지가 다분함. redis와 database 간의 데이터 소통을 위해서 가공하는 연산 코드가 발생할 수 있어 Node.js가 지향하는 바와 맞지 않습니다. 한번의 I/O에서 모든 것을 해결하는 것이 (오래 걸리더라도) 더 낫다 생각합니다.
(나중에 국가별 서비스를 구분하는데는 좋은 전략 될 것 같지만, 국가별 서비스를 구분하는데에는 차라리 클러스터링이나, 멀티서버를 이용하는 것이 훨씬 좋은 전략일 것입니다.)
기존에 사용했던 쿼리를 단순화하면 다음과 같습니다.
SELECT id FROM
account
ORDER BY
((latitude - (SELECT latitude FROM account WHERE id = 500000))^2 +
(longitude - (SELECT longitude FROM account WHERE id = 500000))^2)
LIMIT 100 OFFSET 0;이를 GIST 인덱싱을 이용하면,
SELECT id
FROM
account
ORDER BY location::geometry <-> 'SRID=4326;POINT(122.99697504528967 -75.6874406115837)'::geometry
LIMIT 100;와 같이 됩니다.
기존에는 데이터를 50만개를 사용했는데, 이번에는 500만개를 사용해서 진행해본 결과
각각 400ms, 0.5ms의 latency가 발생했습니다.
뭔가 이상한데?
기존에는 50만개에서 2000ms 이상의 레이턴시가 발생했는데, 왜 데이터가 늘었는데 시간이 줄어들었을까요?
그 이유는 JOIN에서 큰 레이턴시가 발생했기 때문입니다.
SELECT
account.id
FROM
account
JOIN
refrigerator
ON
account.id = refrigerator.account_id
ORDER BY
((latitude - (SELECT latitude FROM account WHERE id = 500000))^2 +
(longitude - (SELECT longitude FROM account WHERE id = 500000))^2)
LIMIT 100 OFFSET 0; SELECT
account.id
FROM
account
JOIN
efrigerator
ON
account.id = refrigerator.account_id
ORDER BY location::geometry <-> 'SRID=4326;POINT(122.99697504528967 -75.6874406115837)'::geometry
LIMIT 100;각각의 레이턴시는
2000ms, 1800ms가 나옵니다.
기존에는 O(N) vs O(logN)의 레이턴시 대결이었지만,
JOIN을 모든 데이터에 대해 수행했기 때문에,
O(2*N) vs O(N + logN)의 양상이 되었기 때문입니다.
따라서 다음과 같은 환경을 감안하면서 문제를 해결하려 합니다.
- 유저는 1억명일 수도 있음.
- 그리고 냉장고를 가진사람이 얼마 되지 않을 수도 있음.
전 3가지의 전략을 떠올렸습니다.
3-1. 먼저 근처 사람을 찾아내고, 가지고 있는 가전을 서칭하는 방법
=> 가까운 순으로 유저를 100명 찾은 다음에, 그가 소유하고 있는 refrigerator를 참조한다.
JOIN 하는 범위를 100개로 줄이는 전략입니다.
하지만 이에 대해서는 치명적인 단점이 존재합니다.
만약 근처 100명 중, refrigerator를 쓰는 사람이 부족하면, 원하는 데이터를 위해 다시 쿼리를 수행해야 합니다. (N+1문제)
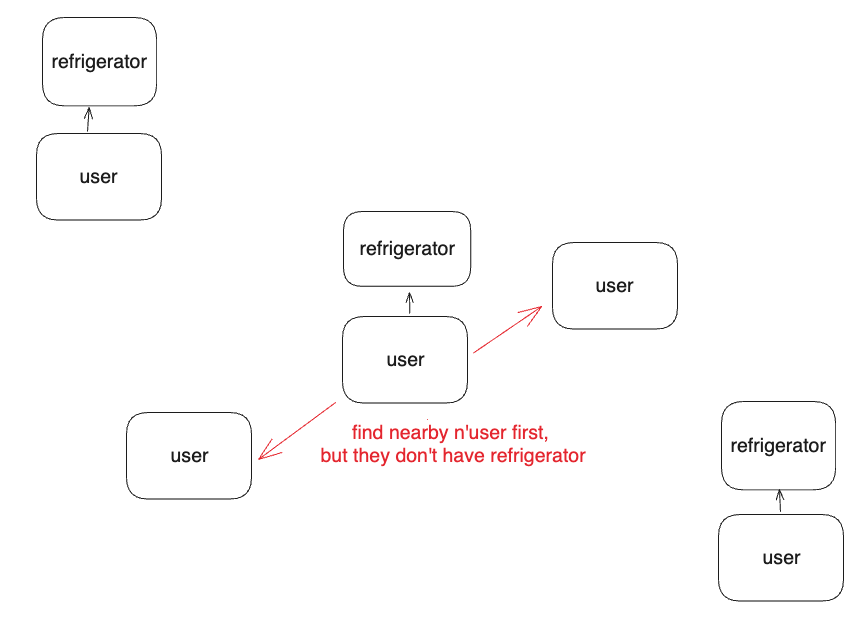
100명이 아니라, 2명이라 가정하면, 가장 가까운 2명을 먼저 찾아내고, 그들이 가진 refrigerator를 조회했는데, 없을 수 있습니다.
처음 추출하는 대상을 많이 추출하는 방법이 있을 수 있겠지만, 근본적인 해결안이 될 수 없습니다. (커질 수록 더 많은 latency가 발생함 + 그래도 N+1 문제가 발생할 수 있음)
3-2. 가까운 순으로 순차적으로 JOIN 하기?
이론적으로는, 가장 가까운 순서의 유저들을 확인하면서, 각각 JOIN을 해보면서 데이터가 원하는 개수가 나올 때까지 할 수 있지 않을까 싶었습니다.(이론 상)
다만, 여러가지 문제가 있습니다.
'가까운 유저를 순차적으로 JOIN을 하면서 N개를 채우면 쿼리를 종료한다'는 전략은 코드로 구현하기 쉽지 않습니다.
(저희가 전체 데이터에서 거리별 searching 시간을 줄일 수 있었던 이유는, ORDER BY와, LIMIT를 이용했기 때문인데, 이를 JOIN 조건으로 사용하기 쉽지 않습니다. searching function 자체가 extension으로 인해 만들어진 함수이기 때문입니다.)
작성하게 되더라도, 유지보수가 힘든 코드일 뿐만 아니라, 성능적으로도, 500만명 중, 단 100명의 사람들만 냉장고를 가지고 있다면, 최악의 경우 O(N)의 latency가 그대로 발생하기 때문입니다.
작성할 실력도 모자르고, 작성해도 성능이 지향하는 바가 원하는 바가 아님
3-3. SubTable(refrigerator 테이블)에 위치 컬럼을 저장하는 방법
단점은 명확합니다.
- 정규화로부터 어긋남.
refrigerator에 위치 컬럼을 추가한다면, account의 위치 컬럼을 참조해야 합니다.
refrigerator은 기본적으로 account_id column이 account의 id 컬럼을 fk로 참조하고 있기 때문에, 이중으로 참조하게 됩니다. - 용량을 그만큼 할당해야함.
하지만, 저희가 지향하는 방법론에는 가장 적절한 방법입니다.
- 유저가 많아도 되고, 냉장고를 가진 사람이 적어도 됨.
refrigerator 안에서만 탐색해서 전체 유저 수와는 상관이 없음 + GIST로 빠른 서칭 가능
하지만 문제가 존재합니다. Location의 특성 상, 중복되는 value를 가질 수 있기 때문에, unique key가 될 수 없어 fk로 참조할 수 없다는 점.
이를 해결해보도록 하겠습니다.
4. 어떻게 설계할 것인가?
일단, 서브테이블에 위치 정보를 두는 것이 목표이고, 이는 원래의 테이블과 cascade 되어야 하므로 참조를 하는 것을 목표로 하겠습니다.
4-1. FK 참조 시도
단순하게 refrigerator에 location(geometry) 컬럼을 생성해서 account table의 location 컬럼을 참조하면 될 줄 알았습니다.
하지만 account 테이블에 존재하는 location 컬럼은 Gist라는 인덱싱이 적용 됐지만, Not unique한 값이기 때문에, 참조가 불가능합니다.
물론, location에 unique constraint를 적용하면 참조가 가능하겠지만, location은 실제로 중복이 될 수 있는 값입니다. 따라서 적용하지 않는 것이 옳습니다.
설령, 참조가 가능하게 되더라도, 이중 참조의 문제를 가지게 됩니다.
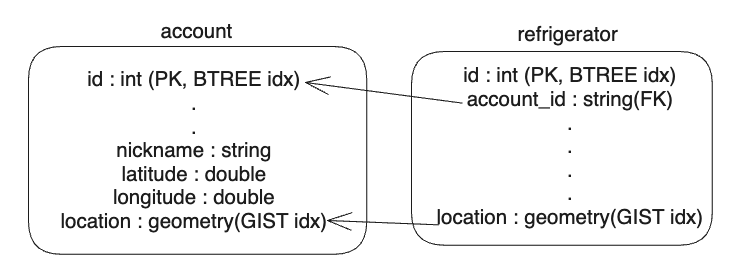
그러면 location 컬럼에 대해서 테이블을 분리(정규화)할 수 있지 않나?
종속성(확실한 용어는 아님) 문제 때문에 불가합니다.
(가령, 하나의 좌표를 공유하는 두 account 데이터가 있고, location table에 하나의 좌표가 있을 때, CASCADE에 대해 생길 문제를 생각해보면...)
4-2. 복합키(composite key) 참조
location은 중복된 값을 가지지만, id(PK)는 중복된 값을 가지지 않습니다. (id,location)을 묶어서 composite key를 생성하면, unique한 속성을 띌 수 있고, 이 두 컬럼 모두 refrigerator에도 존재하는 컬럼이기 때문에, 해당 키로 참조를 했습니다.
그 과정에서 기존에 있던 FK를 참조를 취소할 수 있기 때문에, 단일 참조로 변경 또한 가능합니다.
참조를 설정하는 쿼리문은 다음과 같습니다.
ALTER TABLE refrigerator
ADD FOREIGN KEY (account_id, location) REFERENCES account (id, location)
ON UPDATE CASCADE
ON DELETE CASCADE;이제, refrigerator 테이블에 존재하는 location 값은 account table의 location 값에 따라 동적으로 변경됩니다. (값 또한 감소)
또한 refrigerator 내부에서 다른 table과의 join 없이 가까운 위치의 데이터들을 찾아낼 수 있음과 동시에, 다른 서브테이블이 추가되더라도 (냉장고 외에도 다른 가전제품 테이블) account의 위치정보만 관리해주면 자동으로 cascade 됩니다.
'JOIN 없이 refrigerator 테이블에서만' 위치가 가까운 순으로 다른 사람들의 가전제품 정보를 불러봅시다.
SELECT account_id
FROM refrigerator
ORDER BY location::geometry <-> ST_SetSRID(ST_MakePoint(
(SELECT longitude FROM account WHERE id = ${id}),
(SELECT latitude FROM account WHERE id = ${id})), 4326)
LIMIT 100이제 1ms의 속도가 나오겠죠???
.
.
.
.

아니, 내가 잘못 봤나?
확실히 JOIN은 안하게 됐지만, 이 정도 속도면 Gist indexing이 성능이 제대로 발휘되지 않은 것입니다.
+...따로 location 컬럼에 단일 unique key를 걸어서 진행해봤는데, GIST 인덱싱의 경우, FK로 참조하는 경우에서는 자동으로 인덱싱이 적용되지 않고, FK가 있는 테이블에서 따로 indexing을 생성해줘야 한다고 합니다.
4-3. GIST indexing 재적용
그렇다면 GIST 인덱싱을 refrigerator 테이블의 location 컬럼에 적용해야 합니다.
다만, 이제 원래 TABLE에서는 가까운순으로 검색할 일이 없으니 GIST 인덱싱을 제거해주는 것도 잊지 말아야 합니다. (컬럼 자체는 다른 테이블들의 CASCADE를 관리하기 위해서 필요함)
최종 테이블 구조는 prisma schema로 보여드리자면,
model Account {
id Int @id @default(autoincrement())
mail String? @unique @db.VarChar(100)
pw String? @db.VarChar(32)
nickname String? @unique @db.VarChar(32)
longitude Float?
latitude Float?
location Unsupported("geometry")?
refrigerator Refrigerator[]
@@unique([id, location], map: "location_unique")
@@index([mail], map: "mail_idx")
@@map("account")
}
/// This table contains check constraints anprisma migrate dev --name initd requires additional setup for migrations. Visit https://pris.ly/d/check-constraints for more info.
model spatial_ref_sys {
srid Int @id
auth_name String? @db.VarChar(256)
auth_srid Int?
srtext String? @db.VarChar(2048)
proj4text String? @db.VarChar(2048)
}
model Refrigerator {
id Int @id @default(autoincrement())
account_id Int @default(autoincrement())
energy Float? @db.Real
co2 Float? @db.Real
model_name String? @db.VarChar(50)
location Unsupported("geometry")?
account Account? @relation(fields: [account_id, location], references: [id, location], onDelete: Cascade)
@@index([location], map: "gist_idx", type: Gist)
@@map("refrigerator")
}와 같습니다.
5. 최종 결과
전체 이용 유저 500만명 중, 같은 종류의 가전을 지니고 있는, 가장 가까운 100명의 사람들에 대해
account 테이블의 id 순으로, account 테이블의 nickname을 출력 (보기 쉽게 하기 위해서).
1. 기존 쿼리
SELECT subquery.nickname
FROM (
SELECT
a.id,
a.nickname,
b.energy,
((a.latitude - (SELECT latitude FROM account WHERE id = ${id}))^2 +
(a.longitude - (SELECT longitude FROM account WHERE id = ${id}))^2) as distance
FROM
account a
JOIN
refrigerator b
ON
a.id = b.account_id
ORDER BY
((a.latitude - (SELECT latitude FROM account WHERE id = ${id}))^2 +
(a.longitude - (SELECT longitude FROM account WHERE id = ${id}))^2)
LIMIT 100 OFFSET 0
) AS subquery
ORDER BY
id;실행 결과
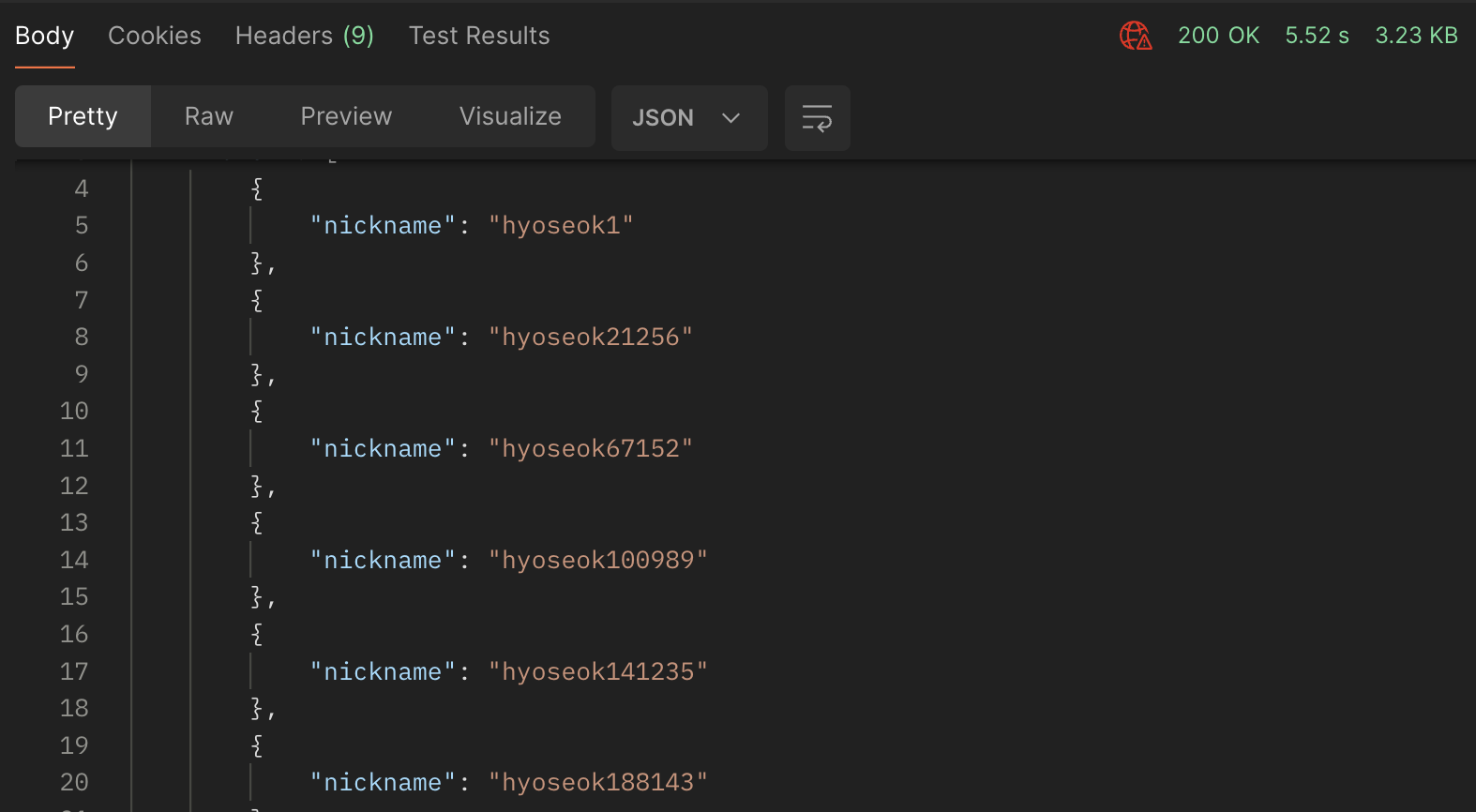
API 호출에 5520ms 소요
2. 변경한 데이터베이스와 쿼리
SELECT nickname
FROM account
WHERE id IN (
SELECT account_id
FROM refrigerator
ORDER BY location::geometry <-> ST_SetSRID(ST_MakePoint((SELECT longitude FROM account WHERE id = ${id}),(SELECT latitude FROM account WHERE id = ${id})), 4326)
LIMIT 100
)
ORDER BY id;실행 결과
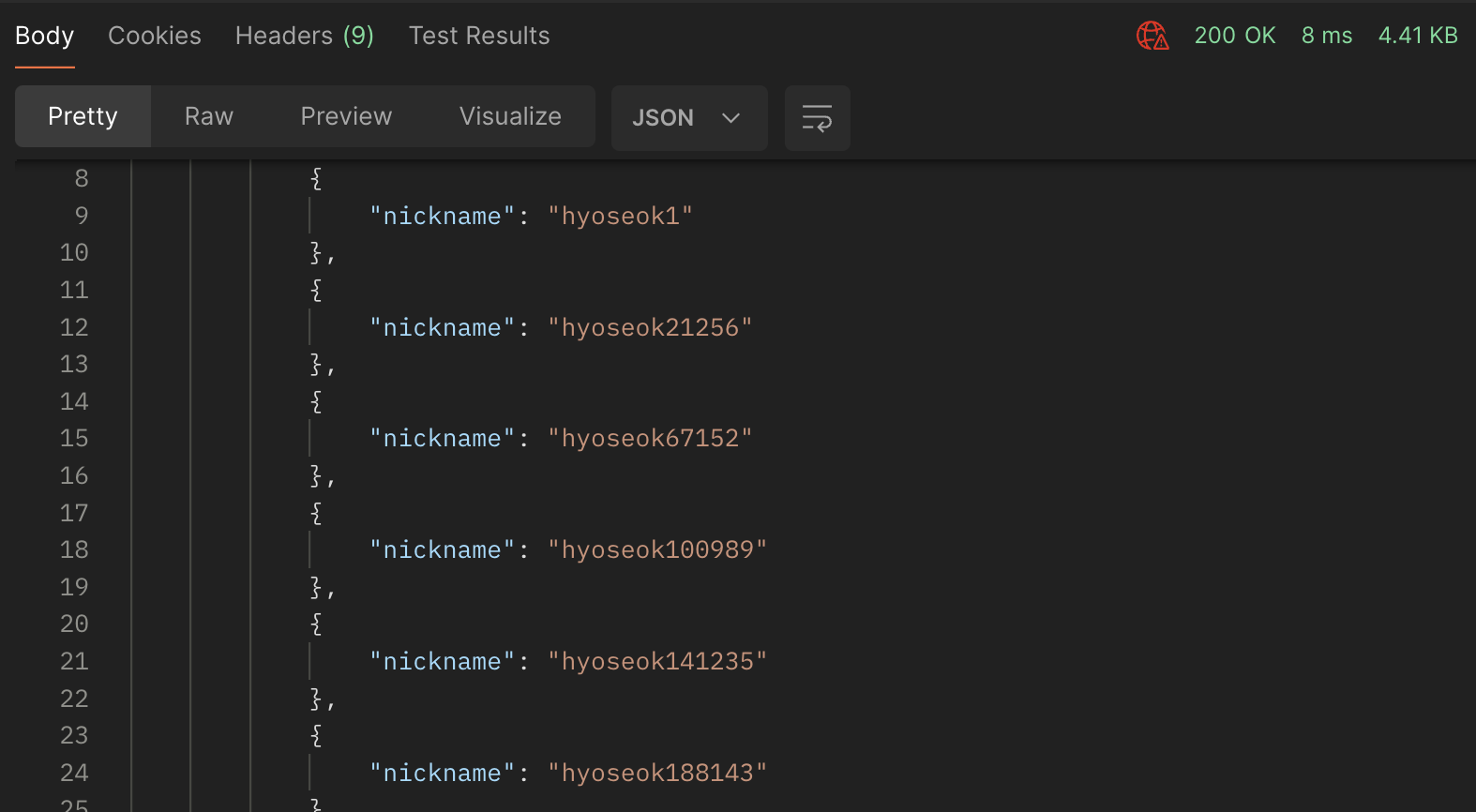
API 호출에 8ms 소요(동일한 검색 결과)
6. 후기
제가 완성한 설계가 절대로 완벽한 설계라 생각하지 않습니다.
레이턴시를 개선하기 위해서 너무나 많은 trade-off를 겪었기 때문입니다. (저장공간 발생 및, 정규화 무시 등등)
trade-off 없이도 성능을 개선할 수 있을 것 같지만, query에 대한 지식이 많이 부족해서 불가능 했습니다. JOIN 부분을 더 공부해야할 것 같습니다.
하지만, 원하는 프로젝트의 문제점을 개선하고 가장 원하던 1차 목표인 성능 개선을 얻을 수 있었기 때문에 최종적으로는 만족스럽습니다.
앞으로도 정진하겠습니다. 읽어주셔서 감사합니다.
