Content Based Recommendation
우리는 이전에 지식 기반의 추천시스템이 사용자간의 개인적 선호도를 고려하지 않은 시스템이었다.
이를 해결하기 위해서 나온 것 중 하나가 컨텐츠 기반의 추천시스템이다.
컨텐츠 기반의 추천 시스템이 사용성(usability) 관점에 따라 극도로 영향을 받는다.
사용성이란, 실제로 원하는 것을 정하고 그에 따라 방향이 바뀌어진다는 것이다.
특정 내가 보고자 하는 것에 대한 추천이지, 다른 여러가지를 추천하는 것이 아니다. 컨텐츠 기반의 추천 시스템은 새 아이템이거나 해당 아이템에 대한 평가가 거의 없는 경우에 유용하다.
이번엔 컨텐츠 기반의 추천 시스템이 2가지의 type을 소개하고자 한다.
1. Plot description Based Recommendation
이 모델은 다른 영화의 설명과 태그라인을 비교하고 가장 유사한 줄거리 설명을 가진 추천을 제공합니다. 2. Metadata Based Recommendation
이 모델은 장르, 키워드, 출연진, 제작진과 같은 다양한 기능을 고려하고 앞서 언급한 기능과 관련하여 가장 유사한 권장 사항을 제공합니다. TF-IDF
Wij = tfij * log(N/dfi)
Wij = 문서 j의 단어 i의 weight
dfi = 단어 i가 포함된 문서의 개수
N = 문서의 총 개수 TF-IDF 사용하는 이유는
1. 몇개의 단어들이 plot descriptions에서 다른것들 보다 빈번하게 더 많이 발생(occur)한다.
2. 문서쌍의 cosine similarity 점수를 계산하는 것을 speeds up 한다.
1. Plot description Based Recommendation
우린 영화 제목을 인자로 받아서, 그에 가장 similar한 plots를 리스트로서 출력을 준다.
1> 모델에 맞는 데이터를 얻고서
2> 모든 영화의 plot description을 위해 TF-IDF를 생성한다.
3> 모든 무비의 cosine similarity를 계산하고
4> 영화 제목을 인자로 받아서 가장 가까운 plots를 리스트로 출력해주는 추천시스템 함수를 작성한다. 1> 모델에 맞는 데이터를 얻기위해
#Import data from the clean file
df = pd.read_csv('../data/metadata_clean.csv')
df.head() # clean되어진 Data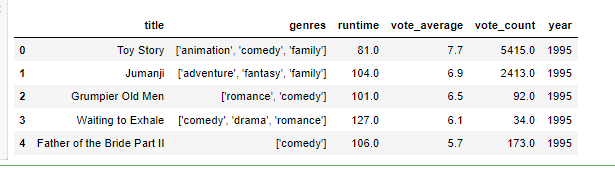
#Import the original file
orig_df = pd.read_csv('../data/movies_metadata.csv', low_memory=False)
# 기존 데이터 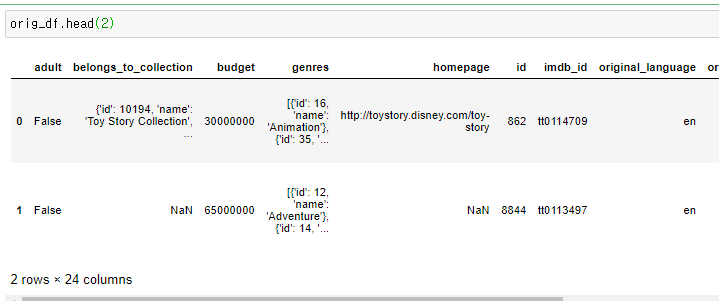
기존의 데이터에서 우리는 영화의 설명과 ID를 가져오고자 한다.
#Add the useful features into the cleaned dataframe
df['overview'], df['id'] = orig_df['overview'], orig_df['id']
2> 그 다음 우리는 TF-IDF 를 생성한다.
# Import TfIdfVectorizer from the scikit-learn library
from sklearn.feature_extraction.text import TfidfVectorizer
# 영어중에 불용어들을 모두 제거해준다. 불용어는 am are is 등등 자주 쓰여져, 정보가 없는 단어들
tfidf = TfidfVectorizer(stop_words='english')
# 혹시라도 빈 데이터(결측치) 가 존재할 수 도 있으므로 ""으로 채워준다.
df['overview'] = df['overview'].fillna('')
# overview 개요설명을 기준으로 tfidf를 생성한다.
tfidf_matrix = tfidf.fit_transform(df['overview'])
tfidf_matrix.shape # (45466, 75827)3> cosine similarty를 계산해주자 !
# Import linear_kernel to compute the dot product
from sklearn.metrics.pairwise import linear_kernel
# cosine similarity을 계산한 행렬을 지정해준다.
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)4 > 추천시스템 함수를 작성
# 영화 제목의 index를 생성할때, 중복인 것은 제거하고 만들어준다.
indices = pd.Series(df.index, index=df['title']).drop_duplicates()# 영화 제목을 인자로 넣어주어야 한다.
def content_recommender(title, cosine_sim=cosine_sim, df=df, indices=indices):
# 영화 제목과 match 된 인덱스를 가져와서
idx = indices[title]
# 모든 영화와의 가져온 인덱스(input된 영화제목 인자)와 점수를 보고
# 튜플, () 으로 가져와 넣어준다. == enumerate(cosine_sim[idx]), # 사용시 list로 받는다.
# 이때 영화제목의 index를 가져와서 (index, cosine_score)로 튜플(괄호())로 가져오는 것.
sim_scores = list(enumerate(cosine_sim[idx]))
# input된 영화 제목과 pairwise된 cosine 점수를 가지고, 점수를 sort하는데 역방향으로 가져온다.
# 이때 점수는 x[1]이다. x[0]는 인덱스 값이다.
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# top 10개 정도만 가져와 준다.
sim_scores = sim_scores[1:11]
# 튜플로 가져왔던것에서 (index, cosine_score) 이므로 index값을 가져와서
# input된 영화 제목과 가장 유사한 top10의 영화 제목 movie_indices에 넣고 데이터 프레임에서 리턴한다.
movie_indices = [i[0] for i in sim_scores]
# Return the top 10 most similar movies
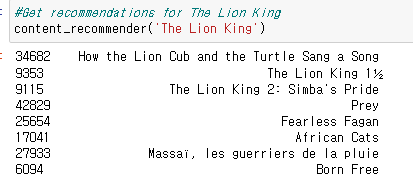
return df['title'].iloc[movie_indices]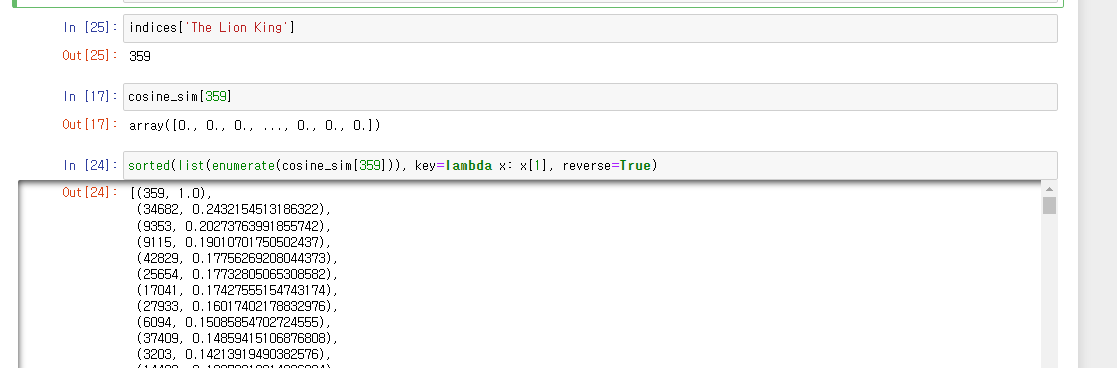
결과

행복을 찾아서(크리스 가드너)