recommendation_study
1.quantile

pandas.quantile(q=0.5)q = 0.8 (현재 칼럼의 0.8(=80%) 분위수를 나타내보자)현재 'vote_count' 에서의 백분위 중에 80%에 해당하는 값은 50이다. 그렇다면 우리가 80% 이상인 값을 쓰려면
2.simple_recommendationSystem
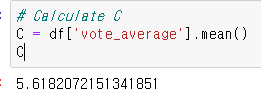
현재 vote_average에 있는 값의 mean() 내가 가지고 있는 데이터프레임에서 가중치score를 주기 위해 계산한다.v = 데이터프레임'vote_count' R = 데이터프레임'vote_average'm = 50 C = 데이터프레임'vote_average'
3.knowledge_based recommender
이번 공부는 knowledge based recommender 파트 이다. 그 외 자세한 부분은 "Hands-on Recommendation Systems with python" 의 책, 저자 : Rounak Banik 을 확인하자 ! http://www.ky
4.Content-Based Recommenders
Content Based Recommendation우리는 이전에 지식 기반의 추천시스템이 사용자간의 개인적 선호도를 고려하지 않은 시스템이었다.이를 해결하기 위해서 나온 것 중 하나가 컨텐츠 기반의 추천시스템이다. 사실 컨텐츠 기반의 추천 시스템이 usability에
5.Content-Based Recommenders 2

Content-Based Recommenders 2이번에 공부한 것은 메타데이터 기반의 추천 시스템이다. 순서는1> 메타 데이터를 준비하기2> 데이터 정제하기 3> CountVectorizer를 사용4> 메타 데이터에 따른 추천 시스템 기반 구현. countVector
6.recommeder_system_CF
item_based CF사용자는 서로 유사한 두 항목을 비슷하게 평가할 가능성이 높습니다.model_based CFmachine learniong 알고리즘을 사용하지 않는다.
7.Hybrid Recommenders
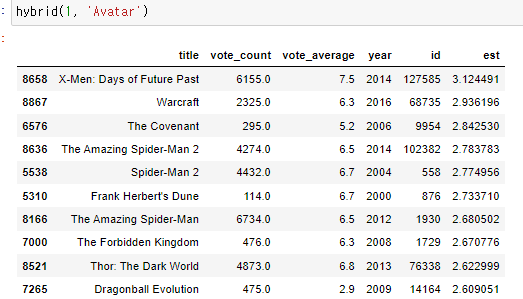
이 마지막 장에서, 우리는 실용성과 산업적 사용의 맥락에서 추천 시스템에 대해 논의할 것이다.지금까지 지식, 콘텐츠, 협업 필터링 기반 엔진 등 다양한 유형의 추천자에 대해 알아봤다.그러나 실제로 사용될 때, 각 추천자들은 보통 이런저런 단점을 겪는다.우리는 첫 번째
8.recommender_system_평가
추천시스템의 평가 요소 MAE sigma( |예측한 랭크값 - 실제 랭크값| ) / 전체 아이템수NMAE MAE / (실제 랭크값에서의 최대값) - (실제 랭크값에서의 최소값)RMSE sigma( root ((예측한 랭크값 - 실제 랭크값)^2) ) / 전체 아이템수
9.ConsisRec: Enhancing GNN for Social Recommendation via Consistent Neighbor Aggregation
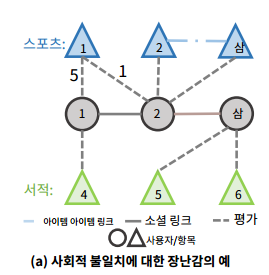
ConsisRec: Enhancing GNN for Social Recommendation via Consistent Neighbor Aggregation 요약 :기존의 소셜 추천은 등급예측에 대한 콜드 스타트 문제를 완화하기 위해 사용자 항목 상호 작용과 소셜 링크를
10.A Deep Graph Neural Network Based Mechanism for Social Recommendations
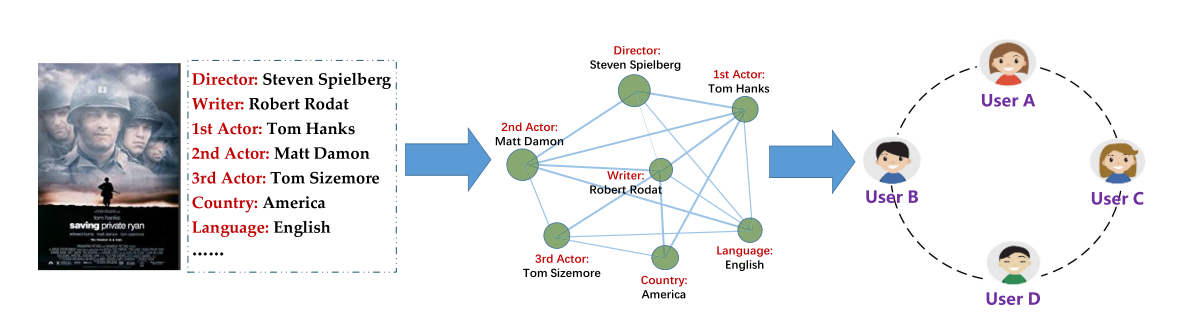
A Deep Graph Neural Network-Based Mechanism for Social Recommendations reviews기존 연구의 거의 대부분은 일부 사회 집단의 토폴로지에 추가로 영향을 미칠 수 있는 항목 특징 간의 상관관계를 무시하고 사용자 선
11.Knowledge-aware Coupled Graph Neural Network for Social Recommendation
대부분의 모델은 항목 간의 상호의존적 지식을 무시하면서 사용자의 사회적 연결만 고려한다.기존 솔루션의 대부분은 단일 유형의 user-item 상호 작용을 위해 설계되어 상호 작용 이질성을 포착을 못한다.따라서 사용자-항목 상호 작용 인코딩과 통합하는 다양한 신경망 기술