이번 공부는 knowledge based recommender 파트 이다.
그 외 자세한 부분은 "Hands-on Recommendation Systems with python" 의 책, 저자 : Rounak Banik 을 확인하자 !
http://www.kyobobook.co.kr/product/detailViewEng.laf?mallGb=ENG&ejkGb=ENG&barcode=9781788993753
추천 시스템 기초부터 실무까지 머신러닝 추천 시스템 교과서, 차루 아가르왈 지음 | 박희원 , 이주희 , 이진형 옮김
http://www.kyobobook.co.kr/product/detailViewKor.laf?mallGb=KOR&ejkGb=KOR&barcode=9791161755878
지식기반 방법은 추천을 작성하기 위해 사용자 요구 사항을 명시적으로 지정해야 하며, 과거의 평점이 전혀 필요치 않다. 이는 콘텐츠 기반 혹은 협업 시스템 보다 콜드 스타트 문제를 훨씬 더 해결할 수 있다. 하지만 과거 데이터로부터 영구적인 개인화를 사용한다는 점에서 콘텐츠 및 협업 시스템보다는 성능이 낮을 수 있다는 단점을 가지고 있다.
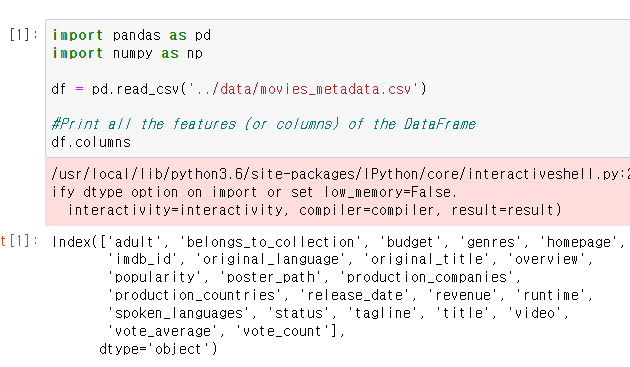
이제 이렇게 많은 데이터 중에 난 내가 원하는 부분만 가지고서 추천을 할건데
기존의 데이터가 너무나 많으니 필요한 것들만 뽑아본다.
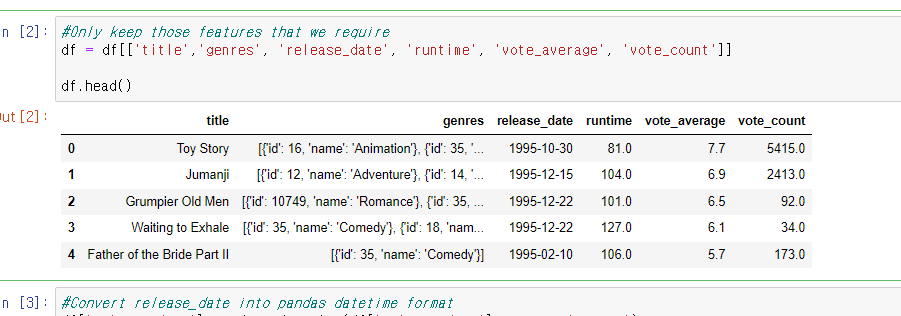
이제 내가 필요한 부분은 제목, 장르, 출시일, 투표평균점수, 투표수 이렇게 각 데이터 프레임에 넣어서 진행하고자 한다.
이렇게 원하는 것에서 추가적으로 year에 해당하는 부분만 추출하기 위해서 출시일에서 첫번째 인덱스 부분만 일단 가져와 본다.

이러면 기존의 출시일에서 pd.to_datetime() 함수를 이용하여 각 year, 월, 일로 되어져 있는 상태에서 apply() 함수를 이용하여, lamda x : str(x).split('-')[0] if x != np.nan else np.nan) 를 진행하여 현재 출시일 데이터에서 -를 기준으로 잘라서 첫번째 인덱스인 year를 가져와
기존의 df에서 ['year'] 열을 만들어 추가하고자 한다. 근데 이제 첫번째 인덱스인 year이 존재하지 않다면 numpy.nan를 통해서 없는 데이터를 표시하고자 nan 값을 넣어준 것이다.
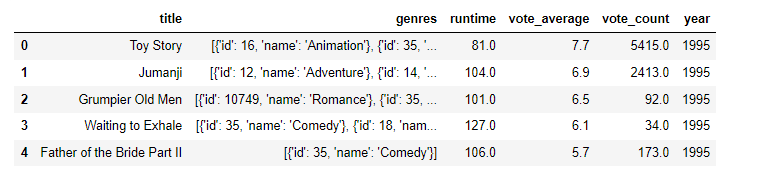
데이터를 이제 내 입맛대로 굴려놓고서 ['year'] 부분에는 내가 필요한 인덱스가 year만 가져온 상태를 결과로 보여주고 있다.

다음 그림을 한번 보자, 여기서 'genres' 부분이 파이썬의 {} 중괄호, 즉 딕셔너리 처리가 되어져 있다. 보통 json 파일이 이런식으로 되어져 있다고 나와있다.
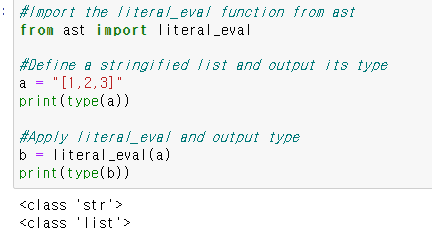
다음 예시처럼 파이썬의 string으로 되어져 있는 부분들이 list의 형태로 나와주는 literal_eval() 함수를 이용할 수도 있다.
기존의 딕셔너리 {} 되어진 부분들이 이번처럼 [] 리스트의 형태로 나와져 데이터를 훨씬 수월하게 사용할 수 있게 된다는 것이 엉망인 데이터를 전처리 하는 과정에 있어서 중요하다는 것을 인지하게 해준다.
#Convert all NaN into stringified empty lists
df['genres'] = df['genres'].fillna('[]')
#Apply literal_eval to convert stringified empty lists to the list object
df['genres'] = df['genres'].apply(literal_eval)
#.lower() # string 소문자 변형
#if isinstance(x, list) else [] # 리스트 변환된건지 확인후 아니면 [] 리스트로
df['뮤'].apply(lambda x: [i['name'].lower() for i in x] if isinstance(x, list) else [])
df.apply(lambda x: pd.Series(x['genres']),axis=1).stack().reset_index(level=1, drop=True)
#Name the new feature as 'genre'
s.name = 'genre'
#Create a new dataframe gen_df which by dropping the old 'genres' feature and adding the new 'genre'.
gen_df = df.drop('genres', axis=1).join(s)만약 내가 여기서 이제 질문을 던지게 된다면
#Ask for preferred genres
print("Input preferred genre")
genre = input()
#Ask for lower limit of duration
print("Input shortest duration")
low_time = int(input())
#Ask for upper limit of duration
print("Input longest duration")
high_time = int(input())
#Ask for lower limit of timeline
print("Input earliest year")
low_year = int(input())
#Ask for upper limit of timeline
print("Input latest year")
high_year = int(input())
장르가 무엇이고, 가장 짧은 기간, 가장 긴 기간, 출시일 기준으로 앞뒤로 넣고서
내가 원하는 구간을 찾아 그 데이터만을 추천해주는 것이 바로
knowledge_based recommeder 가 된다. 이때 지식기반이 사용자가 원하는 구간을 정해서 그 구간속에서 weight_score를 구하여 내림차순으로 추천을 진행하는 것이 knowledge_based 의 추천 시스템을 구현된 것이다.
아마, 도서관 이용할때, 책의 저자, 연도, 기간 등, 혹은 유튜브로 기간을 설정해서 진행하는 것이
knowledge_based 된 추천이 된 것이라고 생각한다.
이상
#Define a new movies variable to store the preferred movies. Copy the contents of gen_df to movies
movies = gen_df.copy()
#Filter based on the condition
movies = movies[(movies['genre'] == genre) &
(movies['runtime'] >= low_time) &
(movies['runtime'] <= high_time) &
(movies['year'] >= low_year) &
(movies['year'] <= high_year)]
#Compute the values of C and m for the filtered movies
C = movies['vote_average'].mean()
m = movies['vote_count'].quantile(percentile)
#Only consider movies that have higher than m votes. Save this in a new dataframe q_movies
q_movies = movies.copy().loc[movies['vote_count'] >= m]
#Calculate score using the IMDB formula
q_movies['score'] = q_movies.apply(lambda x: (x['vote_count']/(x['vote_count']+m) * x['vote_average'])
+ (m/(m+x['vote_count']) * C)
,axis=1)
#Sort movies in descending order of their scores
q_movies = q_movies.sort_values('score', ascending=False)
return q_movies이는 사실 사전 도메인의 지식이 존재해야만 추천이 가능하며, 이는 각 사용자의 preferences를 take account 한다는 것이다.
단순 추천하는 것은 개별 사용자의 선호도를 고려하지 못한다는 것이다.
여전히 매우 generic 하다.
