1. Abstract
-
Goal of the Competition
- Classification Problem
분류문제로, 17종의 문서타입을 분류하는 Task수행.
-
Timeline
- January 10, 2024 - Start Date
- February 20, 2024 - Final submission deadline
-
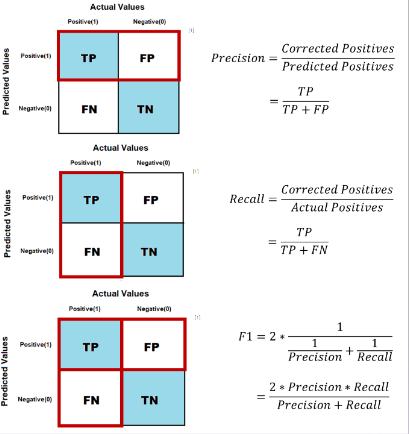
Metric
-
f1-score를 사용하였습니다.
-
모델이 예측한 것이 실제로 얼마큼 맞는지 정밀도(precision)
-
모델이 예측한 것중에 실제 틀린것이 얼만큼 맞는지 재현율(recall)
-
2. Process : Competition Model
- 5가지의 timm pretrained.
- vgg16, vit, resnet, yolov8, efficientNet
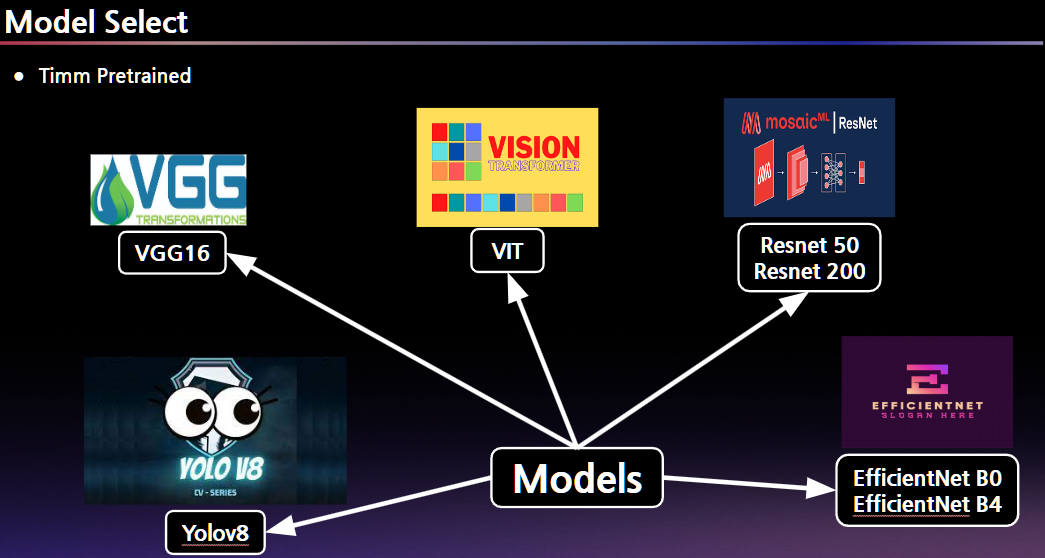
- vgg16, vit, resnet, yolov8, efficientNet
3. Process : Data Describe
-
Describe the data EDA that your team faced during the project.
학습데이터는 1570개의 데이터를 가지고 있고, class는 총 17개의 문서타입을 가지고 있다. 평가데이터는 3140개의 데이터를 분류하는 것이다.
-
전체적인 흐름(floww chart)
문서 데이터들은 각 문서끼리의 차이가 크게 나는 것도 있고, 문서의 특징이 구별되지 않는 경우(노이즈)의 영향이 있다. 따라서 모델의 학습간에 validation을 계속 확인하면서, Augmentation전략을 지속적으로 수정하며 성적향상을 이루었다.

-
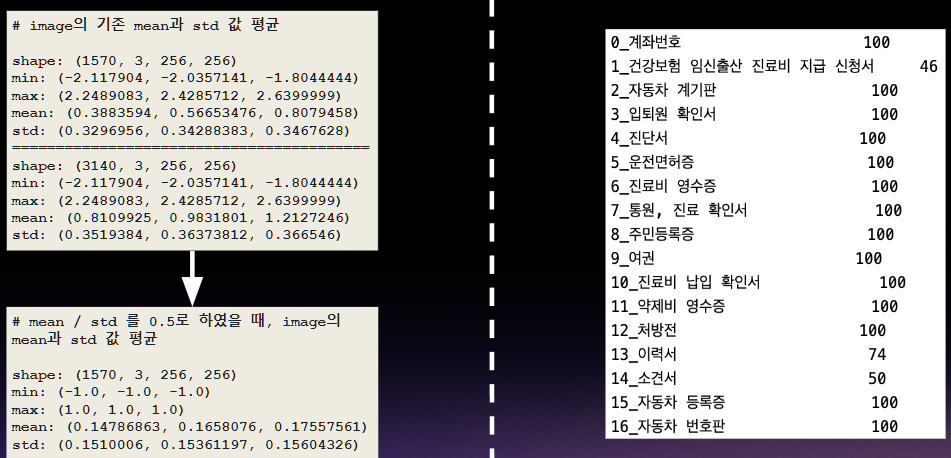
데이터 기초통계
학습 이미지를 정규화하기 전의 최소값이 (-2.11 ~ -1.80) 평균값이 대략 (0.388 ~ 0.807)로 정규화 전의 이미지가 차이가 있음을 보였다.
그리고, 17개의 클래스가 1번, 13번, 14번 클래스에서 데이터 불균형이 있음을 확인 가능함.
-
데이터의 정규화
이미지 데이터의 정규화(0.5, 0.5)로 실험해본 결과, 다음과 같이 설적 향상이 이루어진 것을 볼 수 있다. 정규화가 성적향상에서는 기울기의 업데이트가 일정 수 만큼 지속적으로 이루어지는것으로 global 최소에 일정비율만큼 작아짐.
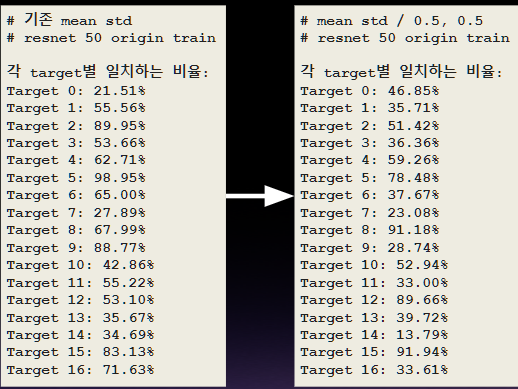

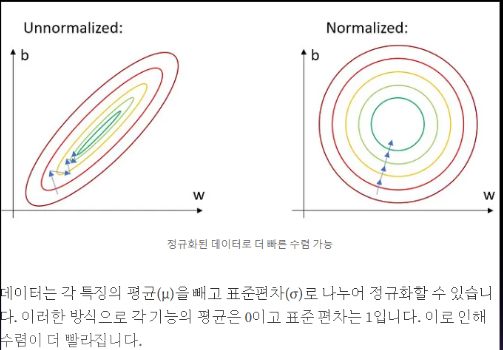
4. EDA
-
Describe your role with task in your team.
- 학습 데이터간에 이미지 형태가 그림자가 있는 이미지나, 색이 다른 이미지가 존재하는 경향이 있음.

- 또한, 학습 데이터의 label(class)가 잘못 오분류 되어진 경향을 확인함.

-
conv level image
-
Feature Engineering. 학습된 이미지의 conv level을 보면 이미지의 대략적인 코너, 선, 박스, 검은부분들을 학습하는 것을 확인가능함.

-
또한, 4개의 데이터에서 모델이 학습시에 입퇴원확인서, 진단서, 의료 납입 확인서, 소견서 데이터의 영향이 발생함.
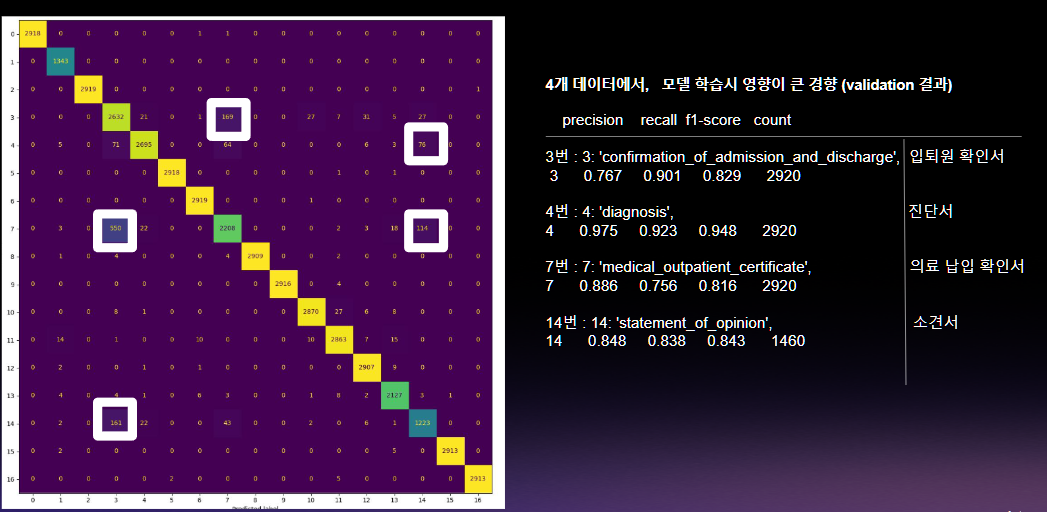
-
다음으로, 하이퍼 파라미터를 튜닝하기 위해 5가지로 진행함.
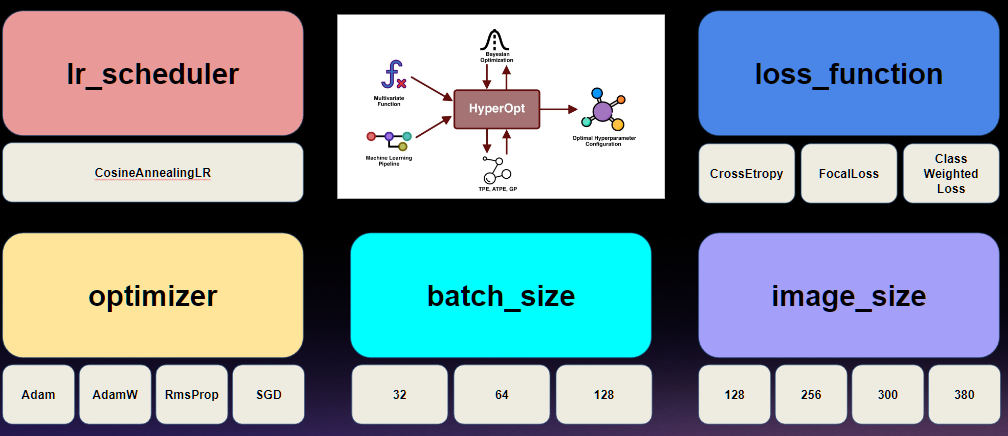
-
-
그리고, 불균형 데이터를 focal loss로 해결하기 위하여 진행하였고, weight를 직접 주어서 class를 잘 맞히도록 loss에 영향을 주었다.
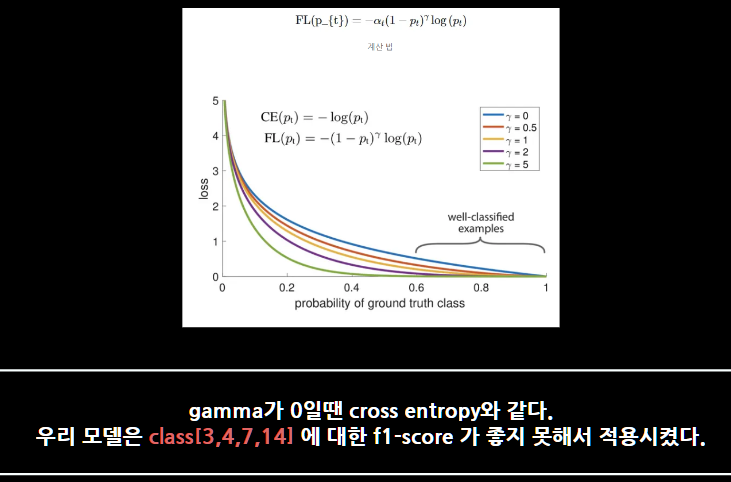
5. Results
-
Write the main result of Competition
- 1등을 하였지만, 위 결과에서는 휴먼 분류한 것으로 나왔다.
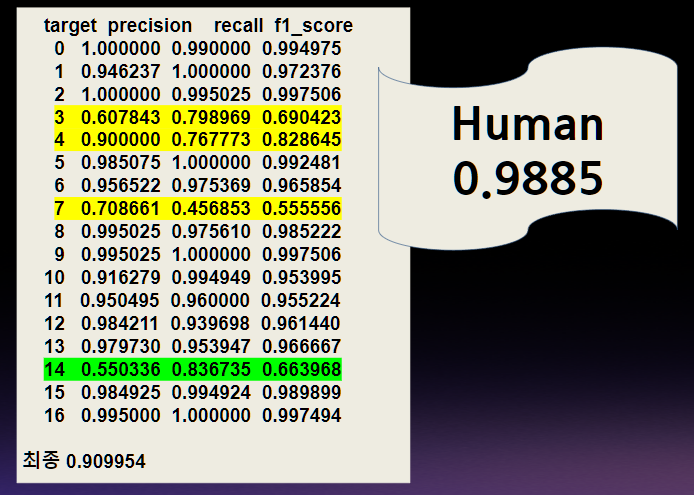
- 1등을 하였지만, 위 결과에서는 휴먼 분류한 것으로 나왔다.
-
Final standings of the Leaderboard
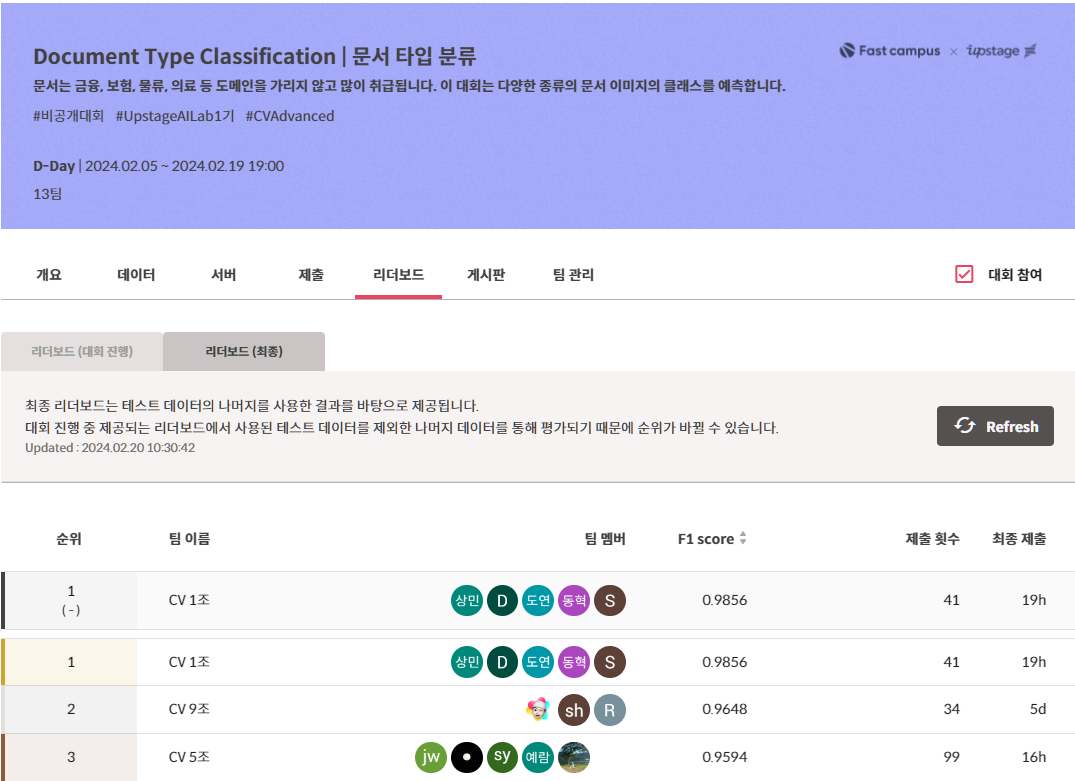
6. Conclusion
- Describe your running code with its own advantages and disadvantages, in relation to other groups in the course.
- 딥러닝 중 Computer Vision 에 대해 배우고 경험하는 시간을 가질 수 있다.
- 여러 문서 이미지를 문서 타입 별로 이미지 분류 하는 방법에 대해 배우고 경험할 수 있다.
- Albumentation 모듈을 활용하여 data augmentation 및 noise 추가 방법에 대해 알 수 있었다.
- image data 에서 train-valid split, Oversampling하는 방법을 적용 해 볼 수 있었다.
- Sum up your project and suggest future extensions and improvements.
- 기존 학습되어진 모델들의 high level layer 부분과 low level layer부분을 나눠서 각각 실험을 해보는 것.
- 테스트셋을 하나하나 구현가능한 데이터 EDA 요구해보임.
- 문서간에 특이점을 다양하게 찾을 수 있도록, 서로 다른 모델이 학습한 image를 conv레이어를 통해 train 데이터로 만들어 재학습.
