이 마지막 장에서,
우리는 실용성과 산업적 사용의 맥락에서 추천 시스템에 대해 논의할 것이다.
지금까지 지식, 콘텐츠, 협업 필터링 기반 엔진 등 다양한 유형의 추천자에 대해 알아봤다.
그러나 실제로 사용될 때, 각 추천자들은 보통 이런저런 단점을 겪는다.
우리는 첫 번째 장에서 이러한 단점(예: 콘텐츠 기반 엔진의 신규성 문제 및 협업 필터의 콜드 스타트 문제)에 대해 논의하였다.
또한 하이브리드 추천자의 개념, 즉 한 모델의 단점과 다른 모델의 장점과 싸우기 위해 다양한 모델을 결합하는 강력한 시스템을 간략하게 소개했다.
이번 챕터에서는 지금까지 구축한 컨텐츠와 협업 필터를 결합한 간단한 하이브리드 추천자를 구축하겠습니다.
당신이 넷플릭스와 같은 웹사이트를 만들었다고 상상해 보세요.
사용자가 동영상을 볼 때마다 사이드 창에 추천 목록을 표시하려고 합니다(예: YouTube).
언뜻 보기에 콘텐츠 기반 추천자가 이 작업에 적합한 것 같습니다. 왜냐하면, 만약 그 사람이 현재 그들이 흥미롭다고 생각하는 것을 보고 있다면, 그들은 그것과 비슷한 것을 보는 경향이 더 강해질 것이기 때문이다.
우리 사용자가 다크나이트를 보고 있다고 합시다.
이것은 배트맨 영화이기 때문에 우리의 콘텐츠 기반 추천자는 품질에 상관없이 다른 배트맨(또는 슈퍼히어로) 영화를 추천할 것 같다.
이것이 항상 최상의 권장 사항으로 이어지는 것은 아닙니다.
예를 들어, 다크나이트를 좋아하는 대부분의 사람들은 배트맨과 로빈이 같은 주인공을 가지고 있음에도 불구하고 그들을 매우 높게 평가하지 않는다.
따라서 여기에 콘텐츠 기반 모델이 추천하는 영화의 등급을 예측하고 예측도가 가장 높은 상위 몇 편의 영화를 돌려주는 협업 필터를 소개한다.
즉, 하이브리드 모델의 작업 흐름은 다음과 같습니다.
1. 동영상 제목과 사용자를 입력으로 가져옵니다.
2. 콘텐츠 기반 모델을 사용하여 가장 유사한 영화 25편을 계산합니다.
3. 협업 필터를 사용하여 사용자가 25편의 영화를 제공할 수 있는 예상 등급을 계산합니다.
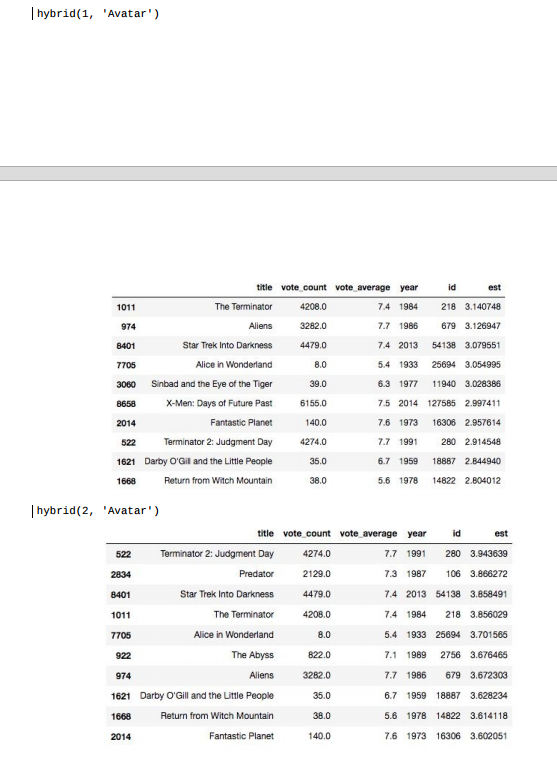
4. 예상 등급이 가장 높은 상위 10개 영화 반환def hybrid(userId, title):
idx = indices[title]
tmdbId = id_map.loc[title]['id']
#print(idx)
movie_id = id_map.loc[title]['movieId']
sim_scores = list(enumerate(cosine_sim[int(idx)]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:26]
movie_indices = [i[0] for i in sim_scores]
movies = smd.iloc[movie_indices][['title', 'vote_count', 'vote_average', 'year', 'id']]
movies['est'] = movies['id'].apply(lambda x: svd.predict(userId, indices_map.loc[x]['movieId']).est)
movies = movies.sort_values('est', ascending=False)
return movies.head(10)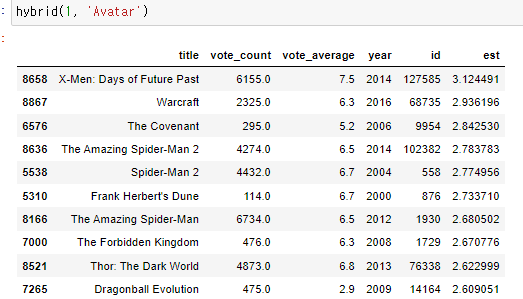
현재 두 사용자 모두 아바타를 시청하고 있지만, 추천 내용은 물론 순서도 다르다는 것을 알 수 있다.
이것은 상호협력 필터의 영향을 받습니다. 하지만 목록에 있는 모든 영화들은 아바타와 비슷하다.
이는 모델에 의해 수행되는 콘텐츠 기반 필터링 때문입니다.