item_based CF
사용자는 서로 유사한 두 항목을 비슷하게 평가할 가능성이 높습니다.
model_based CF
machine learniong 알고리즘을 사용하지 않는다.
협업 시스템은 추천을 만들기 위해 사용자의 평점 패턴의 상관관계를 이용한다.
이는 예측을 계산할 때 아이템의 속성을 이용하지 않는다.
import pandas as pd
import numpy as np
#Load the u.user file into a dataframe
u_cols = ['user_id', 'age', 'sex', 'occupation', 'zip_code']
users = pd.read_csv('../data/movielens/u.user', sep='|', names=u_cols, encoding='latin-1')
users.head()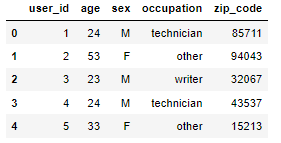
#Load the u.item file into a dataframe
i_cols = ['movie_id', 'title' ,'release date','video release date', 'IMDb URL', 'unknown', 'Action', 'Adventure',
'Animation', 'Children\'s', 'Comedy', 'Crime', 'Documentary', 'Drama', 'Fantasy',
'Film-Noir', 'Horror', 'Musical', 'Mystery', 'Romance', 'Sci-Fi', 'Thriller', 'War', 'Western']
movies = pd.read_csv('../data/movielens/u.item', sep='|', names=i_cols, encoding='latin-1')
movies.head()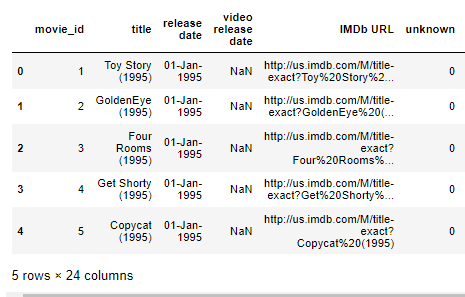
#Remove all information except Movie ID and title
movies = movies[['movie_id', 'title']]movies의 모든 정보가 필요없어서 movie_id와 title을 제외하고 제거
#Load the u.data file into a dataframe
r_cols = ['user_id', 'movie_id', 'rating', 'timestamp']
ratings = pd.read_csv('../data/movielens/u.data', sep='\t', names=r_cols,
encoding='latin-1')
ratings.head()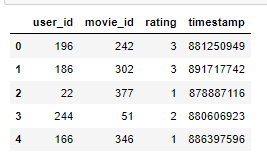
우리가 여태까지 진행한 것은
파일 : /u.user 에서 user의 데이터프레임
파일 : /u.item 에서 moive의 데이터프레임
파일 : /u.data 에서 rating의 데이터프레임
을 가져온 것이다.
#Import the train_test_split function
from sklearn.model_selection import train_test_split
#Assign X as the original ratings dataframe and y as the user_id column of ratings.
X = ratings.copy()
y = ratings['user_id']
#Split into training and test datasets, stratified along user_id
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, stratify=y, random_state=42)이제 학습과 테스트 데이터를 만들기 위해서 split를 진행한다. 75% / 25% 비율로
#Import the mean_squared_error function
from sklearn.metrics import mean_squared_error
#Function that computes the root mean squared error (or RMSE)
def rmse(y_true, y_pred):
return np.sqrt(mean_squared_error(y_true, y_pred))모델의 성능은 RMSE로 측정한다.
#Define the baseline model to always return 3.
def baseline(user_id, movie_id):
return 3.0평가하기 전에 baseline의 경우를 rating이 1~5사이 이므로 3으로 지정한다.
#Function to compute the RMSE score obtained on the testing set by a model
def score(cf_model):
#Construct a list of user-movie tuples from the testing dataset
id_pairs = zip(X_test['user_id'], X_test['movie_id'])
#Predict the rating for every user-movie tuple
y_pred = np.array([cf_model(user, movie) for (user, movie) in id_pairs])
#Extract the actual ratings given by the users in the test data
y_true = np.array(X_test['rating'])
#Return the final RMSE score
return rmse(y_true, y_pred)점수 계산을 위한 함수 score 정의한다.
user_based_CF
#Build the ratings matrix using pivot_table function
r_matrix = X_train.pivot_table(values='rating', index='user_id', columns='movie_id')
r_matrix.head()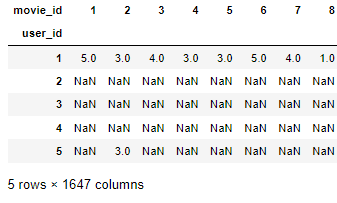
여기서 각 행은 user이고 각 열은 movie입니다.
#User Based Collaborative Filter using Mean Ratings
def cf_user_mean(user_id, movie_id):
#Check if movie_id exists in r_matrix
if movie_id in r_matrix:
#Compute the mean of all the ratings given to the movie
mean_rating = r_matrix[movie_id].mean()
else:
#Default to a rating of 3.0 in the absence of any information
mean_rating = 3.0
return mean_rating간단히 말하면
user_id와 movie_id를 받아들이고서 모든 사람이 동영상의 평균 등급을 출력합니다.
등급을 매긴 사용자입니다. 사용자 간의 차이는 없습니다.
다시말해서: 각 사용자의 등급에 동일한 가중치가 할당됩니다.
#Compute RMSE for the Mean model
score(cf_user_mean)
#Create a dummy ratings matrix with all null values imputed to 0
r_matrix_dummy = r_matrix.copy().fillna(0)nan의 경우를 0으로 모두 채운 r_matrix_dummy
# Import cosine_score
from sklearn.metrics.pairwise import cosine_similarity
#Compute the cosine similarity matrix using the dummy ratings matrix
cosine_sim = cosine_similarity(r_matrix_dummy, r_matrix_dummy)#Convert into pandas dataframe
cosine_sim = pd.DataFrame(cosine_sim, index=r_matrix.index, columns=r_matrix.index)
cosine_sim.head(10)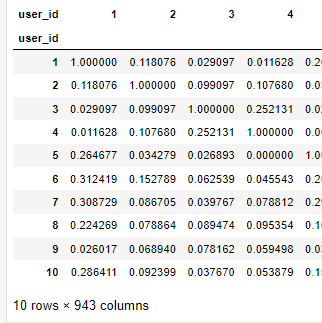
사용자 코사인 유사성 매트릭스를 통해 우리는 이제 이 모델에 대한 가중 평균 점수를 효율적으로 계산할 수 있다.
그러나 이 모델을 코드로 구현하는 것은 단순한 평균 상대보다 약간 더 미묘한 것이다.
이는 Null이 아닌 해당 등급을 가진 코사인 유사성 점수만 고려해야 하기 때문입니다.
즉, 영화 등급을 매기지 않은 모든 사용자를 피해야 합니다.
#User Based Collaborative Filter using Weighted Mean Ratings
def cf_user_wmean(user_id, movie_id):
#Check if movie_id exists in r_matrix
if movie_id in r_matrix:
#Get the similarity scores for the user in question with every other user
sim_scores = cosine_sim[user_id]
#Get the user ratings for the movie in question
m_ratings = r_matrix[movie_id]
#Extract the indices containing NaN in the m_ratings series
idx = m_ratings[m_ratings.isnull()].index
#Drop the NaN values from the m_ratings Series
m_ratings = m_ratings.dropna()
#Drop the corresponding cosine scores from the sim_scores series
sim_scores = sim_scores.drop(idx)
#Compute the final weighted mean
wmean_rating = np.dot(sim_scores, m_ratings)/ sim_scores.sum()
else:
#Default to a rating of 3.0 in the absence of any information
wmean_rating = 3.0
return wmean_rating긍정적인 평가를 다루기 때문에 코사인 유사성 점수는 항상 긍정적입니다.
따라서 정규화 요인(최종 등급이 1과 5 사이로 축소되도록 보장하는 방정식의 분모)을 계산하는 동안 모듈러스 함수를 명시적으로 추가할 필요가 없다.
그러나 이 시나리오에서 음수가 될 수 있는 유사성 메트릭(예: Pearson 상관 점수)을 사용하는 경우 계수를 고려하는 것이 중요합니다.
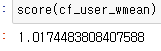
이전 모델에서는 1.0234701463131335 으로 현재 1.0174483808407588 보다 크므로 현재 weighted_mean의 경우가 더 향상했다고 볼 수 있다. 하지만 이는 계산과정이 더 시간이 오래걸린다는 단점을 가지고 있다.
USER demographics
#Merge the original users dataframe with the training set
merged_df = pd.merge(X_train, users)
merged_df.head()
마지막으로 사용자 인구 통계 정보를 활용하는 필터를 살펴보겠습니다.
이러한 필터의 이면에 있는 기본적인 직관은 동일한 인구통계학적 사용자들의 취향이 비슷한 경향이 있다는 것이다.
그러므로, 그들의 효과는 여성들, 십대들, 또는 같은 지역 출신의 사람들이 영화에서 같은 취향을 공유할 것이라는 가정에 달려 있다.
#Compute the mean rating of every movie by gender
gender_mean = merged_df[['movie_id', 'sex', 'rating']].groupby(['movie_id', 'sex'])['rating'].mean()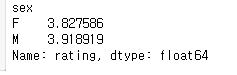
다음으로, 우리는 각 영화의 성별에 따른 평균 등급을 계산해야 한다.
#Set the index of the users dataframe to the user_id
users = users.set_index('user_id')우리는 이제 사용자의 성별을 식별하고, 해당 성별에 의해 해당 영화에 주어진 평균 등급을 추출하고, 그 값을 출력으로 반환하는 함수를 정의해야 한다.
#Gender Based Collaborative Filter using Mean Ratings
def cf_gender(user_id, movie_id):
#Check if movie_id exists in r_matrix (or training set)
if movie_id in r_matrix:
#Identify the gender of the user
gender = users.loc[user_id]['sex']
#Check if the gender has rated the movie
if gender in gender_mean[movie_id]:
#Compute the mean rating given by that gender to the movie
gender_rating = gender_mean[movie_id][gender]
else:
gender_rating = 3.0
else:
#Default to a rating of 3.0 in the absence of any information
gender_rating = 3.0
return gender_ratingscore(cf_gender)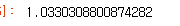
우리는 이 모델이 실제로 표준 평균 등급 협업 필터보다 성능이 떨어진다는 것을 알 수 있다.
이는 사용자의 성별이 가장 강력한 지표가 아님을 나타냅니다.
그들의 영화 취향이요.
#Compute the mean rating by gender and occupation
gen_occ_mean = merged_df[['sex', 'rating', 'movie_id', 'occupation']].pivot_table(
values='rating', index='movie_id', columns=['occupation', 'sex'], aggfunc='mean')
gen_occ_mean.head()피벗_table 메서드가 필요한 데이터 프레임을 제공한다는 것을 알 수 있습니다.
하지만, 이것은 groupby를 사용해서도 할 수 있었습니다. pivot_table은 단순히 메소드별로 그룹을 위한 더 작고 사용하기 쉬운 인터페이스입니다.
#Gender and Occupation Based Collaborative Filter using Mean Ratings
def cf_gen_occ(user_id, movie_id):
#Check if movie_id exists in gen_occ_mean
if movie_id in gen_occ_mean.index:
#Identify the user
user = users.loc[user_id]
#Identify the gender and occupation
gender = user['sex']
occ = user['occupation']
#Check if the occupation has rated the movie
if occ in gen_occ_mean.loc[movie_id]:
#Check if the gender has rated the movie
if gender in gen_occ_mean.loc[movie_id][occ]:
#Extract the required rating
rating = gen_occ_mean.loc[movie_id][occ][gender]
#Default to 3.0 if the rating is null
if np.isnan(rating):
rating = 3.0
return rating
#Return the default rating
return 3.0우리는 이 모델이 우리가 지금까지 구축한 모든 필터 중 기준선만 제치고 가장 성능이 떨어지는 것을 본다.
이는 사용자 인구 통계 데이터를 조작하는 것이 현재 우리가 사용하고 있는 데이터를 진행하기 위한 최선의 방법이 아닐 수 있음을 강력하게 시사한다.
그러나 무엇이 가장 잘 수행되는지 보기 위해 다양한 순열과 사용자 기록 정보의 조합을 시도해 보는 것이 좋습니다.
또한 pivot_table의 aggfunc에 가중 평균을 사용하고 서로 다른 기본 등급(아마도 더 많은 정보를 제공)으로 실험하는 것과 같은 다른 모델 개선 기술을 시도해 보는 것이 좋습니다.
