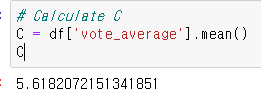
# Calculate C
C = df['vote_average'].mean()
C현재 vote_average에 있는 값의 mean() # 평균값 계산
# Function to compute the IMDB weighted rating for each movie
def weighted_rating(x, m=m, C=C):
v = x['vote_count']
R = x['vote_average']
# Compute the weighted score
return (v/(v+m) * R) + (m/(m+v) * C)내가 가지고 있는 데이터프레임에서 가중치score를 주기 위해 계산한다.
v = 데이터프레임['vote_count']
R = 데이터프레임['vote_average']
m = 50 ## 45,000개 중에서 9,000개인 20%만 가져온다. (백분위 기준 80%에 해당하는 값)
C = 데이터프레임['vote_average']의 mean값으로 5.6182072151341851 값이다.
계산하는 함수는 weighted_rating 이다.
이는 영화별 각 평점과 투표수를 가중치 점수로 만들기 위함이다.
자세히 보면
((투표수 /(투표수 + 50)) 메긴 평점) + ((50 / (50 + 투표수)) 평점의 평균값 )
이다.
# Compute the score using the weighted_rating function defined above
movies_20percent['score'] = movies_20percent.apply(weighted_rating, axis=1)기존의 데이터 프레임인 movies_20percent에 새로운 축 (axis=1 열)에 apply 된다.
이제
#Sort movies in descending order of their scores
movies_20percent = movies_20percent.sort_values('score', ascending=False)을 진행하여 score 별로 내림차순을 진행한다. 가장 높은게 맨 위
결과를 출력해보면
#Print the top 10 movies
movies_20percent[['title', 'vote_count', 'vote_average', 'score', 'runtime']].head(10)top 10개의 값들만 내가 가져와서 추천해줄 수 있다.
여기까지는 간단한 recommendation system 이다.

행복을 찾아서(크리스 가드너)