Generative Adversairal Network의 대한 이야기
생성자와 구별자
-
생성자는 구별자를 더 잘 속이도록 학습되어, 실제 데이터와 유사한 가짜 데이터를 생성함.
-
구별자는 가짜 데이터로부터 실제 데이터를 더 잘 구별하도록 설계한다.
Objective Function of GANs
1. Discriminator(D)의 loss func

-
파란식 : 실제 데이터에 대한 것
-
빨간식 : 가짜 데이터에 대한 것
p_data : 실제 데이터의 분포
p_z : lantent vector의 분포 : 가우시안 혹은 uniform한 분포
-
극단적 예시 :
D(판별자)가 잘 구별하는 모델이라면, 최대값 0을 가지게 됨.
파란식 0 -----------> (D(x) =0)
빨간식 0 -----------> (D(G(Z)) = 0)
2. Generatior(G)의 loss func
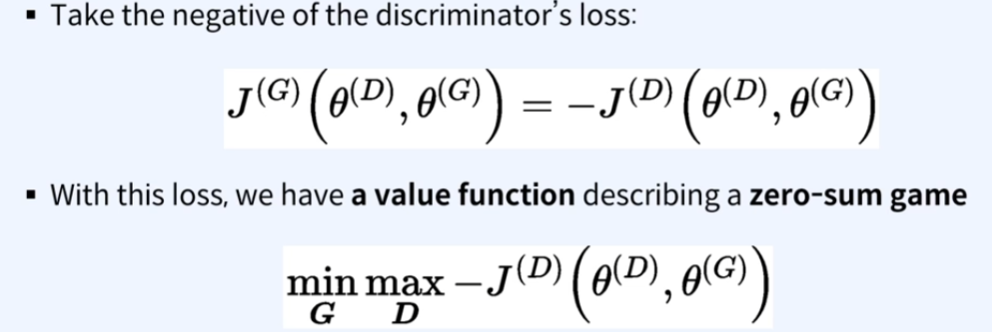
- Discriminator(D)의 loss func에다가 음수값으로 표현함.
- 생성자는 실제 데이터와 유사하게 만들어서, 실제 데이터로 속게끔하여 1를 반환하도록 하는 것임. 이를 통해 앞서 빨간식의 뒷 부분이 1이 되게하여 log 0가 되고, 이는 음수값을 가지게 되므로, 판별자의 loss가 최소가 되고, 생성자 G의 loss는 최대가 됨.
학습은 결국 min max의 value func를 풀게 됨.
GAN Training Process
- 먼저 구별자 모델을 m개의 미니배치에서 샘플링해서, k번 업데이트 진행한 후, 생성자의 모델이 업데이트 됨

-
생성자는 tanh()
-
판별자는 sigmoid()
이미지
- -1에서 1사이로 스케일링생성자 학습
초기 생성자는
- uniform(-1, 1)사이의 값으로 LATENT_DIM만큼 torch.zeros로 생성
생성자 모델
- 초기 생성자의 값을 생성자 모델에 집어넣음. fake데이터
판별자 모델
- 초기 생성자 값을 넣어, pred(0과 1 둘 중에 하나의 값으로 예측함)를 가져오고서, binary_cross_entropy를 계산하는데, 판별자가 잘 판별하게 된다면 1로 예측하게 되고, 잘 못하게 되면 0이 된다.
생성자의 loss
- 판별자가 binary_cross_entropy의 값을 이용하여, 역전파를 진행함.판별자 학습
- 실제 이미지의 값(-1과 1사이의 uniform된 값)을 판별자 모델에 넣음.
- 판별자 모델에 넣은 실제 이미지들로 pred한 것을 binary_cross_entropy을통해서 real_loss를 계산.
- 다시 생성자 모델에 넣었던 fake데이터를 판별자 모델에 넣고서, binary_cross_entropy을통해서 fake_loss를 계산.
- real_loss와 fake_loss를 sum후에 1/2한다.
- discr_loss를 이제 역전파하여 학습
행복을 찾아서(크리스 가드너)