1일차에 해당하는 패스트캠퍼스 AI업스테이지의 내용을 공부하기 위하여
공부한 자료를 나중에 다시 보기 위하여 저 혹은 다음에 공부하실 분들과 공유하여 드립니다. 저작권의 문제 때문에, 사진과 자세한 내용 보다는 제가 배우고 느낀 감정, 혹은 나중에 공부할 때, 알아볼 수 있을 정도로 정리할 예정입니다.
추천책
[나의 커리어 치트키 데이터 분석 유치원] - 패스트 캠퍼스
파트3 통계로 데이터분석 능숙해지기 :: 챕터3 - 기술통계
1. 모집단과 표본
모집단 : 현재 내가 통계를 통해서 알고자 하는 것들의 모든 집단 모집단
모수 : 모집단의 평균, 분산, 표준편차, 즉 알고자 하는 것의 모든 것의 특성을 의미.
표본 : 모집단에서 추출한 것
통계량 : 표본의 평균, 분산, 표준편차, 즉 모집단에서 몇개를 추출한 것들의 특성을 의미
--- 샘플링 방법 ---
확률 표본 추출
[[[
단순 샘플링, 랜덤으로 샘플을 추출한 것
층화 샘플링, 모집단을 몇개의 그룹(표본)들을 가지고서, 표본들의 랜덤으로 n개씩 추출
계통 샘플링, 모집단을 임의로 순서인 등번을 메기고서, 일정 간격마다 데이터 추출
군집 샘플링, 모집단 데이터를 클러스터로 분할하고서, 군집 여러개 or 1개을 선택 후 사용
]]]
2.정규분포와 중심극한정리
정규분포 : 평균에 대하여 좌우 대칭이며, 평균에서 최대값, 가우시안 모양을 가진다.
중심극한정리 :
1. 표본의 크기가 커질수록 표본의 평규 분포는 모집단의 분포 모양과는 관계없이 정규분포에 가까워진다.
2. 추가로 표본 평균들의 평균을 구하면, 모집단의 평균과 같으며,
표본 평균의 표준편차 = 모집단 표준편차 /
3. 카이제곱 분포
"" 데이터가 카이제곱 분포의 특징을 따른다면, 카이제곱 분포로 귀무가설의 기각과 채택을 선택한다.
"" 분산의 특징을 확률 분포로 음수가 없음( 0 이하가 없음) -- why? 제곱이기 때문에
"" 자유도가 높을수록(df == lambda) 정규분포에 근접해진다.
"" t-분포는 모분산을 모를때, 모평균을 구하는데, 카이제곱은 모분산을 구하는 것임.
4. t-분포
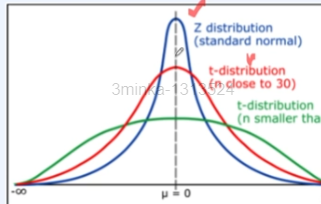
"" 모분산을 모르고, 소규모 표본(30개 이하)에서 모 평균을 구하는 것
"" 정규분포는 양쪽 시그마(표준편차)가 t-분포보다 더 낮음, 즉 t-분포가 조금더 양쪽이 더 높다는 것
5. F 분포(F - Fisher 분포)
"" t-분포는 3개 이상의 집합에서는 검정이 불가하므로 F분포로 검정(귀무가설을 기각 채택함)
"" 분산을 다루어서 진행한다. 주로 분산 분석에서 사용된다.

#강의. Dane Ahn 강사님
이제부터 Dane Ahn 강사님의 배움에 대한 고찰을 정리하는 시간
통계 : 수요예측모델 개발 및 운영
회사의 핵심 업무로, 핵심 가치와 서비스를 고객에게 제공하기 위한 많은 리소스(자원)를 사전에 준비하여, 이를 적재적소에 투입하려한다.
"" 데이터사이언스의 주역할에서 ""
주문처리 및 배송
물류 프로세스와 상품/부자재 재고관리
1%의 정확도로 물류 비용의 증감에 큰 영향을 미침.
"수요예측모델의 정확도"
예측값과 실제값의 차이가 얼마나 적은지 MAPE, RMSE(root MSE)
정확도에만 집중하기 보다는 실제 모델을 활용 운영하는 협업관점에서의 모델 개발요구.
1. 확률(pdf 밀도 vs pmf 질량)
pmf - 비연속성, 시그마(합) p(x), 모든 x에 대해서 다 더하면 1
pdf - 연속성, f(x)를 적분, 음의 무한 ~ 양의 무한까지 적분하면 1
pmf의 cdf는 각각의 처음부터 x까지 모두 누적된 값
pdf의 cdf도 마찬가지 누적된 값
확률변수의 모수를 추정하므로, 확률변수에 따라 데이터가 달라진다. (실현)realize
< pmfs 질량-비연속성>
- 균일 분포(주사위), a - b까지의 최소(모수) - 최대(모수)가 존재한다. 총 갯수 n = b-a+1
- 베르누이 분포(True or False) 동전1개, 확률 p라는 하나의 모수가 존재함. 재고량변화.
- 이항 분포 - 동전 10개, 다수의 베르누이 합친것, 확률 p와 시행횟수 n(모수)이 존재.
- 포아송 분포 - 1시간에 방문하는 고객의 수, 모수는 평균 1개, 분산=평균 (n, 모수가 없음)
- 밴포드 분포 - 집단의 사람들 중에 1이 가장 많을 것이다.
-- 분포 --
베르누이 분포에서의 동전이 딱 세워지거나, 새가 없애버릴 확률, 편향에 치우지거나, 지구가 사라지는 극히 드물거나 희귀한 상황을 제외한 상황이 있다.
하지만 현실세계에서는 벌어질수도 있지만, 극히 드물다고만 할 수 있다.
< pdfs 밀도-연속 >
- 균일분포 - 2개의 모수가 존재, n=b-a+1
- 정규분포 - 평균과 분산인 2개의 모수, 가우시안 분포,
- 중심극한정리 - 정규분포가 아닌 다양한 분포에서 평균을 구할때, 분포에서 평균을 내는 것, 모집단의 데이터 n이 늘어난다고 정규분포가 되는 것이 아닌, 분포의 평균들의 평균이 정규분포가 되는 것. 문제는 이상치, 첨도에 따라 달라지기에 주의요망.
- t-분포 - 평균과 자유도(v, df=고정되지 않는 변수), 정규분포를 이용해 평균을 추정시 분산을 사용하는 분포.
- 카이제곱-분포 - 오차와 분산과 관련된 분포, k(자유도)인 1개의 모수, k(자유도)개의 표준정규분포를 제곱하여 sum한 분포
- F(피셔)분포 - 2개의 카이제곱 분포의 비율로 정의되는 분포, 각 2개의 카이제곱의 자유도(k1, k2)인 모수 2개.
- 코시 분포 - 평균이 무한
정규분포를 사용하는 것의 문제로,
이상치가 가장 큰 요인이라 판단한다. ex) 구글봇의 클릭과 사용자의 클릭을 어떻게 할것인지.
구글 검색에서, 매출로는 지표를 분석하기에 이것도 요인이 된다. 추천에서는 매출을 많이 보는데, 광고가 많기에 매출은 많아지는데, 장기적으로 볼때, 광고가 많으면 사용자들이 떠나는 문제들이 발생한다. log변환된 정규분포, cut된 정규분포, 라플라스, t-분포, 톰슨(thompson)-분포, 베이지안(beta분포)
CLT(중심극한정리)의 가정 - 동일, 독립
iid - identically(동일) 모수가 같다는 것 + independent(독립) 확률변수가 서로 영향없음.
표준편차를 기준으로, 데이터의 퍼짐 정도를 확인한다.
변환 Transformation - log변환한 분포, 등등 +1하고서 분포를 변환하는 것
< 근사 Approximation >
- @ 이항분포에서
n이 무한으로 가면, 포아송분포가 된다. 혹은 n=1이 되면 베르누이분포가 된다. - @ 정규분포에서
자유도가 무한으로가면, t-분포가 된다. - @ t-분포에서
제곱을 진행하면, f-분포가 된다. - @ f-분포에서
k1(자유도1)이 X, k2(자유도2)가 무한으로가면, 카이제곱-분포가 된다.
