- LM Studio에서 로컬로 실행하는 LLM 서버를 기반으로 RAG를 구현하는 것을 목표로 한다.
- 이 글에서는 langchain과 LM Studio를 이용한 embedding, loader, vector store에 관해 다루고자 한다.
RAG 란?
-
RAG는 Retrieval Augmented Generation의 약자로, 지식 검색과 언어 생성 모델을 결합한 형태로 직역하면 검색 증강 생성이다.
-
RAG 모델은 다음과 같이 동작한다.
- 질문을 입력받음
- 질문을 임베딩하여 벡터로 표현
- 사전에 벡터저장소에 저장된 문서 벡터들과 질문 벡터 간의 유사도를 계산
- 유사도가 높은 상위 k개의 문서를 검색
- 검색된 관련 문장들과 원래 질문을 템플릿에 삽입하여 프롬프트를 완성
- 프롬프트를 LLM에 넣어 최종 답변 생성
-
이를 통해 기존 언어모델의 지식 부족 문제를 보완할 수 있다.
RAG 과정
- 문서 벡터화 과정은 다음과 같다.
- 문서 불러오기
- 문서를 청크 단위로 나누기
- 임베딩 모델을 이용하여 각 청크를 벡터로 변환
- 벡터저장소에 저장
검색방법
- 정보의 검색은 벡터저장소 내의 데이터를 검색한다.
- 저장된 문서(문장)벡터'들'과 질문 벡터를 유사도 비교하여 상위 k개를 뽑는다.
- 물론 문장(value)과 문장벡터(key)는 같이 저장된다.
- 문장 k개와 질문을 템플릿에 넣어 프롬프트를 완성하면 이후 과정은 아래 그림과 같다.
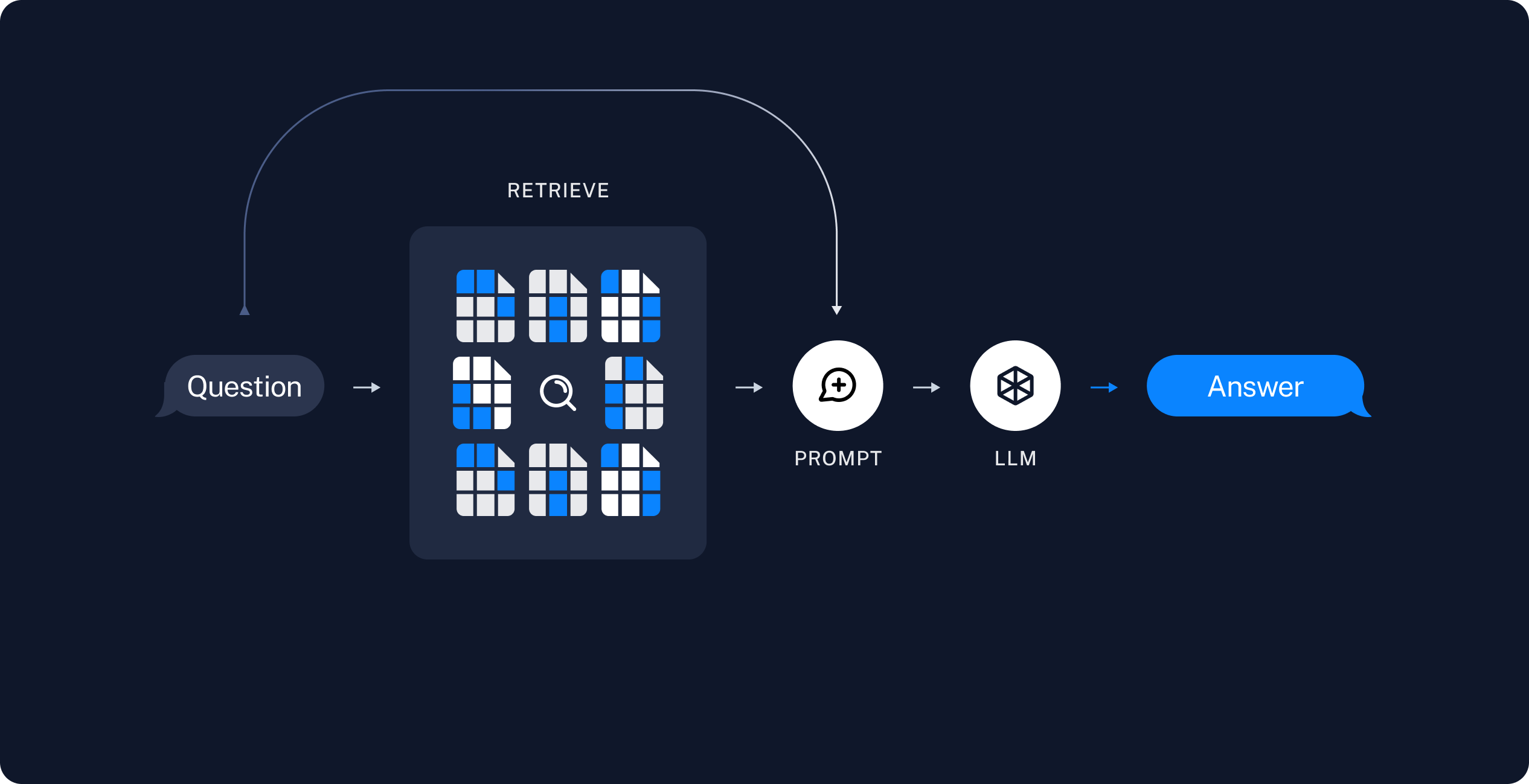
저장방법
- 그러면 벡터저장소에 문서를 어떻게 저장하는가?
- 먼저 문서의 데이터를 불러온다.
- 데이터를 청크단위로 분리한다. 단, 분리된 데이터 간 overlap을 주어 단절의 간극을 메운다.
- 각 청크를 임베딩 모델에 넣어 문장의 벡터(청크의 벡터)를 구한다.
- 각 문장 벡터를 vector store(벡터저장소)에 저장한다.
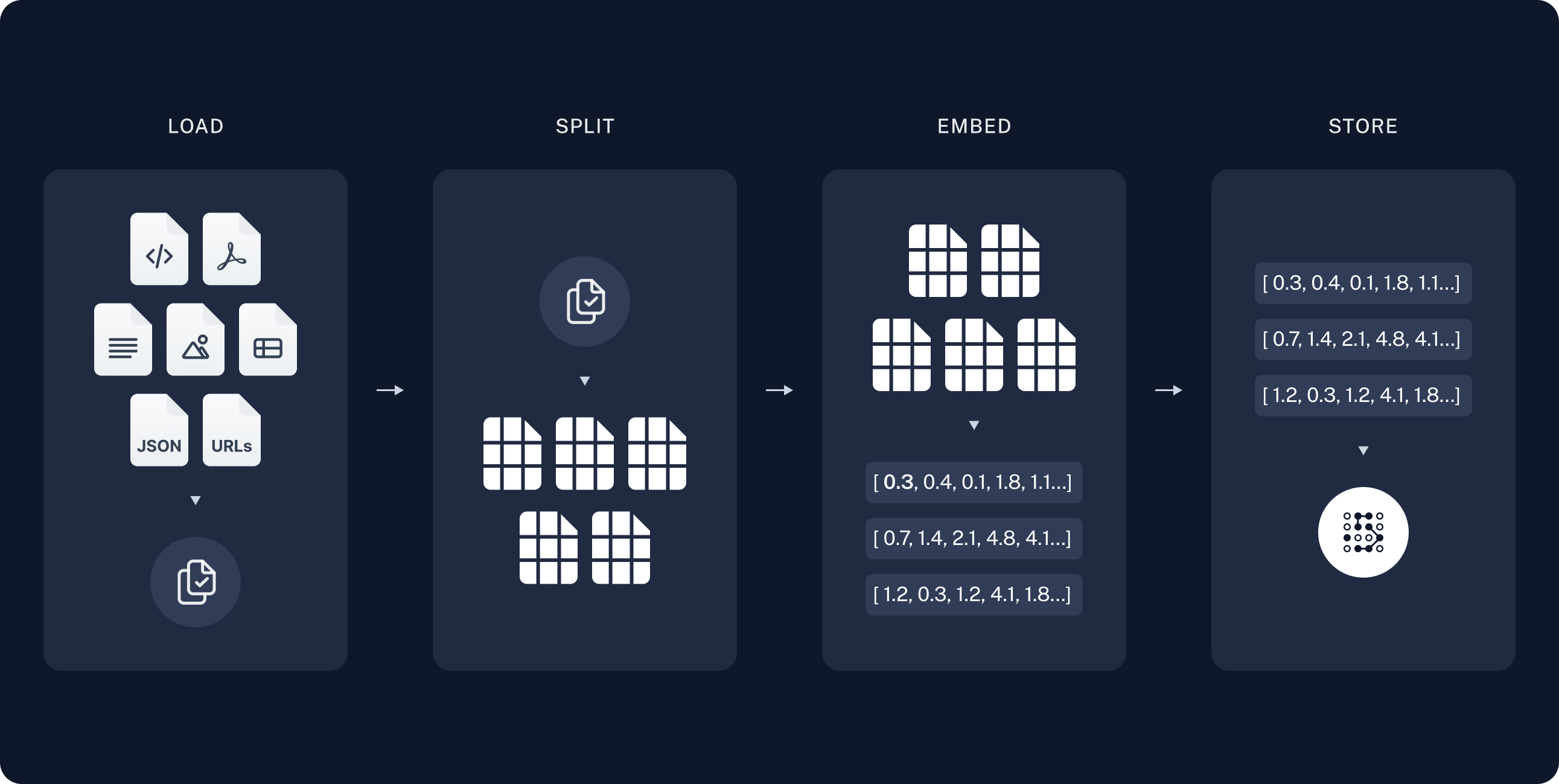
언어모델 Embedding layer 와 RAG Embedding model 차이
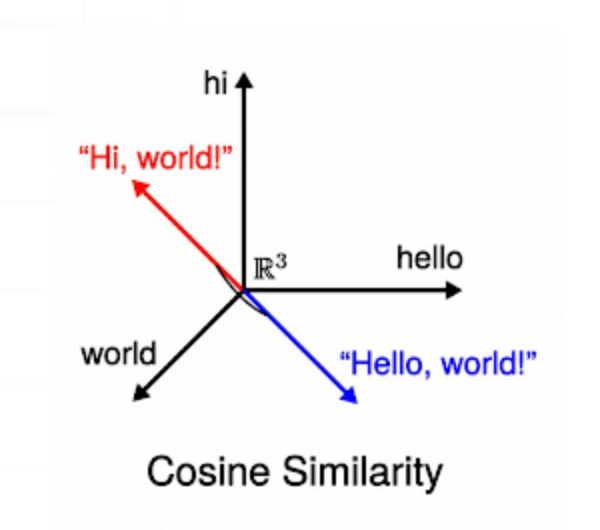
- 언어모델의 Embedding layer는 한 단어(토큰)을 하나의 벡터로 변환한다.
- RAG의 Embedding 모델은 문장(청크)를 하나의 벡터로 변환한다.
세상 모든 문장을 RAG의 Embedding 모델에 담지는 못했을 테니
한 문장(청크)의 여러 단어(토큰)벡터의 합이나 평균 벡터가 하나의 문장(청크)의 벡터가 될 것이다.속도를 위해서 인지 보통 RAG Embedding model의 차원이 더 적다.- 찾아보니 Transformer 구조를 사용하는 등 모델로 동작한다.
말그대로 Embedding model 이다.
문서 불러오기 & 청크 단위로 나누기
- 문서 불러오기는 간단하다.
- 아래 코드로 불러오면 된다.
from langchain.document_loaders import TextLoader
loader = TextLoader('./test.txt')
data = loader.load()from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader('./test.pdf')
data = loader.load()- 청크 단위 분할
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
splits = text_splitter.split_documents(data)- 다음 처럼 overlap 부분을 확인할 수 있다.
Embedding 모델 고민하기
HuggingFaceEmbeddings
- URL이나 API KEY 없이 코드를 실행하면 모델 다운로드가 진행되며 이후에 벡터로 변환된다.
- 필자는 LM Studio에서 로컬 서버 실행하면 임베딩 모델에 접근 가능한데
굳이 또 다른 임베딩 모델을 다운로드해야하나 싶어서 짜친다고 느꼈다.
from langchain.embeddings import HuggingFaceEmbeddings
emb_model = HuggingFaceEmbeddings()
emb_vectors = emb_model.embed_documents([
"안녕하세요.",
"반갑습니다.",
"감사합니다.",
])
print(emb_vectors[0][:4])
print(emb_vectors[1][:4])
print(emb_vectors[2][:4])[0.027147486805915833, -0.026235118508338928, -0.007166501134634018, -0.013591941446065903]
[0.021758336573839188, -0.010354320518672466, -0.01736270636320114, -0.003526697400957346]
[0.041674066334962845, -0.002426356775686145, 0.0019095540046691895, -0.0034480998292565346]OllamaEmbeddings 사용?
- 아래 코드를 실행해보았지만 돌아오는 것은 에러였다.
from langchain.embeddings import OllamaEmbeddings
emb_model = OllamaEmbeddings(base_url='http://localhost:1234/v1',)
emb_model.embed_query('test')- LM Studio에서 로그를 확인해보니 잘못된 URL로 접근을 한다.
- http://localhost:1234/v1/embeddings 에 접근해야 한다.
- 내부 소스코드 URL 잠깐 변경하여 접근 해보았지만 POST body 형식이 서버가 바라는 형식과 달랐었다.

OpenAIEmbeddings 사용?
- https://lmstudio.ai/docs/local-server 에서 요청과 응답은 OpenAI의 API 형식을 따른다고 한다.
- 그래서 기대를 갖고 아래 코드를 실행해 보았다.
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(base_url="http://localhost:1234/v1", api_key="lm-studio", )
embed = embeddings.embed_documents([
"안녕하세요.",
"반갑습니다.",
])
print(emb_vectors[0][:4])
print(emb_vectors[1][:4])- LM Studio의 로그를 살펴보니 'input'의 값이 array of strings 이어야한다고 한다.
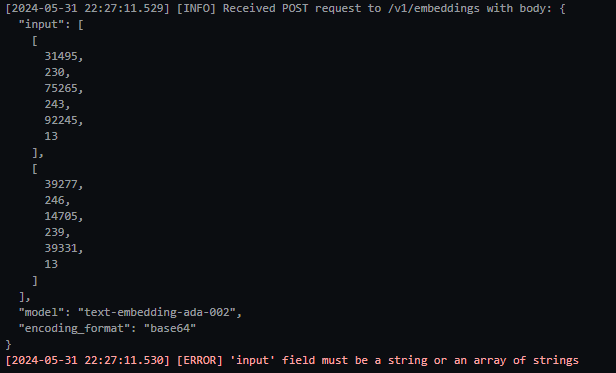
- LM Studio에 주어진 코드를 테스트해서 로그를 다시 확인해보자.
# Make sure to `pip install openai` first
from openai import OpenAI
client = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")
def get_embedding(text, model="nomic-ai/nomic-embed-text-v1.5-GGUF"):
text = text.replace("\n", " ")
return client.embeddings.create(input = [text], model=model).data[0].embedding
print(get_embedding("Once upon a time, there was a cat."))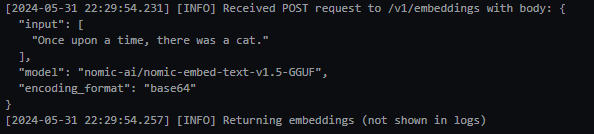
- OpenAIEmbeddings는 왜 tokenize해서 POST 보내는지 모르겠다.
- HuggingFaceEmbeddings와 같은 방식과 URL 방식을 혼용해서 사용하는 듯하다.
LM Studio에 주어진 코드 왜 사용안함?
- LM Studio에 친절하게 URL로 접근하여 embedding model 사용하는 예시 코드가 있다.
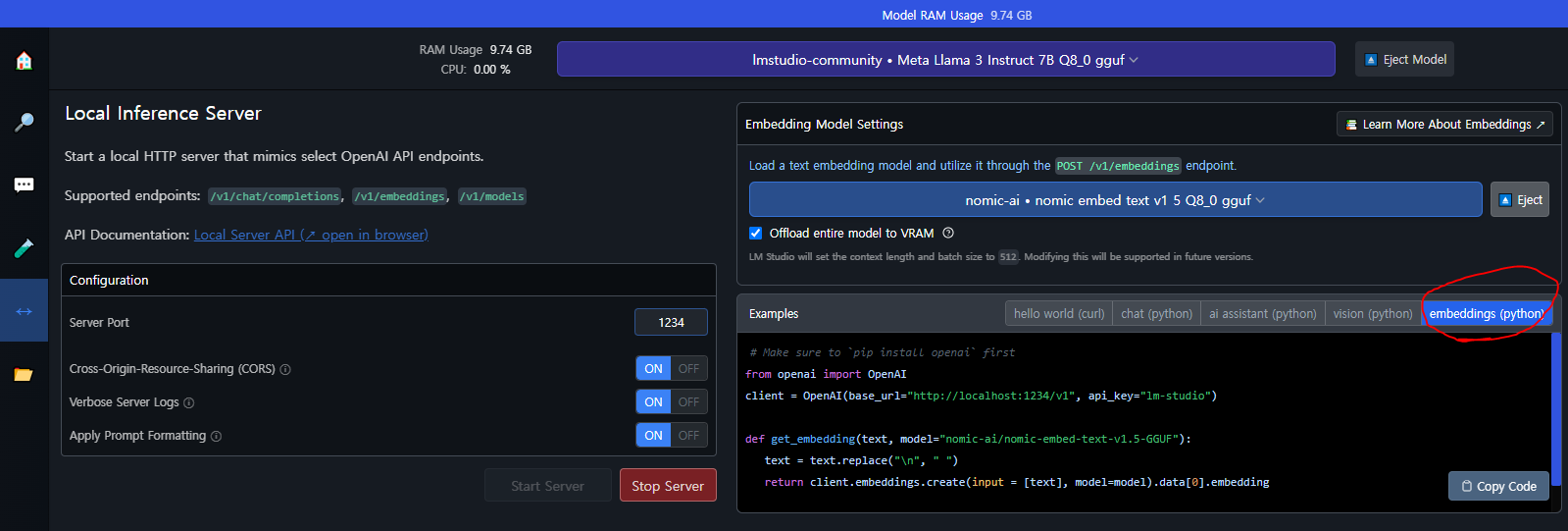
- 문제는 langchain과 호환이 어렵다.
- vector store로 FAISS 또는 Chroma를 사용할 생각인데
- 내부 소스코드를 살펴보니 아래 그림처럼 특정 메서드가 있는 객체를 필요로 한다.
site-packages / langchain_community / vectorstores / chroma.py
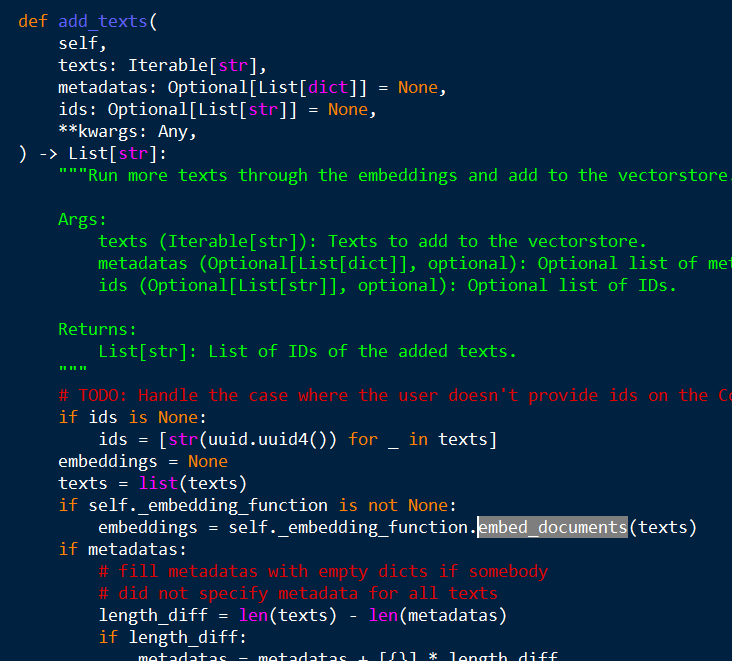
site-packages / langchain_community / vectorstores / faiss.py
- Embeddings 클래스를 상속 받았는지 검사도 한다.

LM Studio의 Embedding Model 사용하기
- LM Studio에 주어진 코드를 변형하여 langchain의 vectorstore들에 잘 녹아들 객체를 만들고자 한다.
- 초안
from langchain_core.embeddings import Embeddings
class MyEmbeddings(Embeddings):
def __init__(self):
pass
MyEmbeddings()- 에러를 보니 위에서 보았던 embed_documents와 embed_query 메서드만 만들면 되나보다.

- embed_query는 무엇인가 보니 간단하다.
site-packages / langchain_community / embeddings / openai.py
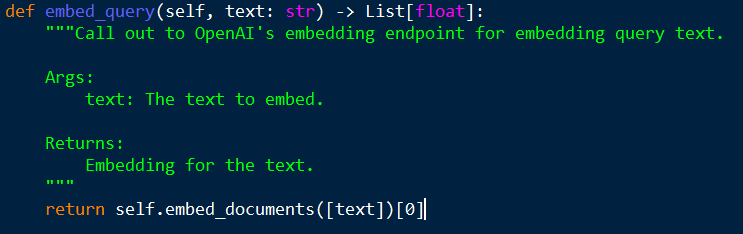
- 그러면 완성해보자.
from langchain_core.embeddings import Embeddings
from openai import OpenAI
from typing import List
class MyEmbeddings(Embeddings):
def __init__(self, base_url, api_key="lm-studio"):
self.client = OpenAI(base_url=base_url, api_key=api_key)
def embed_documents(self, texts: List[str], model="nomic-ai/nomic-embed-text-v1.5-GGUF") -> List[List[float]]:
texts = list(map(lambda text:text.replace("\n", " "), texts))
datas = self.client.embeddings.create(input=texts, model=model).data
return list(map(lambda data:data.embedding, datas))
def embed_query(self, text: str) -> List[float]:
return self.embed_documents([text])[0]
emb_model = MyEmbeddings(base_url="http://localhost:1234/v1")- 잘 작동한다.
- 이후에 langchain의 vectorstores에서도 작동하는 것을 확인했다.
emb_model = MyEmbeddings(base_url="http://localhost:1234/v1")
emb_vectors = emb_model.embed_documents([
"안녕하세요.",
"반갑습니다.",
"감사합니다.",
])
print(emb_vectors[0][:4])
print(emb_vectors[1][:4])
print(emb_vectors[2][:4])[-0.009379313327372074, 0.006728439126163721, -0.13962389528751373, -0.0276948232203722]
[0.028088465332984924, 0.011738881468772888, -0.12221366167068481, -0.015201573260128498]
[0.023225707933306694, 0.018655113875865936, -0.14380981028079987, -0.019437212496995926]
벡터 저장소에 저장하기 & 검색하기
- 위의 청크 분할 코드에서 청크 사이즈를 조절해준다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=50)
splits = text_splitter.split_documents(data)- 아래 코드에서 invoke를 사용하여 관련내용을 검색해 볼 수 있다.
from langchain.vectorstores import FAISS
from langchain.vectorstores.utils import DistanceStrategy
vectorstore = FAISS.from_documents(splits, embedding=emb_model,
distance_strategy=DistanceStrategy.COSINE)
retriever = vectorstore.as_retriever()
retriever.invoke('framework 관련 내용')from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(splits, emb_model)
retriever = vectorstore.as_retriever()
retriever.invoke('framework 관련 내용')