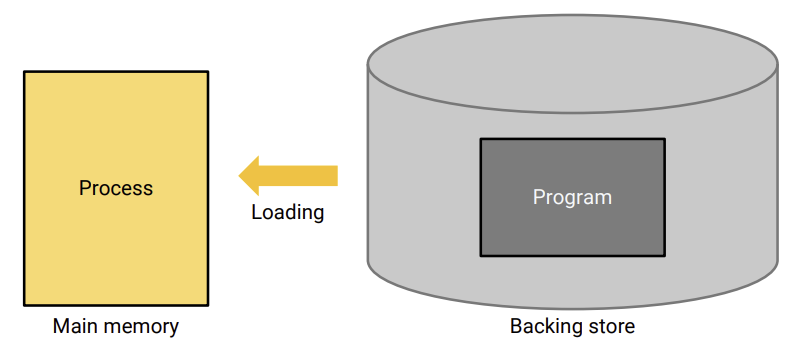
swapping
우리가 프로그램을 실행하기 위해서는 SSD나 HDD 같은 storage device에서 메모리로 프로그램이 모두 올라와야 첫 instruction을 실행할 수 있다.
그렇다면 만약 파일 용량이 커서 메모리로 올리는데 까지만 10초가 걸린다면, 10초동안 cpu는 아무일도 하지 못하고 기다리게 된다.
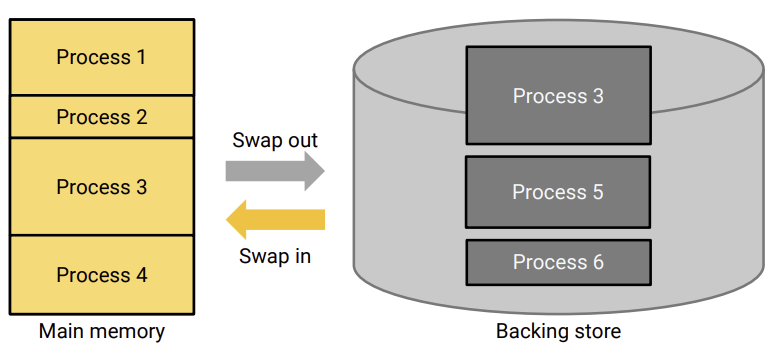
이렇게 쓰지 않는 process를 통째로 storage에 옮기고 써야 하는 process를 통째로 메모리로 올리는 것을 swapping 이라고 한다.
문제는 process를 통째로 빼고 넣고 하는게 너무 오래 걸린다는 것이다.
그래서 생각해낸게 Demand paging이다.
process를 전체다 loading하는게 아니라 paging 처럼 그때그때 사용할 것들만 loading을 한다. 실행은 가능한 상태이기 때문에 더 빠르게 실행할 수 있다.
또 하나의 장점은 process를 실행할때, 잘 사용되지 않는 코드들은 아예 메모리로 올리지 않아서 메모리를 더 효과적으로 사용할 수 있게 된다.
위 그림을 예로 들면, process4를 실행한다고 하면, 필요한 부분만 memory에 올리는데 process1의 사용되지 않는 부분을 store로 빼놓고 그 부분에 process4의 일부분이 들어가 있는 것이다. 결국, 여러 프로세스의 일부분들이 섞여서 실행된다.
demand paging
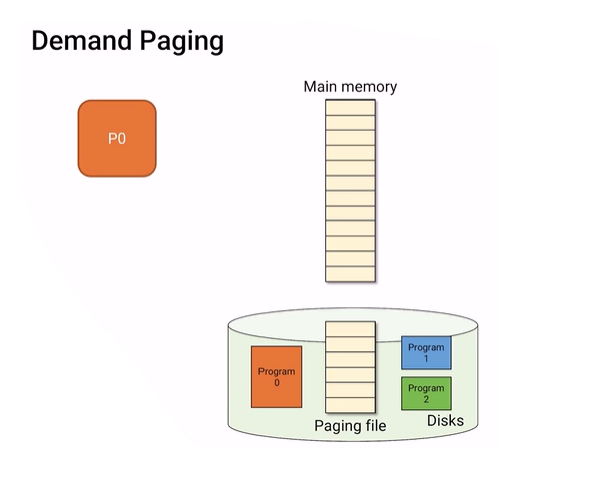
맨처음에 p0를 실행하면 아무것도 없는 page table이 만들어진다.
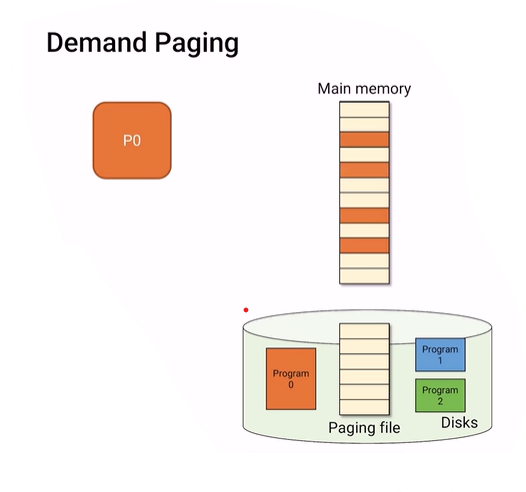
p0이 page가 필요할때마다 OS가 memory에 page를 하나씩 올려준다.
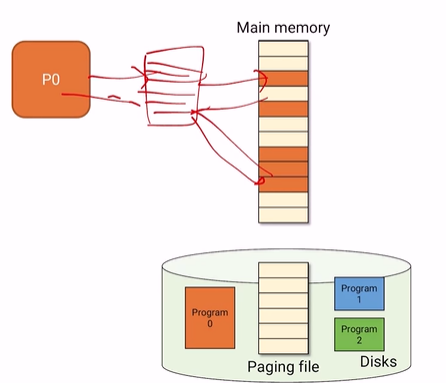
그러면 page table에서 VP와 PF가 맵핑된다.
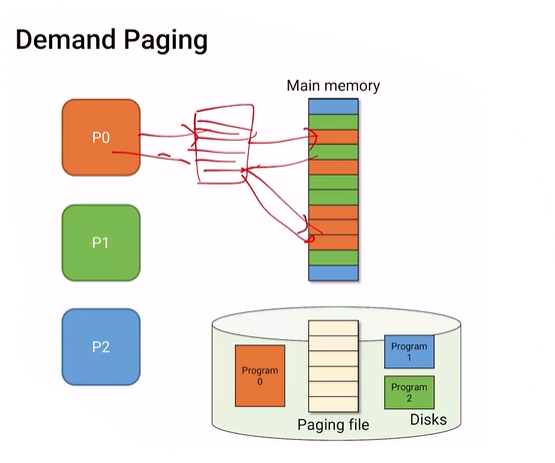
program 1,2,3을 모두 돌린다면, 위와 같이 실행하는데 필요한 page만 가지고 오게 된다.
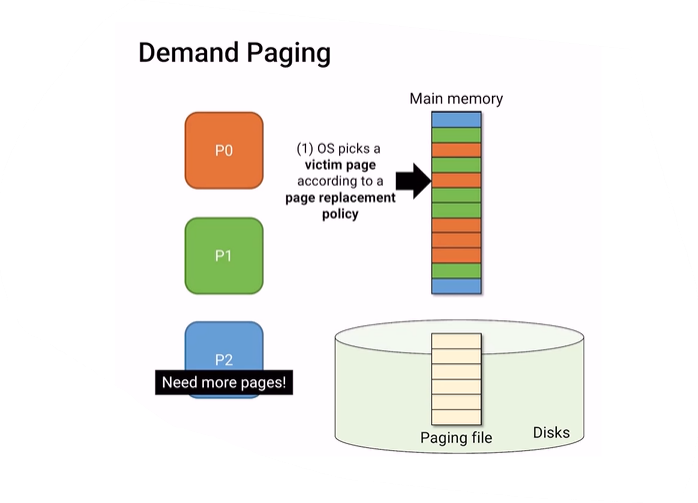
page를 계속 가지고 오다보면 memory는 한계가 있기 때문에 공간을 비워줘야만 다른 page를 가지고 올 수가 있다. 비워주려고 하는 page를 victim page 라고 부른다.
그 victim page를 찾아서 그냥 날려버리면 victim page가 가지고 있는 소중한 데이터가 없어지기 때문에 그냥 날릴수는 없다. 그래서 이 victim page를 저장할 공간이 필요한데
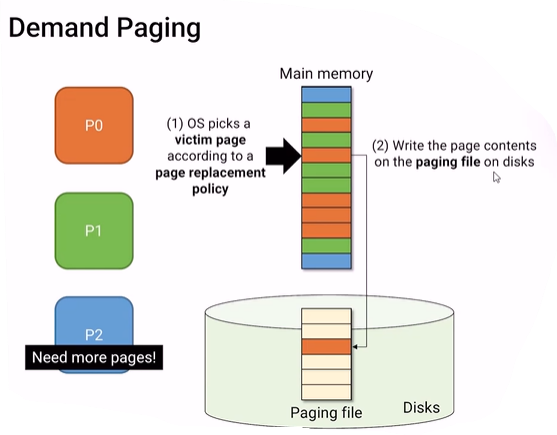
그게 바로 pagine file이다. disk안에 있는 paging file에 victim file을 쓴다.
이때 이 victim page를 가리키고 있던 page table을 바꿔주지 않으면 충돌이 생길 수 있기 때문에, OS가 page table을 고쳐준다.
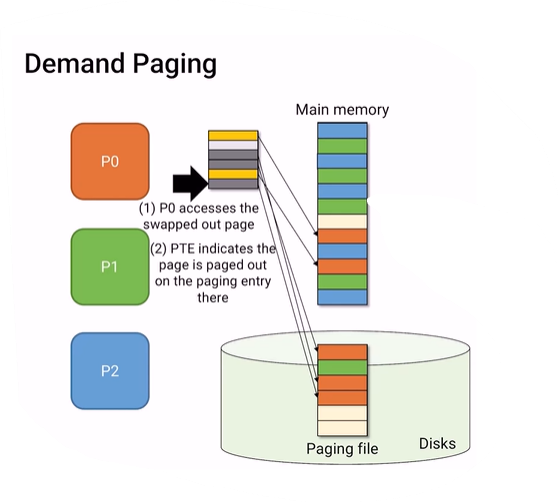
main memory를 가리키던 page table이 disk의 paging file을 가리키게 된다.
page가 disk로 갔다는건 어떻게 표시할 수 있을지 의문이 들 수 있다.
결론적으로, 비어있는 physical table에 그 값을 써놓는다.
virtual page가 실행하는 page를 disk에서 page를 찾아서 physical frame에 loading 시키고 page table을 업데이트 시키는게 demand paging이라고 앞에서 배웠다. demand paging이 된 부분은 valid bit이 1이고 PFN도 써 있지만, demand paging이 되지 않은 사용하지 않는 부분들은 valid bit이 0이고, PFN을 보통 0으로 해놓으며, 비어있는 곳이라고 인식하게 된다. 이 공간은 결국 남는 공간이 되기 때문에 이공간에 disk 어디에 victim page가 존재한다고 써 놓을 수 있게 된다.
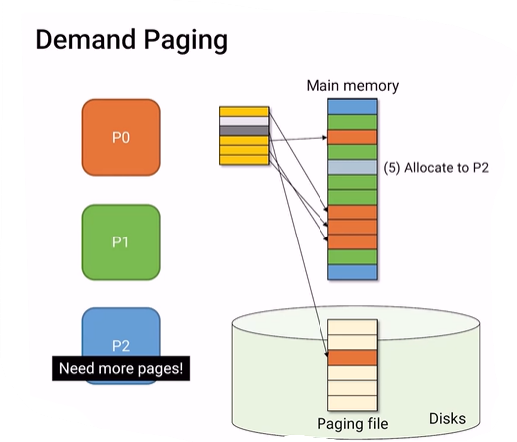
p2를 실행하다가 p0차례가 되었다. 그리고 나서 회색으로 칠한 부분(valid bit이 0이고 disk에 victim page를 가리키고 있다.)을 참조해서 다시 memory로 가져오려고 보니까 memory가 꽉차있다.
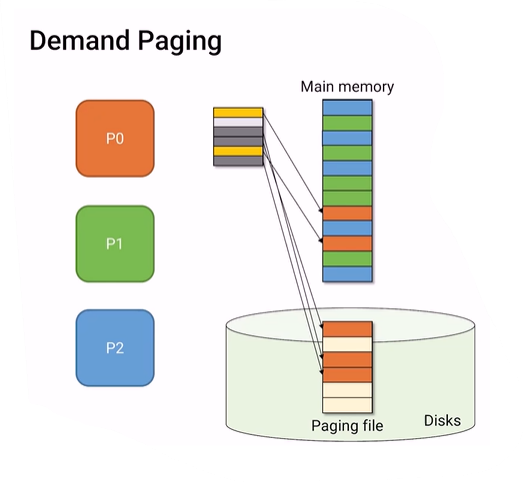
이때는 앞 부분과 똑같이 victim page를 찾아서 disk안에 paging file에 저장한다.
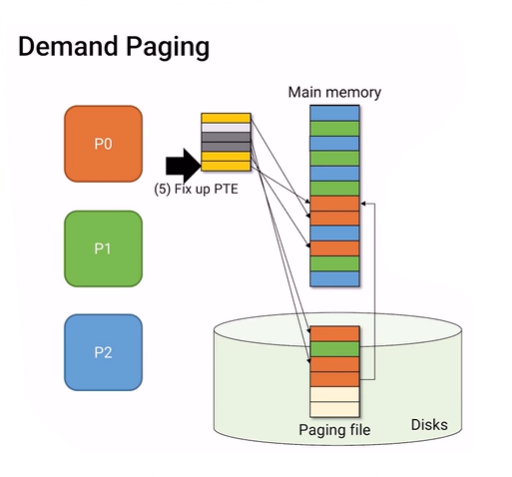
그러면 이제 사용하고자 하는 page를 paging file에서 main memory로 loading 하고 page table에 valid bit을 1로 바꾸고 PFN도 써준다.(fix up)
demand paging 요약
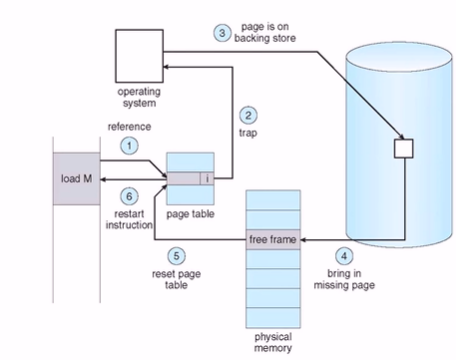
1.process가 page M을 참조했다. MMU가 page table에서 valid bit을 본다.
2.valid bit이 0이면 page fault가 나고 프로그램을 잠시 중단시킨후, OS한테 PF이 없다고 한다.(page fault)
2-1. valid bit이 1이면 MMU가 translation을 해서 PF을 찾아가게 하고, 프로그램이 실행된다.
3.OS가 disk에 어디에 page가 있는지 찾는다.
4.OS가 main memory로 page를 load한다.
5.그러고 나서 PTE를 valid bit을 1로 바꾸고 PFN을 써준다.(fix up)
6.중단했던 프로그램을 다시 실행시킨다.
다음 실행할 page를 disk에서 load하려고 하는데 memory에 공간이 없다면, 사용하고 있지 않은 victim page를 disk로 보내고, victim page를 가리키고 있던 PTE의 valid bit을0으로 만들어주고 victim page가 disk어디에 있는지 써준다.
demand paging 장점
- 실제 memory 공간이 1GB이고 disk가 100GB라면 memory는 마치 자기 공간이 100GB인 것처럼 사용할 수 있다. 필요한 page만 그때그때 가져와서 사용하면 되기 때문이다.
- 적은 공간의 memory가 disk의 cash 처럼 사용되게 된다.
Locality
평소에 운동하는 사람과 운동하지 않는 사람중 내일 운동할 사람은 누구일까?
당연하겠지만 평소에 운동하는 사람이다. 이전에 했던 것이 한번 더 할 확률이 높다고 하는게 locality 이다.
- Temporal locality: 특정 data를 참조했다면 다음번에 또 참조할 가능성이 높다.
e.g) for(int i = 0; i<10; i++) 여기서 i - Spatial locality: 어떤 공간에 있는 data를 참조했다면 다음에는 근처에 있는 data를 참조할 가능성이 높다.
e.g) for(int i = 0; i< 10; i++) sum += A[i] 여기서 A[i],
A[0]을 참조했다면 그 주변인 A[1].. 을 참조할 가능성이 높아진다.
Shared Memory
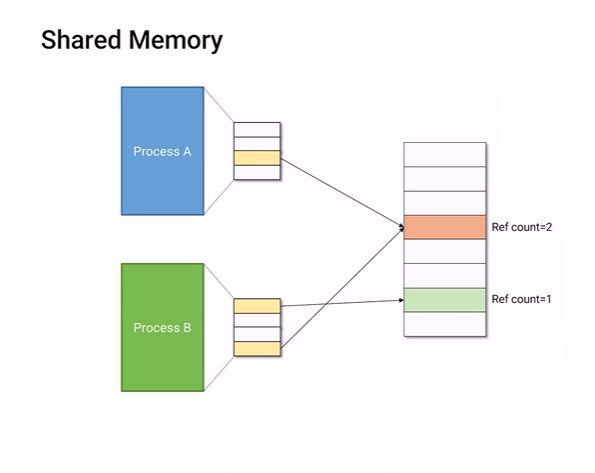
process A와 B가 같은 메모리 공간을 가리키고 있어서 memory를 공유하고 있다. 이걸 shared memory라고 한다.
copy-on-write
system call인 fork()를 한다고 해보자. fork는 process의 모든 메모리를 똑같이 복사한다. shared memory에서 처럼 process A가 가리키는 메모리 공간을 process B도 똑같이 가리킨다면?? 같은 메모리를 복사하는 것과 같은 효과가 있을 것이다. 그런데 문제는 fork()는 write했을때 두 process에 동일하게 값을 쓰는게 아니라, 서로 독립적으로 실행된다. 그래서 각 page table에 Read Write를 표시하고, write할때 서로 분리시키는 것이다. 이게 copy-on-write이다.
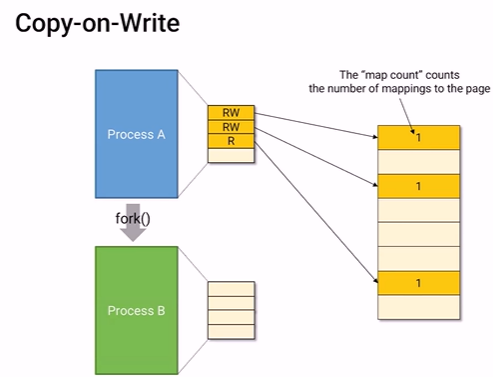
fork()를 했다.
빈 page table을 만든다.
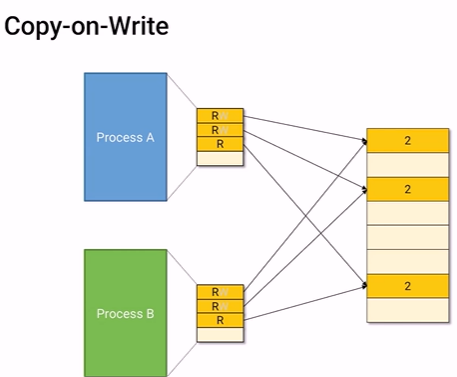
page table 내용을 모두 복사하고, write는 모두 임시적으로 꺼놓는다.(원래 write가 있었다는 것은 적어놓는다.) Read로만 모든 메모리를 공유하게 한다.
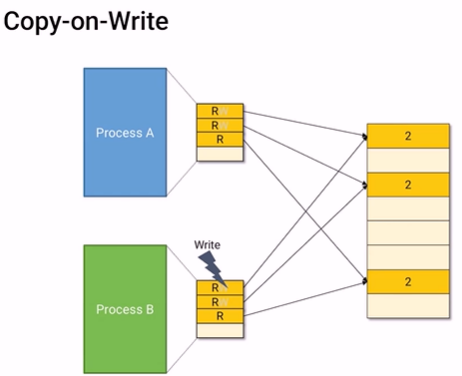
누군가 write를 하려고 하면 OS를 부른다.
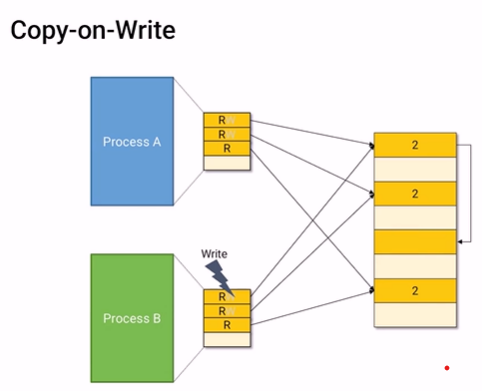
memory에 공간 하나를 만들어서 write하려고 했던 공간에 메모리를 복사해 놓는다.
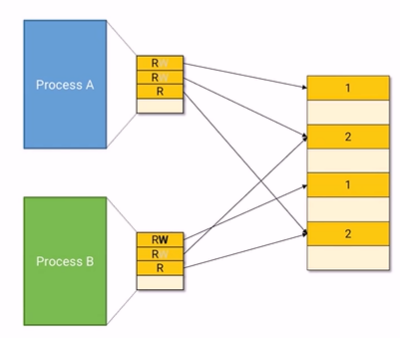
새로 만든공간을 page table이 가리키게 하고 write bit을 다시 켜놓는다.
실제로, 메모리를 달라고 요청하면 OS는 주는 시늉만 하다가 write를 하려고 할때 메모리를 할당해준다.
다시 write를 실행시킨다. 아까는 write bit이 꺼져 있어서 안됐지만,지금은 write bit이 켜져서 write를 할 수 있게 되었다.
그런데 이런식으로 하면, process A에서 page table이 가리키고 있는 memory의 count가 1인데도 메모리를 복사해서 만들고 거기를 가리키게 하고 write bit을 켜주고 다시 write를 실행하는 불필요한 작업을 하게된다. 사실 count가 1이라는건 하나만 가리키고 있기 때문에 그냥 그 메모리를 사용해서 쓰면 되기 때문이다.
따라서 memory의 count를 보고 1이면 write permission을 1로 만들어주고,count가 1보다 크면 copy on write를 하게 된다.
프로그램이 죽을때는 해당 프로그램이 맵핑되어있는 메모리 count를 1씩 빼준다.
추가로 MMU는 address Translation 말고도 기능이 하나 더 있는데, operation하려고 하는 게 rwx중 무엇인지 확인하고, page table이 해당 정보랑 일치하면 translation을 하고 아니면 OS를 불러와서 copy on write를 한다.
KSM
KSM(kernal same page merging)은 copy on write를 거꾸로 한것이다.
무슨 말이냐하면, copy on write는 page table의 다른 VPN들이 같은 physical page를 가리키고 있다면 Read로만 표시해 놓고 physical page에 count를 하고 있다가 write를 하려고 하면 physical page의 똑같은 내용을 복사해서 공간을 하나 만들고 그곳에 write 하는 것이였다. 즉, write할때 공간이 분리된다.
KSM은 반대로 분리되어 있던 공간이 같은 내용을 가리킨다면 공간을 하나로 합쳐주는 것이다. 그러면 각 page table의 page들이 가리키는 곳은 같아질 것이고, 카운트도 page 개수만큼 올라가게 된다. 그리고 page table의 write도 다시 끄게 된다.
