Hierarchical Page Table은 page table을 여러번 계속 접근해야 한다. 그런데 page table은 메모리에 있다. 즉, memory를 계속 접근해야 한다는 것이다. cpu 가 memory에 접근하는 것은 오랜 시간이 걸린다. 그래서 Level이 높아지면 높아질수록 메모리 스톨의 오버헤드도 커지게 된다.
이걸 어떻게하면 해결할 수 있을까? 해서 나온게 TLB이다.
TLB(Translation Look-aside Buffer)
소프트웨어는 미래를 예측하기는 어렵다. 따라서 보통은 과거를 보고 미래를 결정한다.
예를들어서, for(int i=0; i< 100; i++) 이러한 식이 있다. 이때 i에 접근할때마다 메모리에 접근하게 된다. 매번 메모리에 접근한다면 memory stall이 너무 커지기 때문에 cache 같은 개념을 도입하기로 했다.
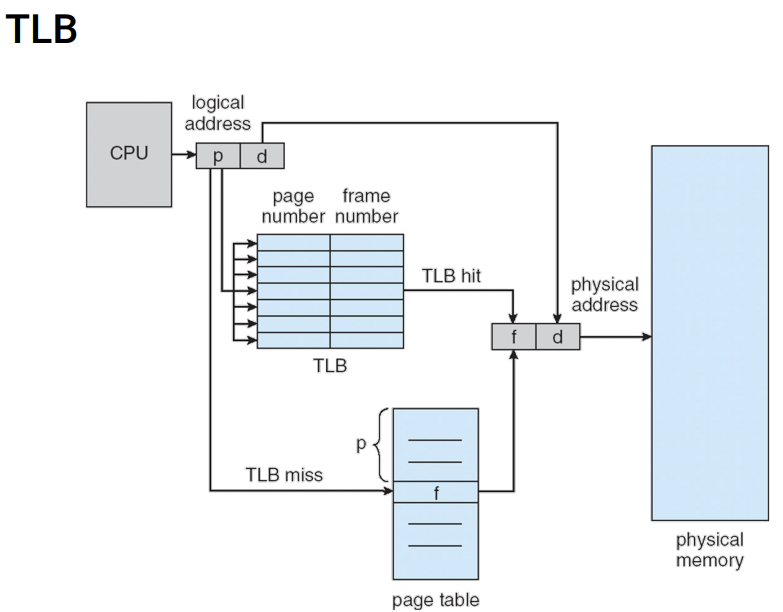
1.맨처음에 cpu가 돌다가 i 라는 변수에 logical address를 살펴봤더니 p(VPN)와 d(offset)로 되어 있었다. TLB를 뒤졌는데, TLB에 p가 없다. 그러면 hirarchical page table로 가서 p를 찾은후 PFN인 f를 찾았다. 그러면 이제 TLB에 page number와 frame number인 p와 f를 값을 써준다.
2.다음으로 i를 찾기위해 p를 뒤져봤더니 TLB에 p가 있었다. 그러면 TLB에 있는 p를 통해서 f를 찾아 바로 이용한다.
이렇게 되면 메모리에 계속 접근하지 않아도 돼서 속도가 빨라진다.
참고로, TLB는 하드웨어이다. 따라서 병렬적으로 신호를 주면 있다, 없다가 바로바로 나와서 빠르다.
context switch가 일어나면 cpu가 보는 page table이 달라지기 때문에, TLB를 비워줘야 한다.(flush) 그래서 context switch를 자주 해주면 address space translation의 속도가 매우 줄게 된다.
그렇다면 context switch가 일어나도 TLB를 flush하지 않고 계속 사용할 수는 없을까??
그래서 나온게 ASID(Address space ID)이다.
쉽게 말해서, TLB에 맵핑되어 있는 정보가 어디 프로세서로부터 온 정보인지 기록 해두 는 것이다. TLB를 체크할때, process 1을 실행하고 있다면 TLB에 똑같은 page number가 존재하더라도 ASID가 process 1이 아니면 miss가 난다.
즉, 해당 process에서온 page number여야 한다.
TLB가 꽉차면 안쓰는애들을 빼주는데 이건 policy에 따라 다르다.
