Hashed Page Table
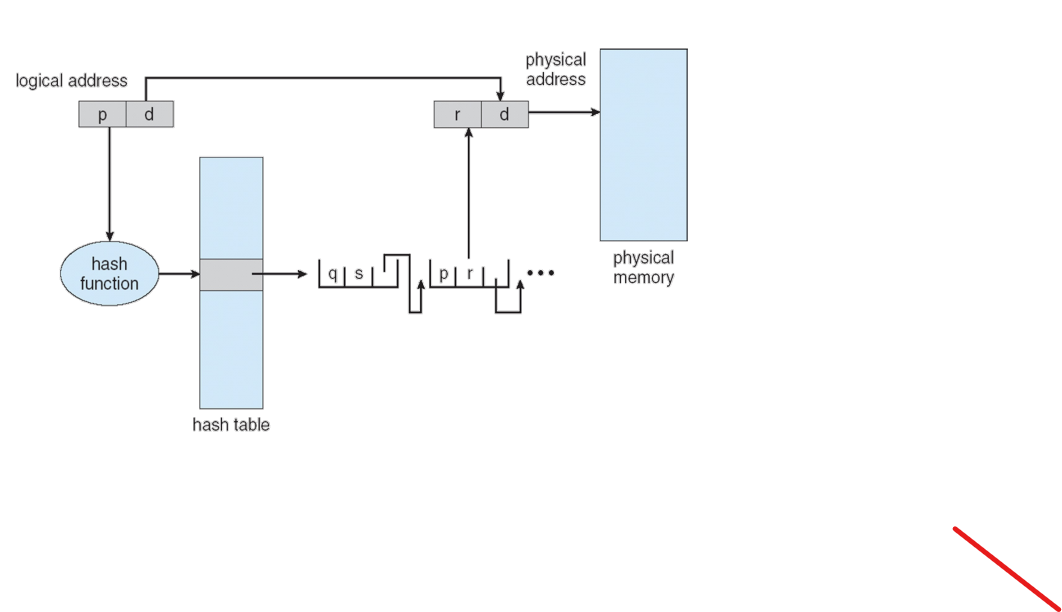
hash의 궁극적인 목표는 더 많은 수의 데이터를 더 적은수로 보관할 수 있게 하는것이다. 예를들어, 10만개의 VPN이 있는데,만개의 Hash Table entry에 넣으려고 하는것이다. 그래서 필요한게 hash function이다. hash function은 어떤 공식을 통해서 값을 넣었을때, 새로운 값이 나온다.
위 그림을 보면, logical address에서 p(VPN)를 hash function에 넣으면 몇번째 칸으로 갈지 나온다. 해당 칸으로 이동했더니 첫번째 bucket에는 p가 없고 q가 있었다. 그래서 다음 칸으로 이동했고 그 칸에 p가 있었다. p에 저장되어 있는 PFN은 r이므로 r과 offset인 d를 합쳐 physical address를 알아낸다.
참고, hash table entry 한칸에 여러 값들이 있는것을 chain of VPN이라고 한다.
Hash의 문제
보통의 경우, VPN이 굉장히 크고 여러군대에 퍼져있을때는 hash table에 indexing 하기가 매우 편하지만, hash table안에서 chain이 길어져서 값을 찾는데 오래 걸린다면(collision이 많이 일어나면) 시간이 오래걸릴수있다.
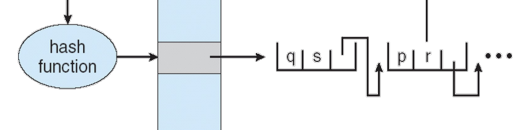
이 부분을 말하는 건데, 이부분은 하드웨어로 로직을 짜기도 힘들다. 앞의 내용을 연산한 후에 결과값에 따라 if else를 통해서 다음값으로 넘어가는 것, 끝이 몇개 까지 인지 bound가 정해져있지 않기 때문이다.
때문에 실제로 사용하지는 않고, page table을 구성할때 이러한 로직으로도 짤 수 있겠구나 하고 생각했던 이론이다.
