History of Schedulers in Linux
✍️v1.2
- 실행 가능한 task 관리자에 대한 circular queue(RR)
- process들을 추가하고 제거하는데 효과적
✍️v2.2
- scheduling classes을 도입
- 실시간 작업, 비실시간 작업, 우선순위 없는 작업에 대한 스케줄링 정책을 사용가능
- SMP(symmetric multiprocessing)를 지원하기 시작
✍️v2.4
- epoch 단위로 시간을 나눈다. 모든 작업은 epoch동안 실행할 수 있다.
- task가 epoch의 일부를 사용하지 못한 경우에는 다음 epoch에서 더 길게 실행할 수 있도록 나머지 시간의 절반이 다음 epoch에 추가된다.
- scheduling event 동안 모든 task를 반복하여 O(n)시간이내에 작동되는 비교적 단순한 스케줄러
- 단순히 goodness함수를 적용해서 다음 실행 방법을 결정하는 방식으로 전체 작업을 반복
- priority를 고려하다 보니까 다음 작업을 선택하려면 전체 작업을 뒤져봐야 함.
- 상대적으로 단순하긴 하지만 상당히 비효율적
- scalability(확장성) issue: kernal time의 37-55%를 scheduler에서 보낸다.
✍️v2.6
-
by Ingo Molnar
-
kernel 2.6.0 ~ 2.6.22 사용
-
v2.4의 문제점을 개선
-
전체 작업을 반복하지 않고도 스케줄링할 다음 작업을 식별 할 수 있다.
-
훨씬 효율적이고 확장성이 높다.
-
다음 process를 뽑고 다시 넣고 하는게 모두 constant time에 의해 결정
constant time에 의해 처리가 되어서 Order(1)이라고 부름
-
각 프로세스는 fixed time quantum이 주어짐.
일정시간이 bound되면 다음 process를 바로 뽑는다.
-
복잡하고 자료구조도 많이 들어가고 하다보니 버그가 많이 나옴.
-
runnalbe task를 하나의 실행 큐로 추적
실제로는 우선순위 레벨별로 두개의 실행 큐 사용(SMP scheduling)
하나는, active task를 위한 queue (active array)
다른 하나는, expired task를 위한 queue(expired array) -
다음 실행 작업을 위해 스케줄러는 각 우선 순위에 해 당하는 특정 active queue에서 다음 작업을 가져오기만 하면 된다.(active queue에 아무것도 남지 않을때까지 반복)
-
확장성이 훨씬 높아졌으며, 상호 메트릭과 여러 추론 방법을 통합하여 I/O 또는 프로세스 관련 작업인지 여부 결정
-
하지만, 커널에서 다루기기가 쉽지 않다.
추론 방법을 계산하는데 필요한 코드의 양이 매우 많아서, 근본적으로 관리하기 어렵다.
이를 해결하기 위해서 CFS로 넘어감(현재 리눅스에서 사용중인 형태)
✍️Completely fair scheduling(CFS)
- 최대 170개 priority level을 가지고 있고 3~4 class로 나눈다.
- preemptive priority scheduling이다.(time slice에 따른 RR)
- time slice를 가지고 time-shared를 한다.
✍️process priority들은 시간이 흐르면서 동적으로 변한다.
- cpu-bound process들보다 interactive process들을 선호
- wait time일때 priority 증가
- CPU time 일때 priority 감소
Completely Fair Scheduler(CFS)
-
기본적인 동작은 sequence로 나열되어 있는 process들중 가장 먼저 있는 process를 돌리고 일정 시간이 지나면 적당한 위치에 다시 넣어 놓는다. 그러고 나서 다음 process를 또 찾아서 일정시간동안 실행시킨다.
계단이 있다고 생각해보자. 각 층마다 process들이 있고, 아래층부터 scheduler가 process들을 실행한다. 1층의 process를 실행시키고 일정 시간이 지나면 scheduler가 적당히 계산해서 14층 정도의 다시 넣어놓고 2층으로 향한다.2층에서도 마찬가지로 process를 실행시키고 일정 시간이 지나면 적당히 24층 이정도에 넣어 놓는다.
다시 넣어놓을때 정해지는 층수는 process의 계산에 의해서 priority가 알맞은 자리를 찾는다. -
그렇다면 어떤 순서로 process들을 나열 할 수 있을까?? linked-list를 사용하면 앞에 head만 보고 꺼낼수 있어서 어떤 process들을 실행시킬지는 쉽게 결정된다.
그렇다면 사용하고난 process들을 sequence에 어딘가에 넣을때는 모든 층들을 뒤져봐야 알 수 있다.
이렇게 하면 CFS보다 앞서 썼던 V2.4와도 다를바가 없다.
어떻게 해결할 수 있을까??
✍️red-black tree를 사용하면 된다. red-black tree는 자동으로 balance를 맞춘다. process들을 꺼내서 실행시킬때는 constant하고, 다시 넣을 다음 층수를 계산할때는 O(logn)이 걸린다.
물론 O(1)보다는 시간이 오래걸리지만 직관적으로 구조가 이해가 간다.
✍️target latency
- cpu time, schedule이 되었을때, process를 실행시킬 수 있는 시간
process를 꺼낸다. cpu가 가지고 있는 target latency 만큼 실행할 수 있다.
실행 하고도 target latency가 부족했다면 process를 적당한 위치에 다시 넣어 놓는다.
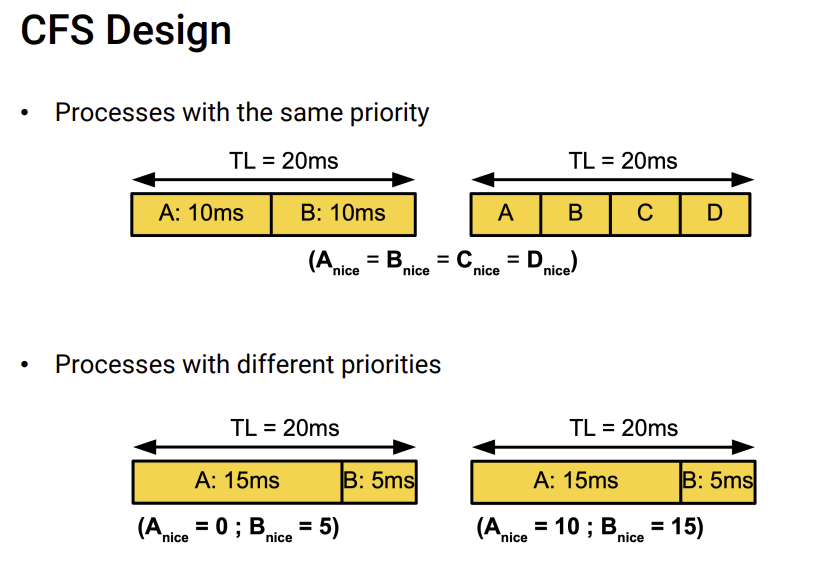
TL이 target Latency이다. TL은 proportional scheduling처럼 process에게 priority가 높으면 더주고 priority가 낮으면 덜주는 식으로 다르게 시간을 배분한다.
위 그림에서 보면, 위 그림은 priority가 모두 같아서 같은 비율로 주고, 아래 그림은 priority가 A가 더 높아서 A에게 시간을 더 많이 할당한다.
priority가 높으면 process를 다시 넣을때도, 멀지 않은 곳에 넣어놓고, priority가 낮으면 조금 먼곳에 넣어놓는 식으로 한다.
이렇게 되면 priority가 높은 process는 더 자주 scheduling이 될 것이다.
✍️process를 다시 던져 놓는 층수는 어떻게 결정 되는가?
- 예를들어서 한 process가 TL을 5정도 부여받았는데 2밖에 쓰지 않고 I/O interrupt를 기다리고 있었다. 그렇다면, 이 process는 금방금방 써야 하는 process라고 인식을 하고 바로 다음 계단에 던져 놓고 바로바로 scheduling 될 수 있게 해준다.
반면, TL을 10정도 부여 받았는데, 다 써버렸다. 그러면, 이 process는 더 높은 층수로 던져버린다.
참고로, wait queue에 있는 process를 ready queue로 넣을때도 어느정도의 층에 넣어야 하는지 계산한후 넣는다.
✍️starvation은 발생하지 않는다.
- 새로운 process가 앞에 끼어들수는 있지만 process의 위치는 확정적으로 들어오기 때문에, scheduler는 무조건 한계단씩 올라가게 되어 있어서 언젠가는 자신의(process) 차례가 오게 되어 있다.
Multiple-Processor Scheduling
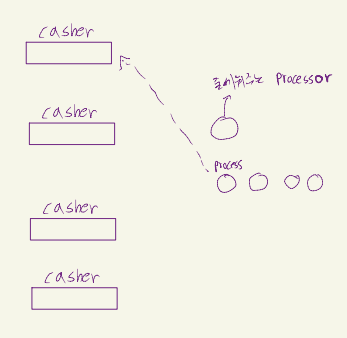
마트를 예로 들어보자. 마트에 가면 계산을 해주는 casher 들이 있다. 그리고 계산 하는 손님 들이 줄을 서 있다. 계산하는 방식에는 두가지가 있는데,
1. 손님들이 자발적으로 각 casher에게 줄을 서거나
2. 손님들을 줄 세워주는 직원이 한명 있는 것이다.
scheduling에서는 casher를 processor, 손님을 process로 대응시킬 수 있다.
✍️Asymmetric multiprocessing
- 줄을 세워주는 직원이 한명 있는 것이다. 이 직원은 scheduling만 담당하는 processor 이다.
- 만약에 한 사람당 물건 100개씩 계산한다면 casher들은 계산하기 바쁘고 오래 걸린다. 줄을 세워주는 직원은 가끔 한번씩 스케줄링만 해주면된다.
줄 세워 주는 직원은 계속 놀게 되고 casher는 엄청 바쁘게 된다. - 반면,손님들이 물건을 1개씩만 계산하면 돼서 물건을 쉽게 찍고 빨리 나간다면,
casher는 금방금방 처리하고 놀겠지만, 줄세워주는 직원은 엄청 바쁘게 스케줄링 하게 될 것이다 - task에 특징에 따라서 운이 안좋으면 노는 cpu가 생겨서 좋지않다.
그래서 SMP를 쓴다.
✍️Symmetric multiprocessing(SMP)
- 손님들이 자발적으로 각 casher에게 줄 서는 것이다.
- 각자 자신의 processor마다 wait queue도 있고 각자의 processor가 process들을 알아서 scheduling 한다.
- AMP에서는 특정 scheduling processor가 상황을 봐가면서 scheduling을 했었는데, SMP는 조절해주는 processor가 없어서 한 processor에만 process가 몰릴수도 있다. (load inbalancing)
- 그렇다면 이걸 load balancing(process를 골고루 배분) 해주는게 필요한데 어떻게 할 수 있을까??
cpu는 자신의 상황을 기록해 놓는 큰 array가 있다.
cpu가 1tick이 들어왔을때, 자신의 상황을 기록해 놓는 array에 업데이트를하고 cpu들의 array들을 돌면서 여유 있는 cpu를 알려준다. - 문제는 cpu가 1000개이상씩 있다면 tick 하나가 들어오면 자신을 업데이트하고 1000개를 다돌면서 누가 여유있는지 모니터링을 해야하는데 매 tick마다 하는건 너무 오래 걸린다
- 그래서 cpu는 자신이 바쁘면 자신이 가지고 있던 process를 다른 cpu에게 밀어 넣어주고(push migration), 자신이 한가하면 다른 processor에서 process를 가져온다.(pull migration)
- push migration은 어떤 cpu가 한가한지 파악하고 내 process를 밀어 넣어주려면 또 안그래도 바쁜cpu가 더 필요해서 어렵다. pull migration은 cpu가 시간이 널널해서 자신의 cpu를 써서 바쁜 cpu에서 자신의 cpu로 끌고 오기 때문에 더 합리적이다.
NUMA
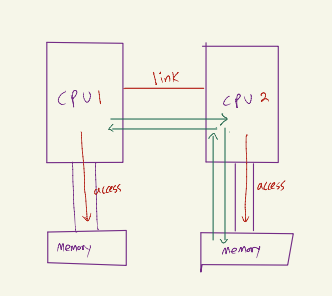
- processor들은 다른 processor의 메모리는 접근할 수 없고, 오로지 자신의 메모리만 접근할 수 있다. 만약, 다른 processor의 메모리에 접근하고 싶으면 link를 통해 다른 processor에게 데이터에 대신 접근해서 알려달라고 통신을 한다.
이러한 구조를 NUMA(Non-uniform Memory Access architecture)라고 한다.
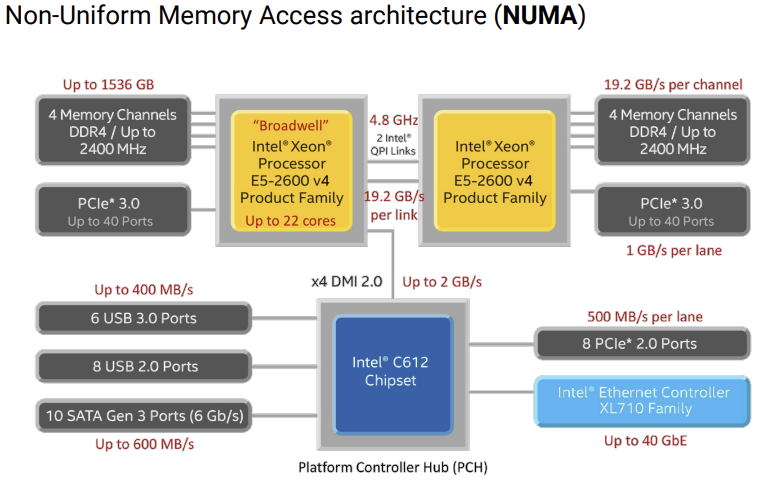
- 언제는 memory를 가져오는 속도가 빠르고(내 CPU에 memory에 접근할때), 어떤때는 memory 가져오는 속도가 느리고(다른 CPU의 memory에 접근할때) 한 이유가 이것이다.
그렇다면 이게 scheduling과 무슨상관일까?
어떤 cpu가 malloc을 했다고 하자. 당연히 근처에 있는 memory를 할당해준다.(momory access가 빠르기 때문) 그런데 이런게 엄청 쌓여서 여러 process가 cpu에서 돌게 되었다. 그러면 process가 일을 많이 하기 때문에 다른 processor가 pull migration을 해주게 된다. 문제는, pull migration한 cpu에서 memory가 멀기 때문에 접근하는데 시간이 오래걸리게 된다. 그러면 cpu의 환경은 좋아졌지만 갑자기 내 컴퓨터에 performance는 낮아지게 된다.
운영체제가 알아서 해줄 수는 없을까??
운영체제도 cpu가 어떻게 행동할지 미래정보를 알 수는 없다.
NUMA에서 computer perfomance가 내려가는 문제를 해결하기 위해서, 사용자는 process가 특정 cpu에서 돌 수 있도록 system call을 통해 지정해줄 수 있다.(processor Affinity)
만약에 process가 cpu에서 과부하가 되더라도 pull migration 당하지 않고 내가 지정한 cpu에서만 돌게 하는 것이다. 이렇게 하면 memory 접근이 멀어지는 것을 막을 수 있다.
single-chip multiprocessor(multicore)
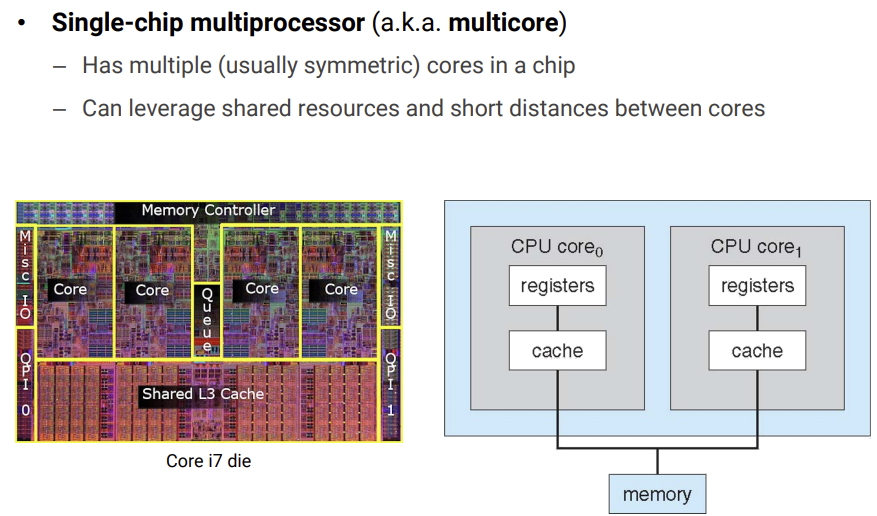
- 옛날에는 multiprocessor를 사용했지만 사용하다보니 하나의 cpu에 여러개의 processor(core)를 넣는것이 더 효과적이겠다고 생각해서 만든 것이다.
- intel이 처음에 single-chip-multiprocessor라고 출시했지만 사람들이 못알아들어서, multicore라고 이름을 붙이게 되었다.
- shared resource(ex) shared L3 cache)가 있고, 이것을 각 core에 나눠서 할당한다.(동작하는데 있어서 100% 평생 필요한 자원이 아니라면 이런곳에 넣어둔다.)
- 기숙사를 예로 들어보자. 같이 사는 2명이 있다. 한명은 방에 엄청나게 물건을 많이 쌓아두는 성격이고, 한명은 방에 물건이 거의 없다. 이렇게 같이 살면 물리적으로는 별로 문제가 없을 것이다.
반면, 두명다 물건을 많이 쌓아두는 성격이라면 공간이 부족해 싸움이 날 것이다.
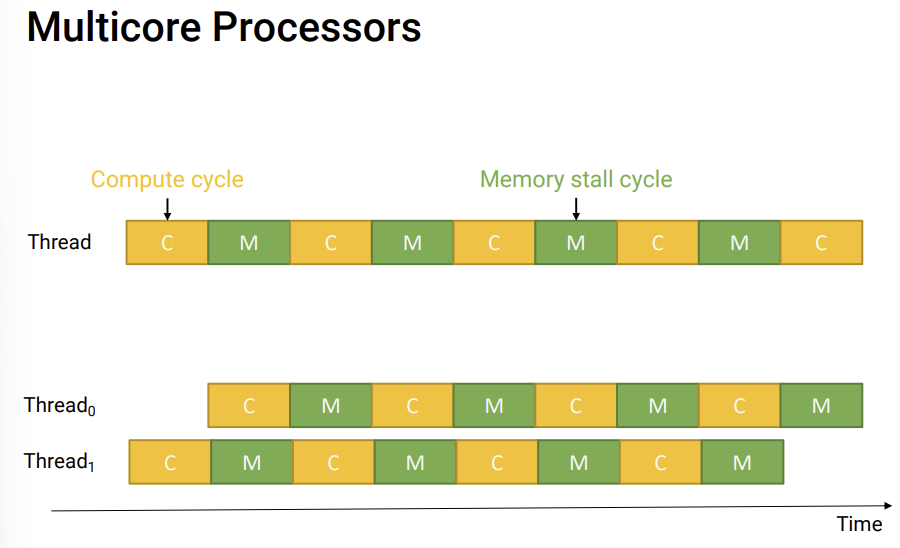
- thread가 하나만 있을 경우에는 Compute cycle을 하는 동안에 ALU를 사용하고 Memory stall cycle에는 ALU를 사용하지 못하고 있는 상황이 벌어진다. 50% 정도밖에 사용이 안되는 것이다.
반면, thread를 하나 더 추가해준 경우에는 thread0이 memory stall을 할때 thread1이 ALU 연산을 하기 때문에 100% 사용할 수 있다.(hyperthreading)
core하나가 두개의 thread를 처리한다.
e.g)system을 보면 core가 8개이지만 ALU는 16개로 나온다.
✍️hyperthreading 문제
하지만, 두 thread간에 타이밍이 잘 안맞는다면??
예를들어 thread0에 compute cylce이 길어버리면 thread1은 0이 끝날때까지 기다릴 수 밖에 없다. 성능이 들쭉날쭉할 수 있다.
성능이 낮아도 일정한 성능이 필요하다면 hyperthreading을 끈다.
때문에 위에 기숙사 예를든 것 처럼 thread 쌍을 잘 맞춰줘야(compute cycle과 memory stall 타이밍이 잘맞게) ALU를 효과적으로 잘쓸수 있다.
Multitasking in mobile system
예전에는 사람들은 백그라운드 환경에 있는 것들보다는 보이는 것이 중요하다는 생각을 하게 되었고, 백그라운드는 아예 동작을 멈추기로 함. foreground만 성능을 부스팅 시켜줌. 예를들어 CFS에서 사용자가 보고 있는것들은 priority를 높게 해서 계속 사용할 수 있게 해주고 background에 있는 것들은 priority를 낮게 해서 조금 느리게 실행되도 상관없었다.
요즘에는, 베터리 성능이나 cpu 성능도 좋아져서 이정도로 제약이 심하지는 않다.
사용자가 백그라운드에서 사용할지 말지 정할 수 있다.
