Multilevel Queue scheduling
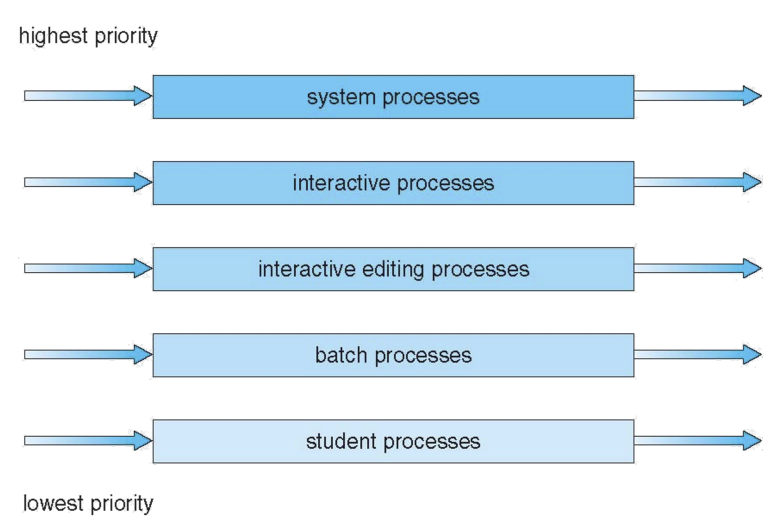
process들은 빨리 실행되어야 하는 것들도 있고 느리게 실행되어도 되는 것들도 있다. 그래서 각 process의 특성에따라 분류를 해서 큐에 담아 실행할 수 있게 하였다.
중요한 것들은 높은 priority의 큐에 넣고 덜 중요한 것들은 낮은 priority의 큐에 넣는다. 이렇게 하다보니 priority에 의해 starvation이 발생한다.
starvation을 해결하기 위해서, 각 queue마다 priority에 따라 다른 시간을 부여한다. 예를들어 priority가 10,20,30인 queue들이 있다면, 전체 time slice의 50%는 30에 30%는 20에 10%는 10에 부여한다. 이렇게하면 starvation은 해결된다.
하지만 process를 큐에 넣을때 어떤 특성의 프로세스인지는 미래 정보이므로 알 수가 없다. 대부분은 현재 프로그램의 진행 상태를 보고 판단을 한다.
그래서 나온게 Multilevel Feedback queue이다.
Multilevel Feedback Queue(MLFQ)

job들의 작업량들을 예측하는것은 어렵기 때문에 feedback을 통해서 조정한다.
예를들어서, process를 실행을 시켜봤더니 주어진 time slice를 모두 사용하지 못했다. 그러면 이 process는 interactive한 process라고 판단해서 해당 queue에 두고 사용한다. 만약, process를 실행시켜봤더니, time slice를 다 사용했다면(cpu burst가 커서 낮은 priority queue로 옮김) ,interactive하기 보다는 cpu bound다 라고 판단하고 더 낮은 priority queue로 옮긴다. 여기서도 똑같이 time slice를 다썼다면 더 낮은 큐로 옮기기를 반복한다.(맨 처음 process가 들어올때는 최상위 큐로 들어와서 시작한다.)
새로운게 계속 들어온다면, priority가 낮은 process들은 계속 밀려서 starvation이 발생할 수 있다. 이것을 해결하기 위해서 일정시간이 지나면 모든 process를 최상위 queue로 이동시켜 RR방식을 사용한다.
✍️단점
- algorithm이 복잡하다.
- cpu의 overhead가 크다.
✍️parameters
- queue들의 수
- 각 queue에 대한 스케줄링 알고리즘
- process를 promote/demote시킬때 결정하는 방법
- process가 service가 필요할때 process가 들어갈 queue를 결정하는데 필요.
Portional share scheduling
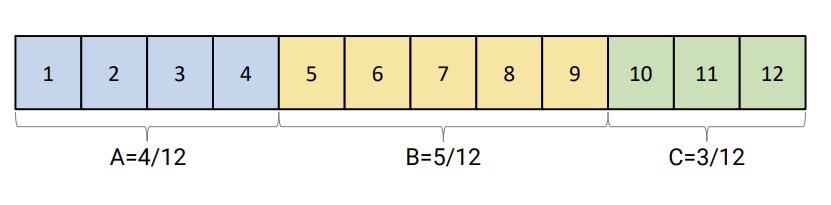
- T share는 시스템에서 모든 process들에게 할당되어 있는 것이다.
- 한 application은 N share들을 받는다. (N < T)
- application은 전체 processor time중의 N/T을 받을 것이다.
- 각 process들이 cpu time을 나눠 갖고 그 시간을 보장 받는다.
Portional share scheduling의 예로 Lottery Scheduling이 있다.
Lottery Scheduling
✍️기본 매커니즘
- process들은 각각 할당된 ticket들이 있고, 각 ticket들은 일정한 timeslice를 가진다. scheduler는 랜덤으로 ticket을 뽑고, 뽑힌 process들은 한 ticket의 timeslice만큼 실행한다. timeslice가 끝나면, 다시 ticket을 뽑는다.
✍️lotteries
-
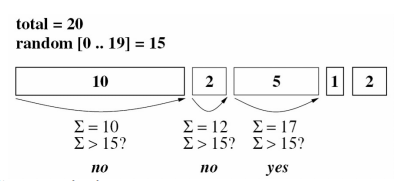
scheduler가 ticket을 랜덤으로 뽑고 resource를 준다.
-
예상되는 resource 할당 비율은 ticket수에 비례한다.
-
실제 할당된 비율은 예상 비율과 정확히 맞지 않는다.
하지만, ticket의 할당 수가 증가함에 따라, 격차도 줄어든다. -
ticket이 뽑힐 확률 p (total T ticket) = t/T
-
n 번의 lotteries에서 예상되는 뽑힐 확률 = E[w] = np
-
한번 뽑기 위해 필요한 lottery 수 = 1/p
-
client의 average response time은 티켓 할당에 반비례 한다.
✍️Implemetation Issues
잦은 lottery는 효율성이 필요하다.
- 빠른 랜덤 넘버 생성자
park-Miller algoritm 기반
약 10개의 RISC instruction으로 실행된다.
✍️ time complexity
- straight forward algorithm :O(n)
- Tree-based algorithm:O(log n)
