
Ray-Tracing으로 좀 더 공간감 있는 현실적인 Audio 효과를 구현하고 있다.
지금은 CPU 기반 Ray Tracing으로 반사와 Delay만 들어가고 구현되어 있지만, 이후 GPU 기반으로 전환하고 굴절(투과), Reverb Tail도 구현할 계획이다.
Ray Tracing
가능한 많은 방향으로 Raycast를 진행하고, 각 Hit point에서 반사각을 계산해 다시 Raycast를 진행하고, 이를 반복하는 방식이다.
그래픽의 경우 Ray의 방향이 시점에서 near plane의 각 점을 잇는 방향으로 정해져 있지만, 소리는 Frustum 같은 개념이 없으므로 가능한 모든 방향을 커버할 수 있도록 하였다.
이때 3차원의 모든 방향을 균일하게 생성하기 위해 Fibonacci Sphere 알고리즘을 사용한다.
Fibonacci Sphere
3차원의 모든 방향을 균일하게 생성하기 위해, 구의 정점을 균일하게 만들어 주는 Fibonacci Sphere를 사용한다.
// Create FRotators Around Sphere
TArray<FRotator> RotatorArray;
const float GoldenRatio = (1.0f + FMath::Sqrt(5.0f)) / 2.0f;
const float AngleIncrement = 2.0f * PI * GoldenRatio;
for ( int32 i = 0; i < NumPoints; ++i ) {
float t = (float)i / (float)NumPoints;
float inclination = FMath::Acos(1.0f - 2.0f * t); // θ
float azimuth = AngleIncrement * i; // φ
// Spherical to Cartesian
float x = FMath::Sin(inclination) * FMath::Cos(azimuth);
float y = FMath::Sin(inclination) * FMath::Sin(azimuth);
float z = FMath::Cos(inclination);
FVector Direction = FVector(x, y, z); // Normalized already
FRotator Rotator = Direction.Rotation(); // Look-at rotation
RotatorArray.Add(Rotator);
}
Forward RT, Backward RT
반사 경로를 따라 여러 차례 Ray Casting한다는 점에서는 같지만, 어디서부터 시작하느냐에 따라 Forward 방식과 Backward 방식으로 나뉜다.
Forward 방식은 빛(또는 소리)의 진원으로부터 Ray를 쏴 반사 경로를 추적하는 방식이다. 좀 더 직관적이지만, 진원의 개수만큼 Ray가 늘어나므로 비효율적이다.

Backward 방식은 Camera(또는 Listener)로부터 Ray를 쏴 반사 경로를 역추적하는 방식이다. Forward 방식에 비해 놓치는 Ray들이 발생할 수 있어 조금 부정확하지만 대신 부하가 적다.
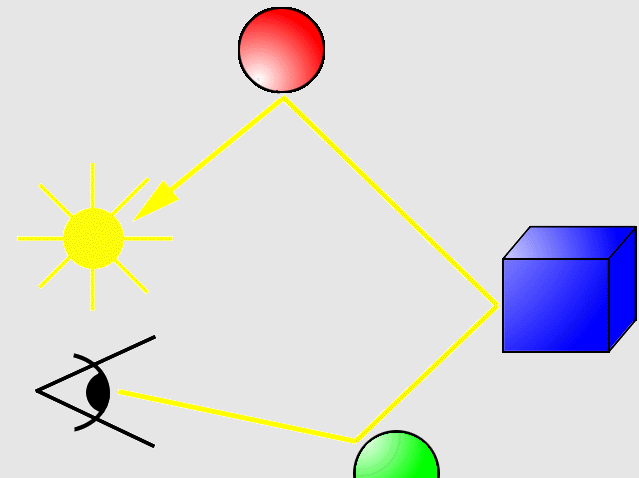
보통은 Backward 방식을 기반으로 Forward 방식을 일부분 도입한 Hybrid 방식을 사용한다. 크게 Whitted, Heckbert, Veach 방식이 있다고 한다.
Whitted RT
기본적으로 Backward RT 방식이지만, Hit point마다 진원으로의 Ray를 쏴 해당 Hit point에서 그 빛이 기여하는 정도를 계산, 누적하는 과정이 추가된다. 이렇게 추가되는 Ray를 Shadow ray라고 부른다.
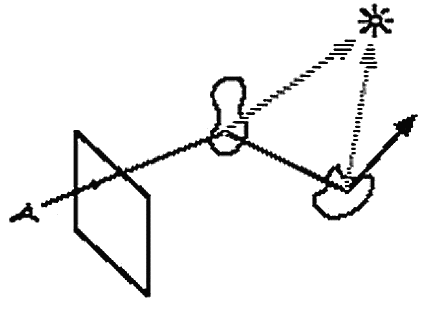
이 외에도 투과(굴절) Ray를 생성해서 반복할 수도 있다.
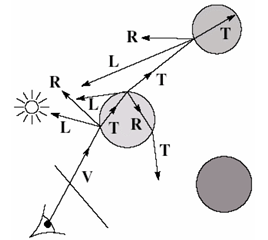
정리하자면, 각 Hit point에서는 다음과 같은 Ray가 재생성된다.
- (Shadow ray): 빛(또는 소리)의 진원을 향하는 Ray
- (Reflected ray): 반사각으로 향하는 Ray
- (Refracted ray, Transmitted ray): 굴절각으로 향하는 Ray
이때 과 는 Hit point에서 다시 Ray를 재생성하게 된다. 따라서 Ray의 수는 Hit될 때마다 2배수로 늘어나게 된다.

다만 여기서는 Transmitted ray 는 고려하지 않고 만들었기 때문에 반사 효과만 구현되어 있고, Ray 개수 역시 Hit될 때마다 1배수로 유지된다.
또한 를 이용해 해당 빛(또는 소리)가 hit point에 기여하는 정도를 계산할 수 있는데, 이는 Phong Lighting 모델의 diffuse 부분과 동일하다. 즉 Lambertian 모델을 사용한다.
위는 Phong Lighting 모델의 계산식이고, 아래는 Whitted 모델의 계산식이다. Diffuse까지는 동일한 것을 볼 수 있다.
Attenuation
3차원에서 빛이나 소리는 거리 제곱에 반비례하여 작아진다.
이때 소리의 경우 작아지는 양은 음향 파워로, 흔히 생각하는 음압과 진폭은 음향 파워의 제곱근에 비례하는 관계다. 따라서 음압은 거리에 반비례하여 작아지게 된다.
언리얼 엔진에서도 거리에 대한 소리 감쇠 에셋을 제공하고 있으나 현실과는 조금 거리가 있는 모델로 만들어져 있다.
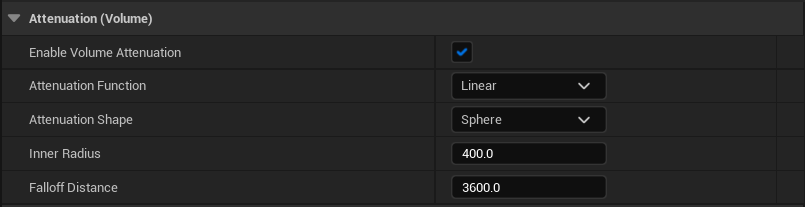
이 모델은 일정 거리(Inner Radius)까지는 볼륨이 100%였다가, 일정 거리 이후로는 Attenuation Function에 따라 소리가 Falloff Distance에 걸쳐 점차 줄어들고 그 끝에는 0%가 된다. 아래는 Attenuation Function이 Linear일 때 거리와 소리 크기의 관계를 그린 것이다.
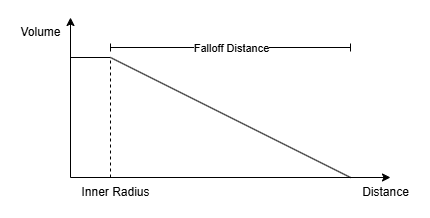
여기서는 프로토타이핑을 위해 언리얼 엔진 Attenuation 에셋을 사용했으나 실제 구현에서는 이 에셋을 사용하지 못할 것 같다.
Delay
빛은 속도가 빠른 만큼 거리에 따른 지연을 사실상 0으로 생각해도 됐지만, 소리는 이야기가 다르다. 때문에 Ray Tracing 계산 과정에서도 거리를 누적해서 반환할 수 있어야 하며, 이를 기반으로 Delay와 거리에 따른 감쇠를 계산하여야 한다.
그러나 이 지연시간은 매 소리마다 다르고, 엔진의 한 틱보다 짧을 수도 있다. 때문에 GetTimerManager()->SetTimer(...) 같은 함수로 지연을 주는 건 적절하지 않고, 대신 DSP 파라미터로 접근하거나 오디오 샘플에 직접 접근할 수 있어야 한다.
일단은 MetaSound에 DSP 파라미터를 외부에서 전달할 수 있는 방법이 있어서 이를 활용해서 Delay를 주었다.
UGameplayStatics::SpawnSoundAtLocation(...)을 쓸 수도 있고 UGameplayStatics::PlaySoundAtLocation(...)을 쓸 수도 있는데, 전자의 경우 AudioComponent를 생성 및 반환해서 재생 중에도 파라미터를 변경할 수 있다. 하지만 구현상 오디오 재생 수가 꽤 많아서 그것마다 Component를 생성하면 상당히 프레임 드랍이 있었다.
다행히 UGameplayStatics::PlaySoundAtLocation(...)로도 파라미터 초기값을 전달할 수 있었고, 그 정도면 충분했다.
float Volume = 1.f;
float Delay = (SoundPosition - GetActorLocation()).Length() / SoundSpeedInCm;
const FAudioParameter DelayParam(FName("delay"), Delay);
UInitialActiveSoundParams* Params = NewObject<UInitialActiveSoundParams>();
Params->AudioParams.Add(DelayParam);
UGameplayStatics::PlaySoundAtLocation(
GetWorld(),
Sound, // Sound Asset
SoundPosition, // Sound Position
Volume, // Volume
1.f, // Pitch
0.f, // Start Time
SoundAttenuation, // Attenuation Asset
nullptr, // Concurrency Asset
Params // Sound Params
);그러나 모든 Sound를 Metasound로 한 번 래핑해야 되고, Sound cue에서는 대응이 불가능한 방식이라 결국 샘플 단위로 수정이 필요해질 것 같다.
구현
알고리즘을 개략적으로 설명하면 다음과 같다.
const float SoundSpeed = 34300.f; // In cm
const float MaxRayTraceDistance = 34300.f;
// Direct Sound. 장애물 없이 직접 전달되는 소리.
if ( bActiveDirectSound ) {
bool isHit = LineTraceSingle( GetActorLocation() ... SoundPosition );
if ( !isHit ) {
float Volume = 1.f;
float Delay = (SoundPosition - GetActorLocation()).Length() / SoundSpeed;
PlaySoundAtLocation(Sound, SoundPosition, Volume, Delay, ...);
}
}
// InDirect Sound. 반사되어 전달되는 소리.
if ( bActiveIndirectSound ) {
TArray<FRotator> RotatorArray = MakeUniformDirections(); // With Fibonacci Sphere
// 전방향으로 Ray cast 시작
for (const FRotator rot: RotatorArray) {
FVector curDir = rot.Vector();
FVector pos = GetActorLocation();
FVector FirstHitPos = pos;
float accumRayTraceDistance = 0.f;
int32 i = 0;
do {
// Reflection ray
FHitResult hitResult;
bool isHit = LineTraceSingle( &hitResult, pos ... pos + d * (MaxRayTraceDistance - accumRayTraceDistance );
if ( !isHit ) // if there is not reflection then break
break;
// Reflection ray hit process
pos = hitResult.Location;
if (i == 0)
FirstHitPos = pos;
d = GetReflectionVector(d, hitResult.Normal);
accumRayTraceDistance += hitResult.Distance;
// Shadow ray (hitpos ... SoundPosition)
FHitResult toSoudnHitResult;
bool toSoundHit = LineTraceSingle( &toSoundHitResult, pos ... SoundPosition );
if ( toSoundHit ) // if blocked then continue
continue;
// Shadow ray hit process
float SoundDistance = accumRayTraceDistance + Distance(pos, SoundPosition);
FVector RelativeLocation = (FirstHitPos - GetActorLocation()).GetSafeNormal() * SoundDistance;
FVector SoundVirtualLocation = GetActorLocation() + RelativeLocation;
float Diffuse = Max(0.f, Dot( (SoundPosition - pos).GetSafeNormal(), hirResult.Normal ));
float Volume = Diffuse;
float Delay = SoundDistance / SoundSpeed;
PlaySoundAtLocation(Sound, SoundVirtualLocation, Volume, Delay, ...);
} while ( ++i < MaxReflection );
}
}
Direct Sound
장애물로 인한 반사 없이 직접 들어오는 소리(Direct Sound)는 Ray 판정과 Delay 처리만 해주고 있다.
// Direct Sound. 장애물 없이 직접 전달되는 소리.
if ( bActiveDirectSound ) {
bool isHit = LineTraceSingle( GetActorLocation() ... SoundPosition );
if ( !isHit ) {
float Volume = 1.f;
float Delay = (SoundPosition - GetActorLocation()).Length() / SoundSpeed;
PlaySoundAtLocation(Sound, SoundPosition, Volume, Delay, ...);
}
}InDirect Sound
장애물에 반사되어 들어오는 소리(InDirect Sound)는 그 소리가 Listener에 닿기까지의 거리, 마지막으로 충돌한 지점의 각도만큼 떨어져 있다고 생각한다.
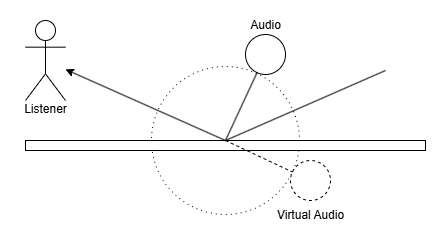
이를 Backward로 역추척하기 위해 Shadow Ray의 길이를 누적하며 (Backward 기준) 처음 충돌한 지점을 저장해둔다. 아래 사진에서 Virtual Audio까지의 거리는 |First Ray| + |Shadow Ray| 만큼이며 각도는 (FirstHitPosition - Listener) 와 같을 것이다.
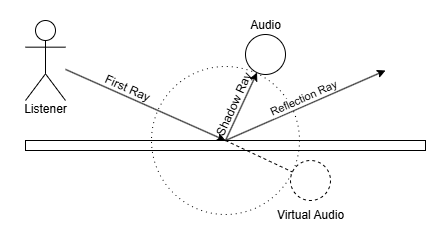
// 해당 소리가 Listener에 닿기까지의 거리.
float SoundDistance = accumRayTraceDistance + Distance(pos, SoundPosition);
// Virtual Audio의 위치 계산
FVector RelativeLocation = (FirstHitPos - GetActorLocation()).GetSafeNormal() * SoundDistance;
FVector SoundVirtualLocation = GetActorLocation() + RelativeLocation;
// Diffuse 크기 계산
float Diffuse = Max(0.f, Dot( (SoundPosition - pos).GetSafeNormal(), hirResult.Normal ));
float Volume = Diffuse;
// Delay 계산
float Delay = SoundDistance / SoundSpeed;
PlaySoundAtLocation(Sound, SoundVirtualLocation, Volume, Delay, ...);때문에 실제 소리가 재생되는 위치는 Listener로부터 방사형으로 분포되어 있다.
한계
Audio Pool limit
위 영상은 처음 쏘는 Ray가 256개, Reflection이 8회 정도로 설정해두고 테스트해본 걸 텐데, Hit point마다 사운드가 하나씩 재생되는 셈이므로 같은 사운드가 약간의 딜레이 차이만 가진 채 최대 2048개 재생될 수가 있다.
하지만 2048개는 너무 많다. 언리얼 엔진에서 최대 재생 가능한 사운드의 개수를 지정해놓고 있진 않지만, 결국 하드웨어 한계상 많아야 128개 정도라고 한다. (프로젝트 기본값은 32개인 듯 하다)
그래서 재생되지 않거나 소리가 유독 작게 들리는 것 같은 어색한 현상이 종종 있다.
Backward RayTracing
Backward Raytracing의 한계인데, 결국 레이가 닿지 않는 곳에는 소리가 전혀 들리지 않는다.
특히 지금처럼 반사만 고려한 상황이라면 굴절(투과), 회절까지 일어나는 실제 소리에 비해 들리지 않는 구간이 발생하곤 한다.
굴절은 Whitted RT처럼 추가하면 되겠지만, 회절은 구현하기 까다로울 듯하다. 회절에 관한 UTD 모델이란게 있다곤 하는데 좀 더 조사해봐야 될 듯 하다.

아주 수준높은 기술적 도전이 보이네요