PCM 데이터를 직접 합성하는 식으로 공간 음향을 구성해 보았다. 결과적으로는, 퀄리티도 성능도 만족할 수 없었다.
구조
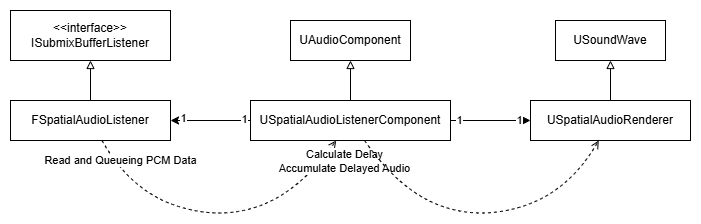
PCM 데이터 가져오기
언리얼에서 public으로 제공하는 API 중에서는 Submix에 들어오는 소리를 읽어들일 수 있는 ISubmixBufferListener::OnNewSubmixBuffer(...)가 있었고, 사실상 유일했다.
그러나 Submix에서 출력된 소리만 가져올 수 있었고, 이를 게임 스레드에서 처리하고 다시 재생시키면 실제 재생된 시간보다 최대 한 틱 늦게 반영이 되는 문제가 있다.
이 외에 FActiveSound가 가지는 WaveInstance를 통해서도 PCM에 접근할 수 있는 듯 보였지만 오디오 처리 스레드에서 내부적으로 접근하는 데이터이고 그 외에 접근할 수 있는 방법이 마땅치 않았다.
일단 PCM 처리를 우선하고자 Submix를 통해 PCM 데이터를 가져오기로 했다.
아래는 인터페이스 ISubmixBufferListener가 요구하는 메소드 OnNewSubmixBuffer(...)의 구현 코드이다.
void FSpatialAudioListener::OnNewSubmixBuffer(
const USoundSubmix* OwningSubmix,
float* AudioData,
int32 NumSamples,
int32 NumChannels,
const int32 SampleRate,
double AudioClock
) {
TSharedPtr<FSpatialAudioData> data = MakeShared<FSpatialAudioData>();
for ( int32 Channel = 0; Channel < NumChannels; ++Channel )
{
data->Channels.Add(TArray<float>());
}
data->NumSamples = NumSamples / NumChannels;
data->StartClock = AudioClock;
TArray<float> RMS;
RMS.AddDefaulted(NumChannels);
for (int32 SampleIdx = 0; SampleIdx < data->NumSamples; ++SampleIdx)
{
for ( int32 Channel = 0; Channel < NumChannels; ++Channel )
{
float Sample = AudioData[SampleIdx * NumChannels + Channel];
data->Channels[Channel].Add(Sample);
RMS[Channel] += Sample * Sample;
}
}
// check submix is active with RMS
bool IsActive = false;
for (int32 Channel = 0; Channel < NumChannels; ++Channel)
{
RMS[Channel] = FMath::Sqrt(RMS[Channel] / data->NumSamples);
if ( RMS[Channel] > KINDA_SMALL_NUMBER )
IsActive = true;
}
if ( !IsActive )
return;
if (!OutputBuffer.Contains(OwningSubmix))
{
OutputBuffer.Add(OwningSubmix, MakeShared<TQueue<TSharedPtr<FSpatialAudioData>>>().ToSharedPtr());
}
OutputBuffer[OwningSubmix].Get()->Enqueue(data);
}주의할 점들은 다음이 있다.
- PCM 데이터 형식은 Interleaved로, 샘플이 채널별로 교차되어 나타나 있다.
그러니까LeftSample1, RightSample1, LeftSample2, RightSample2, ...순으로 나열돼 있다. OnNewSubmixBuffer의 인자로 주어지는NumSamples는 이미 채널의 갯수가 고려되어 있다.OnNewSubmixBuffer는 오디오 스레드 (AudioMixerRender Thread)에서 실행된다. TQueue는 스레드 안전하므로 이를 이용해 데이터를 전달하자.
소리 구현하기
Ray별 소리의 크기
Listener로부터 발사된 모든 Ray가 음원과 이어진다면, 거리 감쇠 등 다른 요인을 고려하지 않을 때 그 소리의 크기는 1과 같아야 할 것이다.
Ray마다 전달되는 소리의 크기가 모두 똑같다고 가정한다면, 이론상 에너지 보존 법칙에 따라 Ray마다 전달되는 소리의 크기는 Ray의 갯수 의 역수와 같을 것이다.
그리고 음압은 에너지의 제곱근에 비례하므로 우리가 다룰 볼륨은 의 역제곱근에 비례할 것이다.
코드상으론 미리 설정된 RayCount 외에도 Listener의 채널마다도 Ray를 별도로 생성하기 때문에 NumChannels 갯수를 포함한다.
const float VolumePerRay = FMath::Pow(1.f / (RayCount + NumChannels), 0.5f);Ray 판정
Ray 판정은 이전 게시물과 같이 가상의 음원 위치를 계산해서 해당 위치까지의 방향과 거리를 계산한다.
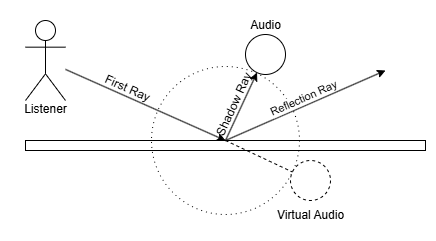
거리 감쇠
흔히 역제곱 법칙이 적용된다는 소리의 크기는 에너지 단위에서의 크기이다. 음압은 거리의 역수에 비례한다.
ILD, ITD
양쪽 귀 사이 거리와 방향의 차이로, 하나의 소리도 각 귀에 시간과 크기 차이를 두고 들리게 된다. 각각 Inter-aural Level Difference 및 Inter-aural Time Difference의 접두어로 ILD가 크기 차이, ITD가 시간 차이를 뜻한다.
좀 더 나아가면 채널별로 각 크기 및 시간 차이를 둘 수도 있다. 지금은 좌/우 2개의 채널만 있고, 각각에 Listener가 있다고 생각한다.
ITD는 가상의 음원 위치와 각 Listener의 위치 간 거리를 통해 시간 차이를 계산할 수 있다.
ILD는 계산 방법이 여러가지인데, Listener가 향하는 방향과 음원이 향하는 방향을 내적한 cos 값을 이용하기로 했다. 단순히 Clamp를 걸면 반대쪽에서 소리가 전혀 안들리게 되어서 [1, 0] 범위에 cos가 왔다갔다하도록 보정하였다.
// Delay (Distance Delay + ITD) by Channels
double Delay = TotalDistance / SoundSpeed;
ChannelsDelay.Add(Delay);
// Volume (Distance Attenuation * ILD) by Channels
FVector ChannelDirection = ChannelLocalPosition.GetSafeNormal();
float ILD = (FVector::DotProduct(ChannelDirection, ListenerToFirstHitDirection) + 1.f) / 2.f;이때 ILD의 크기가 정규화되지 않았으므로 따로 정규화 과정을 거친다.
TotalILDSqaured += ILD * ILD;
ChannelsVolume.Add(VolumePerRay * DiffuseAttenuation * DistanceAttenuation * ILD);
// adjust ILD
float TotalILD = FMath::Sqrt(TotalILDSqaured);
for ( uint32 ChannelIdx = 0; ChannelIdx < NumChannels; ++ChannelIdx ) {
ChannelsVolume[ChannelIdx] /= TotalILD;
}저장
각 Ray별 Delay를 FAudioDelayInfo란 구조체에 저장한다. 이때 시간순으로 pop할 수 있도록 HeapPush(...), HeapPop(...)을 사용한다.
struct FAudioDelayInfo
{
double PlaybackClock;
double StartClock;
double EndClock;
float StartVolume;
float EndVolume;
TSharedPtr<FSpatialAudioData> AudioData;
// for continuos playback
int32 HitPointInfoIdx;
FAudioDelayInfo* NextDelayInfo;
bool operator<(const FAudioDelayInfo& other) const {
return StartClock < other.StartClock;
}
};
// Audio Delay Priority Queue by Channels
TArray<TArray<FAudioDelayInfo>> AudioDelayQueue;소리 재생하기
USpatialAudioListenerComponent::RenderAudios(...)에서 Delay된 소리들을 누적, 종합하는 과정을 거치고, 이를 USpatialAudioRenderer로 전달한다.
그리고 USoundWave의 인터페이스를 구현한 USpatialAudioRenderer::GeneratePCMData(...)에서 소리를 재생시킨다.
int32 USpatialAudioRenderer::GeneratePCMData(uint8* PCMData, const int32 SamplesNeeded)
{
int16* Data = reinterpret_cast<int16*>(PCMData);
int32 NumSample = FMath::Min(SamplesNeeded, NumSamplesToGeneratePerCallback);
int32 NumWrittenSample = 0;
TArray<int32> NumWrittenSampleByChannel;
int32 MaxNumWrittenSampleByChannel = 0;
NumWrittenSampleByChannel.AddDefaulted(NumChannels);
Audio::EAudioMixerStreamDataFormat::Type Format = GetGeneratedPCMDataFormat();
SampleByteSize = (Format == Audio::EAudioMixerStreamDataFormat::Int16) ? 2 : 4;
{
FScopeLock Lock(&AudioBufferMutex);
if ( AudioBuffer.Num() == 0 )
UE_LOG(LogTemp, Warning, TEXT("AudioBuffer is null"));
for ( int32 Channel = 0; Channel < NumChannels; ++Channel )
{
int32 NumSampleInChannel = AudioBuffer[Channel].Num();
for ( int32 SampleIdx = 0; SampleIdx < FMath::Min(NumSample, NumSampleInChannel); ++SampleIdx ) {
float Sample = AudioBuffer[Channel][SampleIdx];
int16 PCMSample = FMath::Clamp(Sample * 32767.0f, -32768.0f, 32767.0f);
Data[NumChannels * SampleIdx + Channel] = PCMSample;
++NumWrittenSample;
++NumWrittenSampleByChannel[Channel];
}
MaxNumWrittenSampleByChannel = FMath::Max(NumWrittenSampleByChannel[Channel], MaxNumWrittenSampleByChannel);
}
for ( int32 Channel = 0; Channel < NumChannels; ++Channel )
{
if ( !AudioBuffer[Channel].IsEmpty() )
AudioBuffer[Channel].RemoveAt(0, NumWrittenSampleByChannel[Channel]);
AudioBuffer[Channel].AddDefaulted(AudioBufferMaxSize - AudioBuffer[Channel].Num());
}
}
{
FScopeLock Lock(&QueueEndAudioClockMutex);
// trace queued time
for ( int32 Channel = 0; Channel < NumChannels; ++Channel )
{
QueuedEndAudioClock[Channel] = FMath::Max(GetAudioClock(), QueuedEndAudioClock[Channel]) + NumWrittenSampleByChannel[Channel] / static_cast<double>(SampleRate);
}
}
return MaxNumWrittenSampleByChannel * NumChannels * sizeof(int16);
}이때 주의점은 다음과 같다.
GeneratePCMData(...)를 이용하려면bProcedural플래그가 켜져 있어야 한다.GeneratePCMData(...)역시 다른 스레드에서 실행되기 때문에, ScopeLock을 사용한다.GeneratePCMData(...)는 새로 쓰인 샘플의 바이트수를 반환해야 한다. 참고.
한계
연속성
OnNewSubmixBuffer(...)로 제공되는 오디오는 일정한 크기 단위로 분할되어 전달된다. 이 블럭들이 이어지며 GeneratePCMData(...)에서 재생되어야 연속적으로 잘 들릴 것이다.
Listener와 음원이 고정되어 있고 환경이 변화하지 않는다면 각 Ray로 계산되는 Delay로 변하지 않아서 연속적으로 잘 이어지겠지만, 움직이기 시작하는 순간 Ray별 Delay가 달라지며 이전 블럭의 끝과 다음 블럭의 시작이 맞지 않게 되며 소리가 튀는 현상이 나타나게 된다.
아래 왼쪽은 움직이지 않아 Delay1, Delay2가 일정한 상황을 보여주며, 오른쪽은 움직이면서 Ray 길이가 달라져 Delay1, Delay2가 변화하는 상황을 보여준다. 오른쪽의 경우 각 블럭이 겹치거나 떨어지는 현상이 나타난다.
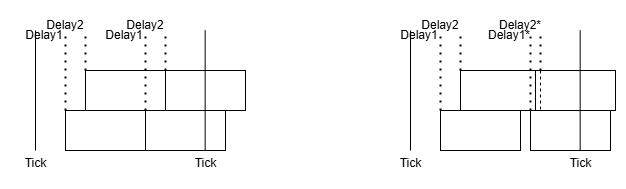
아래는 움직이는 도중의 sin파를 오디오 인사이트로 본 것이다. 프레임별로 쪼개 보면 튀거나 뚝 끊기는 부분이 나타난다.
이를 보정하고자 각 블럭에 StartClock, EndClock 등을 저장하도록 데이터를 추가해서 블럭의 길이를 늘리거나 줄이는 방법도 적용해봤지만 퀄리티가 영 좋지 못했다.
void USpatialAudioListenerComponent::RenderAudios(float deltaTime)
{
double AudioClock = GEngine->GetActiveAudioDevice()->GetAudioClock();
// mix up audios to buffer
for (uint32 ChannelIdx = 0; ChannelIdx < NumChannels; ++ChannelIdx)
{
TArray<FAudioDelayInfo>& Channel = AudioDelayQueue[ChannelIdx];
TArray<FAudioDelayInfo> RenderedAudios;
if ( Channel.IsEmpty() )
continue;
// Global Audio Clock on SoundQueue->AudioBuffer[0]
double BufferStartClock = SoundQueue->GetBufferStartClock(ChannelIdx);
double BufferEndClock = SoundQueue->GetBufferEndClock(ChannelIdx);
// if Audio Range is intersected with Audio Clock Frame, push to RenderedAudios
while ( !Channel.IsEmpty() && Channel.HeapTop().StartClock < BufferEndClock )
{
FAudioDelayInfo DelayInfo;
Channel.HeapPop(DelayInfo);
if ( BufferStartClock < DelayInfo.EndClock )
RenderedAudios.Add(DelayInfo);
}
{
FScopeLock Lock(&SoundQueue->AudioBufferMutex);
for ( FAudioDelayInfo& DelayInfo : RenderedAudios )
{
const uint64 NumAudioSample = DelayInfo.AudioData->NumSamples;
int32 SampleIdxStart = FMath::Max(0, FMath::RoundToInt32((DelayInfo.PlaybackClock - BufferStartClock) * SampleRate));
double AudioDuration = NumAudioSample / static_cast<double>(SampleRate);
double RealDuration = DelayInfo.EndClock - DelayInfo.StartClock;
double CurDopplerCoef = RealDuration / AudioDuration;
if ( DelayInfo.NextDelayInfo != nullptr && 0.75 < CurDopplerCoef && CurDopplerCoef < 1.5 ) {
DopplerCoef = CurDopplerCoef;
}
double CurAudioClock;
for ( uint32 SampleIdx = SampleIdxStart; SampleIdx < SoundQueue->AudioBufferMaxSize; ++SampleIdx ) {
// Global Audio Clock on SoundQueue->AudioBuffer[SampleIdx]
CurAudioClock = BufferStartClock + SampleIdx / static_cast<double>(SampleRate);
//Sample Index in Delayed Audio Source
int32 AudioSampleIdx = FMath::RoundToInt32((CurAudioClock - DelayInfo.StartClock) / DopplerCoef * SampleRate);
if ( AudioSampleIdx >= NumAudioSample )
break;
float AudioSample = DelayInfo.AudioData->Channels[ChannelIdx][AudioSampleIdx];
AudioSample *= FMath::Lerp(DelayInfo.StartVolume, DelayInfo.EndVolume, AudioSampleIdx / static_cast<float>(NumAudioSample));
SoundQueue->AudioBuffer[ChannelIdx][SampleIdx] += AudioSample;
}
DelayInfo.PlaybackClock = CurAudioClock;
}
}
for ( const FAudioDelayInfo& DelayInfo : RenderedAudios )
{
Channel.HeapPush(DelayInfo);
}
}
//int32 RenderSampleCount = deltaTime * SampleRate;
//TArray<uint8> Queue;
//ConvertAudioBufferToPCMData(RenderSampleCount, Queue);
//SoundQueue->QueueAudio(Queue.GetData(), Queue.Num());
}무엇보다 다음 틱의 StartClock을 알 수 없어 결국 끊김이 발생할 수 밖에 없는 문제에 맞딱드렸다.
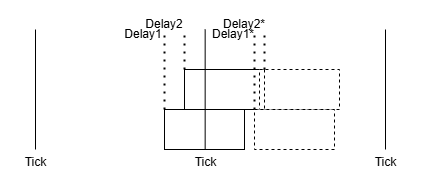
etc
GEnigne->GetMainAudioDevice()가 있고GEnigne->GetActiveAudioDevice()가 있는데 전자는 잘 작동하지 않는다. 참고.
Convolution Reverb
Impulse Response를 이용해 Convolution Reverb를 만들 수도 있고, 직접 샘플을 합성한다면 이 방식이 더 적절할 수도 있겠다.
다만 Convolution의 처리 속도도 고려해야 할 것이다.
