논문 제목: Arachne: Search-Based Repair of Deep Neural Networks
📕 Summary
Abstract
이 논문은 '아라크네(Arachne)'라는 딥 뉴럴 네트워크(DNN)를 위한 프로그램 수리 기법을 소개합니다. 아라크네는 입력-출력 쌍을 사용해 DNN의 문제를 직접 수정하고, 신경 가중치를 국소화하며, 차분 진화를 사용해 가중치를 최적화하고 잘못된 행동을 수정합니다. 이 기법은 특정한 잘못된 분류를 수정하고 공정성 문제를 해결하는 데 효과적임을 보여줍니다.
Introduction

📕 Solution
Method: Arachne
아라크네는 딥 뉴럴 네트워크(DNN)의 문제를 해결하기 위한 강력한 방법으로, 다음과 같은 단계를 통해 작동합니다:
-
신경 가중치 조작: 아라크네는 DNN 내의 신경 가중치 값을 직접 조정하여 네트워크를 수리합니다.
-
양방향 국소화(BL): 이 방법은 각 가중치의 그래디언트 손실과 전방 영향을 고려하여, 문제가 되는 신경 가중치를 정확하게 찾아냅니다.
-
중요 가중치 식별: BL을 통해 아라크네는 잘못된 분류의 원인이 되는 주요 신경 가중치를 파악하고, 이를 수정할 필요가 있음을 확인합니다.
-
효과적인 패치 생성: '차분 진화(Differential Evolution, DE)'라는 기법을 사용하여 문제가 있는 가중치를 위한 효과적인 수정안(패치)을 만듭니다.
-
패치 최적화: DE를 이용해 생성된 패치를 최적화하여 DNN의 오류를 수정합니다.
-
효과성 검증: 아라크네는 DNN의 정확도를 크게 떨어뜨리지 않으면서 잘못된 분류를 효과적으로 수정하는 것으로 입증되었습니다.
-
공정성 개선: 아라크네는 성별 분류 모델 등에서 편향을 줄이는 데에도 사용될 수 있어, 공정성 문제 해결에 기여합니다.
-
다양한 분야 적용: 이미지 분류와 텍스트 감정 분석 등 다양한 분야에 적용될 수 있는 범용성을 가진 기술입니다.
아라크네는 이러한 고유한 접근 방식을 통해 DNN의 문제를 효과적으로 해결하고, 더 공정하고 정확한 머신 러닝 모델을 구축하는 데 기여합니다.
BL (Bidirectional Localization)
양방향 국소화(Bidirectional Localization, BL)는 아라크네에서 사용되는 중요한 기법으로, 딥 뉴럴 네트워크(DNN)의 오류를 일으키는 신경 가중치를 정확하게 찾아내는 데 사용됩니다. BL은 두 가지 주요 요소를 고려합니다:
- 그래디언트 손실: 가중치가 잘못된 분류에 얼마나 영향을 미쳤는지를 평가합니다.
- 전방 영향: 가중치가 최종 분류 결과에 얼마나 기여하는지를 측정합니다.
이러한 요소들을 바탕으로, BL은 잘못된 분류에 가장 큰 영향을 미치는 가중치를 식별하고, 이들을 조정하여 전체 분류의 정확도를 향상시키는 데 중점을 둡니다. 이는 DNN의 수리에서 가장 중요한 부분을 표적으로 삼아, 보다 효과적이고 정밀한 개선을 가능하게 합니다.
다른 기술들이 전체 신경 세포에 초점을 맞춘다면, BL은 더 세밀한 수준인 개별 가중치에 초점을 맞춥니다. 이렇게 함으로써, 아라크네는 문제가 있는 구체적인 부분에 대한 정확한 패치를 생성하고, 차분 진화(Differential Evolution, DE)를 이용해 이 패치를 최적화하여 DNN의 오류를 보다 효과적으로 수정할 수 있습니다.
간단히 말해서, BL은 DNN의 정확도를 향상시키기 위해 문제의 원인을 정밀하게 찾아내고 수정하는 고급 기술입니다.
DE (Differential Evolution)
차분 진화(Differential Evolution, DE)는 딥 뉴럴 네트워크(DNN)를 위한 아라크네의 프로그램 수리 기술에서 사용되는 메타-휴리스틱 최적화 알고리즘입니다. DE는 DNN의 국소화된 가중치에 대한 효과적인 패치를 생성하는 목표를 가진 검색 기반 수리 기법입니다. 이것은 집단 기반 알고리즘으로, 후보 해결책을 반복적으로 개선합니다. 이 과정은 변이(mutation), 교차(crossover), 선택(selection) 작업을 통해 후보 해결책의 특성을 결합합니다.
아라크네는 DE를 사용하여 DNN의 신경 가중치를 조정함으로써 패치를 찾습니다. DE의 초기 집단은 각 매개변수(즉, 국소 신경 가중치)의 초기 값들을 가우시안 분포에서 샘플링하여 초기화합니다. DE는 연속적인 검색 공간에서 효과적임이 입증되었으며, 아라크네에서 DNN 이미지 분류기의 잘못된 분류를 수정하는 데 성공적으로 적용되었습니다.
간단히 말해서, DE는 아라크네가 DNN의 문제를 정밀하게 해결할 수 있도록 돕는 고급 알고리즘입니다. 이는 효과적인 패치를 찾아 DNN의 성능을 향상시키는 데 중요한 역할을 합니다. 이 기술은 학생들이 이해하기 쉬우면서도 전문적인 수준의 최적화 방법을 제공합니다.
📕 Conclusion
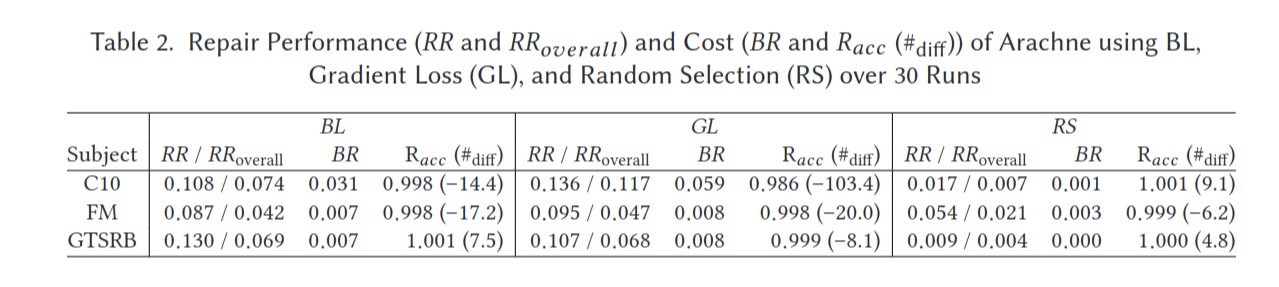
이 표는 세 가지 다른 데이터셋인 CIFAR-10 (C10), Fashion MNIST (FM), 그리고 독일 교통 표지판 인식 벤치마크(GTSRB)에 대해 Arachne 프로그램 수리 기법의 성능과 비용 메트릭을 보여줍니다. 성능과 비용은 양방향 국소화(BL), 그래디언트 손실(GL), 그리고 무작위 선택(RS) 세 가지 다른 방법을 사용하여 평가되었으며, 30회 실행에 대한 메트릭이 계산되었습니다.
표에서 나타나는 메트릭을 분석하면 다음과 같습니다:
-
RR / RRoverall: 수리율(RR)과 전체 수리율(RRoverall)을 나타냅니다. RR은 수리 기법이 성공적으로 수정한 분류 오류의 비율을 나타내며, RRoverall은 모든 실행에 걸친 기법의 성공을 고려합니다.
-
BR: 기본 비율(BR)은 수리 기법 적용 전에 DNN이 원래 올바르게 분류한 입력의 비율입니다. 모델의 초기 정확도를 측정하는 지표입니다.
-
Racc (#diff): 수리된 모델의 정확도(Racc)와 수리 전후의 정확도 차이(#diff)입니다. #diff 값이 양수인 경우는 정확도가 향상되었음을 나타내고, 음수인 경우는 수리 후 정확도가 감소했음을 나타냅니다.
표를 분석해보면:
-
BL의 경우, RR은 데이터셋에 따라 다양하지만, GTSRB에서 가장 높은 수리율을 보입니다. RRoverall은 RR보다 낮은데, 이는 모든 실행이 동등하게 성공적이지 않았음을 나타냅니다. Racc는 수리 후 매우 높은 정확도를 보여주며, 1에 가깝습니다. 괄호 안의 숫자(#diff)는 정확도의 변화를 나타내며, C10과 FM에 대해 감소를, GTSRB에 대해서는 향상을 나타냅니다.
-
GL은 C10에 대해 BL보다 약간 더 높은 RR 값을 보이지만 FM과 GTSRB에 대해서는 낮습니다. BR도 BL에 비해 낮아, GL이 더 낮은 초기 정확도에서 시작했음을 나타냅니다. 수리 후 정확도(Racc)는 BL보다 약간 낮으며, C10에 대한 #diff 값은 크게 음수로, 수리 후 정확도가 크게 감소했음을 나타냅니다.
-
RS는 예상대로 무작위 방법이므로 RR과 RRoverall 값이 가장 낮습니다. BR 값도 가장 낮아 세 방법 중 초기 정확도가 가장 낮음을 나타냅니다. Racc는 약 1이지만 #diff 값은 작아 수리 후 정확도의 변화가 미미하며, 양수와 음수 모두를 나타냅니다.
요약하자면, 이 표는 BL이 일반적으로 DNN을 수리하는 데 있어서 특히 GTSRB에 대해 수리 후 높은 정확도를 유지하며 잘 수행됨을 나타냅니다. GL은 C10에 대해 큰 정확도 하락을 보여 일관성이 떨어집니다. RS
는 그 무작위적 성격을 고려했을 때 예상대로 가장 효과가 낮은 방법입니다.
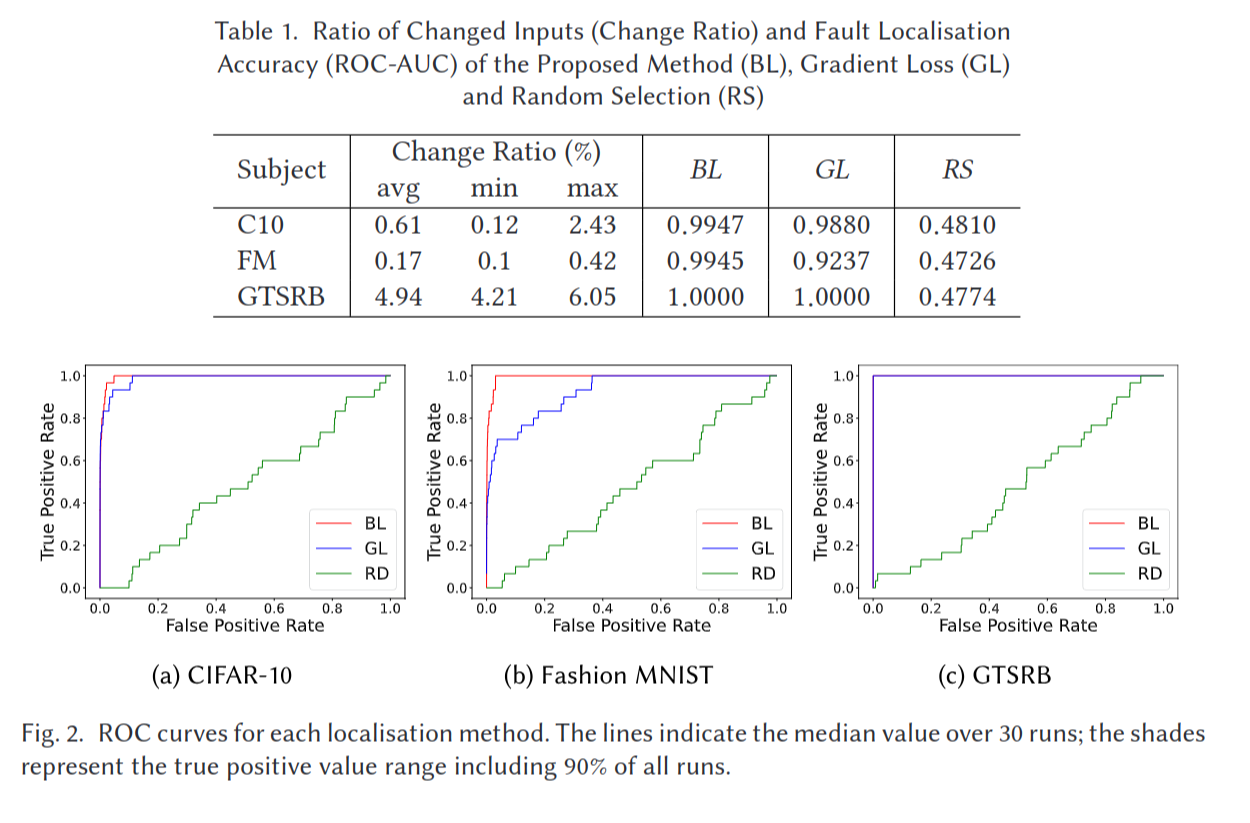
제공된 결과에는 표와 세 개의 수신기 조작 특성(ROC) 곡선이 포함되어 있으며, 이는 기계 학습 모델에서 오류 위치 지정 방법의 성능을 평가하는 데 사용됩니다:
-
표 1:
- 이 표는 CIFAR-10 (C10), Fashion MNIST (FM), 그리고 독일 교통 표지판 인식 벤치마크(GTSRB)라는 세 가지 데이터셋에 대한 "변경 비율"과 "오류 위치 지정 정확도(ROC-AUC)"를 보여줍니다.
- "변경 비율"은 분류 오류를 수정하기 위해 수리 기법에 의해 수정된 입력의 백분율을 측정하며, 평균(avg), 최소(min), 최대(max) 값으로 나뉩니다.
- "오류 위치 지정 정확도"는 ROC-AUC 점수로 측정되며, 이는 0부터 1까지의 범위를 가지며, 여기서 1은 완벽한 정확도를 나타냅니다. 높은 값이 더 좋습니다. 비교되는 방법은 제안된 방법(BL), 그래디언트 손실(GL), 그리고 무작위 선택(RS)입니다.
표에서 우리는 BL이 일반적으로 ROC-AUC 점수가 1에 가장 가까워 가장 좋은 성능을 나타낸다는 것을 볼 수 있습니다. RS는 가장 낮은 점수를 가지며, 가장 정확도가 낮음을 나타냅니다.
-
ROC 곡선(그림 2):
- 그래프는 세 데이터셋(CIFAR-10, Fashion MNIST, GTSRB)에 대한 세 가지 방법(BL, GL, RD)의 ROC 곡선을 보여줍니다.
- ROC 곡선은 진정한 양성 비율(TPR)과 거짓 양성 비율(FPR) 사이의 절충을 보여줍니다. TPR(y축)은 모델이 양성을 정확하게 식별하는 비율입니다. FPR(x축)은 모델이 부정적인 것을 양성으로 잘못 식별하는 비율입니다.
- 완벽한 모델은 곡선이 y축을 따라 직선으로 올라가고 x축 상단을 따라 가는 모양(왼쪽 상단 모서리에 완벽한 직각)을 가질 것입니다. 곡선 아래의 면적(AUC)이 클수록 모델이 더 좋습니다.
ROC 곡선에서 우리는 CIFAR-10과 Fashion MNIST에 대해 BL과 GL이 RD보다 왼쪽 상단 모서리에 더 가까워 더 나은 성능을 나타내는 것을 볼 수 있습니다. GTSRB에 대해 BL과 GL 곡선은 겹치고 왼쪽 상단 모서리에 있으며 AUC가 1인 탁월한 성능을 보여줍니다.
요약하자면, BL은 세 데이터셋 모두에서 다른 방법들보다 오류 위치 지정 정확도가 뛰어납니다. ROC 곡선은 BL과 GL이 특히 RD에 비해 더 높은 TPR을 보여주며 이러한 결과를 지지합니다.
Contribution
아라크네라는 새로운 딥 뉴럴 네트워크(DNN) 수리 기법을 소개합니다. 아라크네는 입력-출력 쌍을 기반으로 DNN을 직접 수리하고, 신경 가중치를 국소화하여 잘못된 행동을 수정하는 효과적인 패치를 생성합니다.
아라크네는 최신 DNN 수리 기법인 에이프리콧과 다양한 벤치마크를 사용해 평가되었습니다. 실증 연구에 따르면 아라크네는 DNN의 특정 잘못된 분류를 수정할 수 있으며, 일반적인 정확도를 크게 떨어뜨리지 않습니다. 아라크네에 의해 생성된 패치는 보이지 않는 잘못된 행동의 61.3%에서 일반화되며, 에이프리콧보다 뛰어난 성능을 보입니다.
또한, 논문은 아라크네가 성별 분류 모델의 편향을 줄임으로써 공정성 문제를 해결할 수 있음을 보여줍니다. 아라크네는 텍스트 감정 모델에도 성공적으로 적용되어, 컨볼루셔널 신경망을 넘어서는 일반화 가능성을 입증합니다.
이 논문은 LFW 벤치마크를 사용한 사례 연구를 통해 아라크네가 성별 분류기의 공정성 문제를 해결하기 위해 모델을 재조정하는 방법을 보여줍니다. 또한, 트위터 벤치마크를 사용하여 이미지 분류 이외의 분야에서 아라크네의 효과성을 평가합니다.
이 논문은 검색 기반 소프트웨어 엔지니어링과 기계 학습 분야에 기여하며, DNN 수리를 위한 효과적인 프로그램 수리 기법인 아라크네를 소개합니다.
