1. API

- 클라이언트 프로그램과 서버 사이의 데이터 전달자
- 클라이언트 프로그램은 API를 통하여 요청을 하고, 서버는 API를 통하여 결과 데이터 전달
- 소프트웨어 간에 데이터를 교환하고 통신할 수 있도록 하는 인터페이스 제공
- Request
- API 주소 + API 키
- Request 형식 : 요청 양식
- Response
- Response 형식 : 결과 양식
1-1. ChatGPT API 발급
- OpenAI 접속 -> 로그인 -> API 선택 -> API Keys -> 이름 입력 후 키 생성
- API 키를 복사하여 따로 보관해야 함(잊어버릴 시 재발급)
- 인터넷 상에 API 키가 노출 될 경우 API 키가 소멸
1-2. ChatGPT API를 활용한 질문하기
import pandas as pd
import numpy as np
import os
import openai
from openai import OpenAI
api_key = '~~~~~~'
os.environ['OPENAI_API_KEY'] = api_key
openai.api_key = os.getenv('OPENAI_API_KEY') # 코랩 가상환경 변수로 등록
def ask_chatgpt1(question):
# api key 지정이 필요하나
# 위에서 환경변수로 지정했기에 지금은 지정이 필요없음
client = OpenAI()
# # API를 사용하여 'gpt-3.5-turbo' 모델로부터 응답을 생성
response = client.chat.completions.create(
model="gpt-3.5-turbo", # 사용 모델
messages=[
{"role": "system", "content": "You are a helpful assistant."}, # 시스템의 기본 역할 부여
{"role": "user", "content": question}, # 유저의 질문 설정
]
)
return response.choices[0].message.content # 응답 양식
question = "한국에서 제일 높은 산이 뭔가요?"
response = ask_chatgpt1(question)
print(response)2. NLP(Natural Language Processing)
- 컴퓨터가 인간의 언어를 이해시키기 위한 처리 방법
- 단어의 개별적 이해 뿐만 아니라 해당 단어의 맥락을 이해해야 함
- 문장의 감정 파악, 이메일 스팸 여부 감지, 질문에 대한 답변, 번역 등
2-1. 기존 NLP(RNN 기반)의 단점
- 병렬 처리의 어려움
- 장기 의존성 문제
- 확장성 제한
3. Transformer
- RNN 모델의 단점 극복
- Transformer를 통하여 LLM이 발전
3-1. 특징
- 이전 문장들을 기억
- 문맥상 집중해야하는 단어를 잘 선택함
- 문장이나 단어 사이의 문맥을 파악하는 데 탁월한 능력
- Attention
3-2. pipeline 함수를 통한 쉬운 구현
- pipeline 함수를 사용하여 transformer 기반 LLM 모델을 손쉽게 사용
from transformers import pipeline
classifier = pipeline(task = 'sentiment-analysis', model = 'bert-base-multilingual-cased')- pipeline으로 사용 가능한 언어 관련 task
- sentiment-analysis
- 감성 분석
- 주어진 문장에 대해 긍정, 부정 분류
- zero-shot-classification
- 학습 과정에서 본 적 없는 클래스에 대해 분류
- 학습 되지 않은 데이터라도 유사성을 비교하여 가장 유사한 곳으로 분류
- summarization
- 문장이나 글을 요약
- translation
- 번역
- text-generation
- 몇 글자를 적어서 입력하면, 이어서 문장 생성
- feature-extraction
- fill-mask
- ner
- question-answering
- sentiment-analysis
3-3. pipeline 함수로 NLP 구현
!pip install transformers==4.37.1 # 사용 버전
from transformers import pipeline
# pipeline으로 모델 생성할 경우 파라미터가 모두 기본값으로 설정됨3-3-1. 감성 분석
classifier = pipeline(task = "sentiment-analysis", model = 'bert-base-multilingual-cased')
# 모델 사용
text = ["I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
"I have a dream.",
"She was so happy."]
classifier(text) # 값 : 그 값일 확률
# LABEL의 정확한 의미는 해당 모델의 문서 참조 필요
# 주로 LABEL_0는 부정을 의미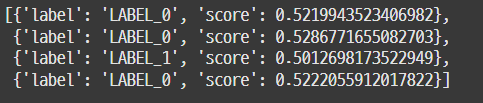
# sentiment-analysis 모델 파이프라인 생성
# 기본값 : distilbert-base-uncased-finetuned-sst-2-english
# bert 경량화한 모델, 파인 튜닝이 진행된 상태
classifier = pipeline("sentiment-analysis")
# 모델 사용
text = ["I've been waiting for a HuggingFace course my whole life.",
"I hate this so much!",
"I have a dream.",
"She was so happy."]
classifier(text) # 값 : 그 값일 확률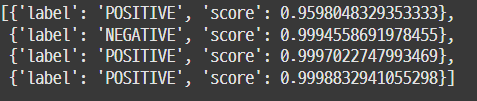
3-3-2. Zero-shot classification
classifier = pipeline(task = "zero-shot-classification", model="facebook/bart-large-mnli")
# 분류 후보 label
candidate_labels = ["tech", "politics", "game", "food"]
# 분류 데이터(햄버거 제조법)
text = '''Pacle the bottom bun in the dish. put the tomato on the bun. put the patty on the tomato.
put the lettuce on the patty. put the onion on the lettuce. put the cheese on the onion. put the top bun to finish'''
# 분류 수행
result = classifier(text, candidate_labels)
# 결과 출력
print(f"Labels: {result['labels']}")
print(f"Scores: {result['scores']}")
# 해당 데이터는 음식과 가장 유사성이 높음
3-3-3. 번역
# 한국어에서 영어로 번역
translator_ko_to_en = pipeline(task = "translation", model="halee9/translation_en_ko")
# 번역하고자 하는 한국어 텍스트
text_ko = "수업 듣기 귀찮아. 집에 가고 싶어. 근데 난 이미 집인걸? 너무 슬퍼"
# 번역 수행
translated_text_en = translator_ko_to_en(text_ko, max_length=60) # 번역 결과가 60 토큰을 넘지 않음
# 번역된 영어 텍스트 출력
print(f"Translated Text (KO to EN): {translated_text_en[0]['translation_text']}")
3-3-4. 요약
3-3-4-1. 영문 텍스트 요약
# 텍스트 요약 파이프라인 생성
summarizer = pipeline(task = "summarization", model="facebook/bart-large-cnn")
# 요약하고자 하는 여러 문장이나 긴 텍스트(홍길동 소개글)
text = """
Hong Gil-dong is a famous character from Korean folklore, often described as a hero similar to Robin Hood.
Born as the illegitimate son of a nobleman, he faced discrimination and hardships in society.
Despite this, he possessed extraordinary talents in martial arts and intelligence.
Determined to fight against corruption and social injustice, Gil-dong became a leader of a band of outlaws, using his skills to help the poor and oppressed.
His story symbolizes the pursuit of justice and equality, making him one of Korea’s most beloved folk heroes.
"""
# 텍스트 요약 수행
summary = summarizer(text, max_length=80, min_length=30, do_sample=False)
# 요약된 텍스트 출력
print(f"Summary: {summary[0]['summary_text']}")
'''
Summary: Hong Gil-dong is a famous character from Korean folklore,
often described as a hero similar to Robin Hood. Born as the illegitimate
son of a nobleman, he faced discrimination and hardships in society.
Despite this, he possessed extraordinary talents in martial arts
and intelligence.
'''3-3-4-2. 한글 텍스트 요약
# 텍스트 요약 파이프라인 생성
summarizer = pipeline("summarization", model="ainize/kobart-news")
# 홍길동
input_text = '''
홍길동은 한국 고전 소설 『홍길동전』의 주인공으로, 조선시대의 전설적인 인물입니다.
그는 서자 출신으로 태어나 사회적 차별을 받지만, 뛰어난 능력과 용기 덕분에 자신의 운명을 개척합니다.
홍길동은 도적이 되어 불의를 처치하고, 억압받는 사람들을 돕는 영웅적인 역할을 합니다.
결국 그는 자신의 이상을 실현하기 위해 새로운 나라를 세우고, 정의와 평화를 추구하는 인물로 그려집니다.
이 작품은 사회적 불평등과 정의, 인간의 삶의 의미에 대한 깊은 성찰을 담고 있습니다.
'''
# 텍스트 요약 수행
summary = summarizer(input_text)
# 요약된 텍스트 출력
print(f"Summary: {summary[0]['summary_text']}")
'''
Your max_length is set to 128, but your input_length is only 108. Since this is a summarization task, where outputs shorter than the input are typically wanted, you might consider decreasing max_length manually, e.g. summarizer('...', max_length=54)
Summary: 홍 고전 소설 『홍길동전』의 주인공이자 조선시대의 전설적인 인물인 홍길동은 자신의 이상을 실현하기 위해 새로운 나라를 세우고, 정의와 평화를 추구하는 인물로 그려집니다.
'''3-3-5. 문장 생성
# 영문 생성 모델 다운로드
generator = pipeline("text-generation", model="distilgpt2")
generator("Wake up in the morning",
max_length=30, # 생성할 최대 토큰 수
num_return_sequences=3) # 생성할 문장 수
'''
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
[{'generated_text': "Wake up in the morning, you don't see me on the roof of your tent in any other way. That's what I've said."},
{'generated_text': 'Wake up in the morning, not out of curiosity and the good news.\nWhile looking inside, the two kids started laughing, and now they'},
{'generated_text': "Wake up in the morning. Don't ever get up late, or your friend is dead."}]
'''4. Hugging Face
- 자연어 처리(NLP) 및 인공 지능(AI) 분야에서 가장 인기 있는 오픈 소스 라이브러리와 모델을 제공하는 플랫폼
- transformers 라이브러리 제공
- 사전 훈련된 다양한 Transformer 기반 LLM모델(BERT, GPT 등) 쉽게 사용
4-1. Hugging Face 사용
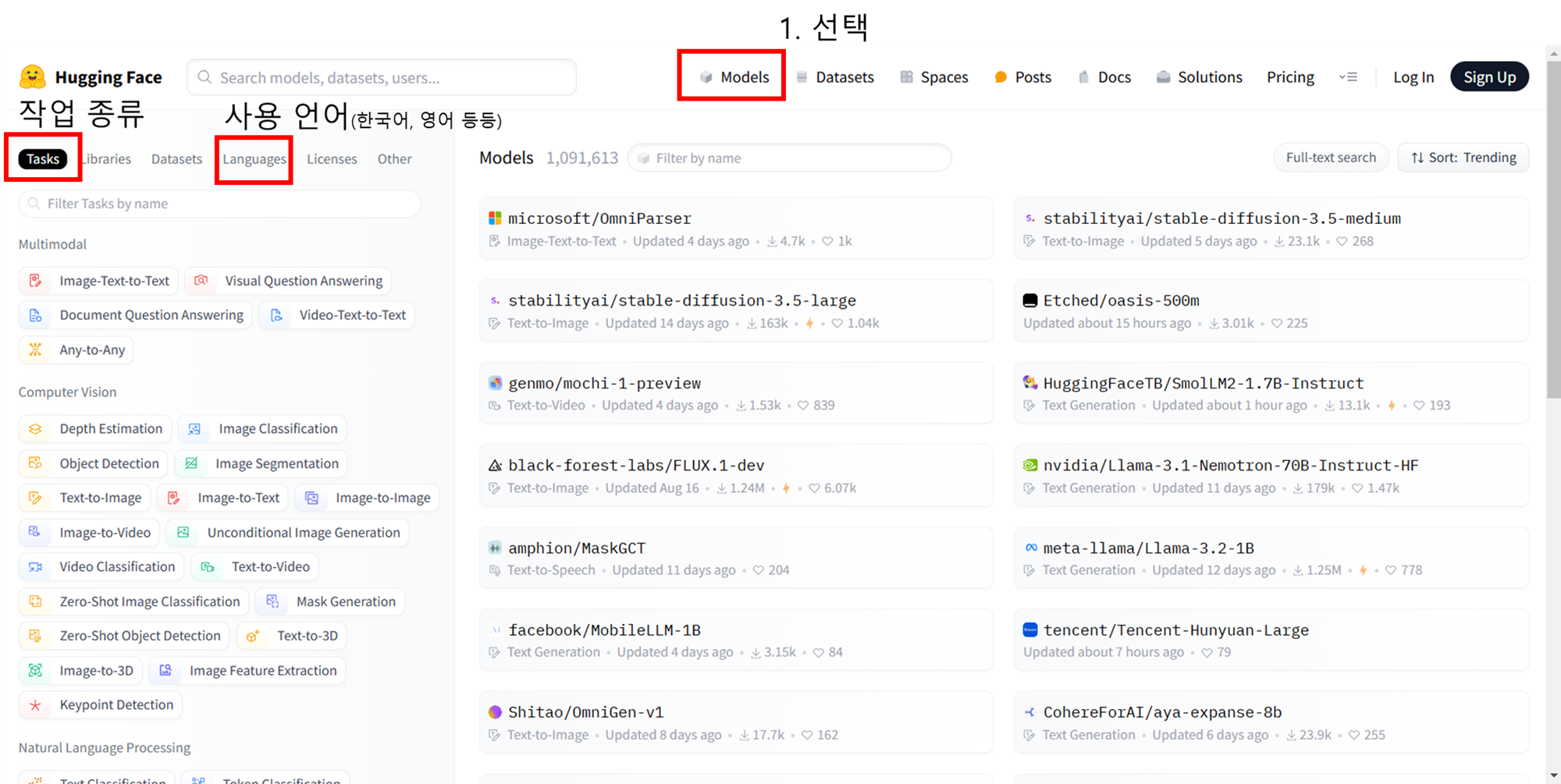
- 모델 선택 시
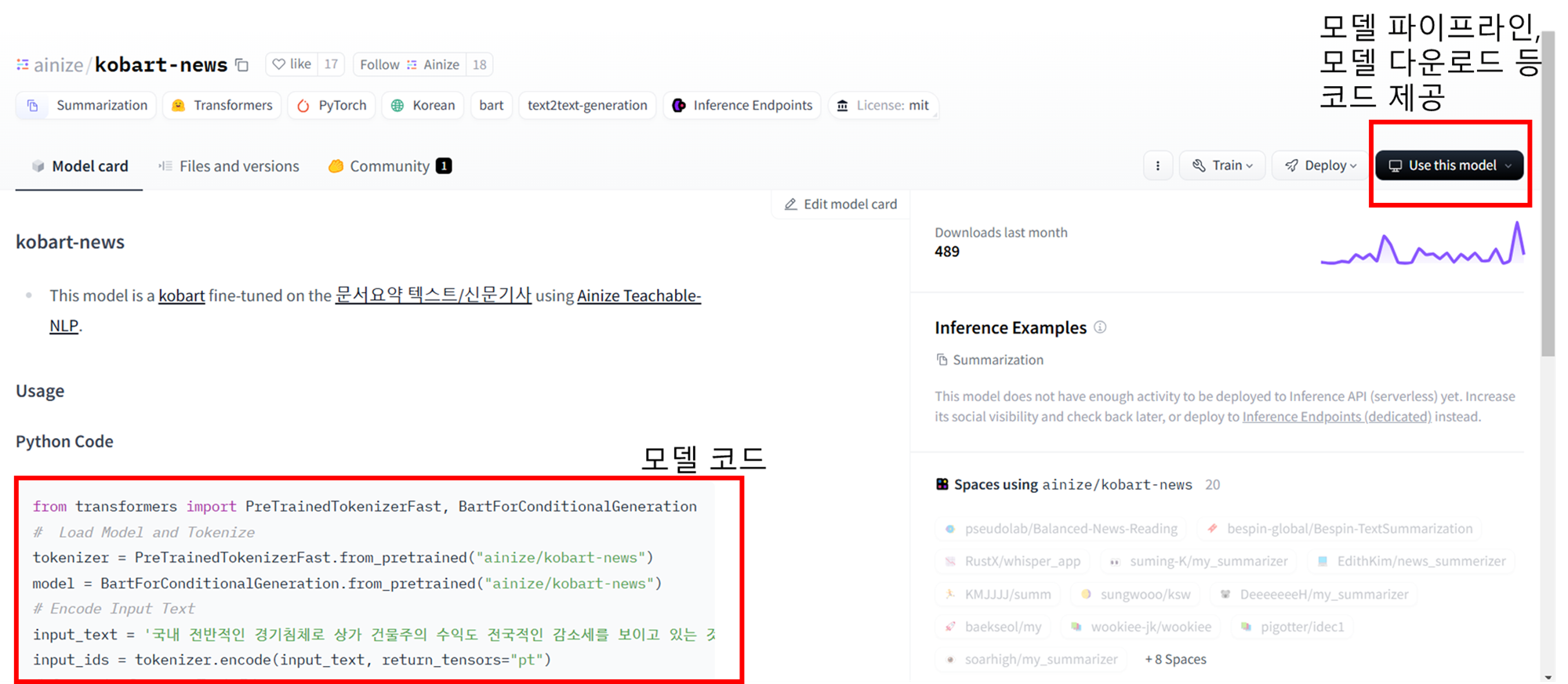
- 모든 모델이 예제 코드를 제공하지 않음
4-2. 코드
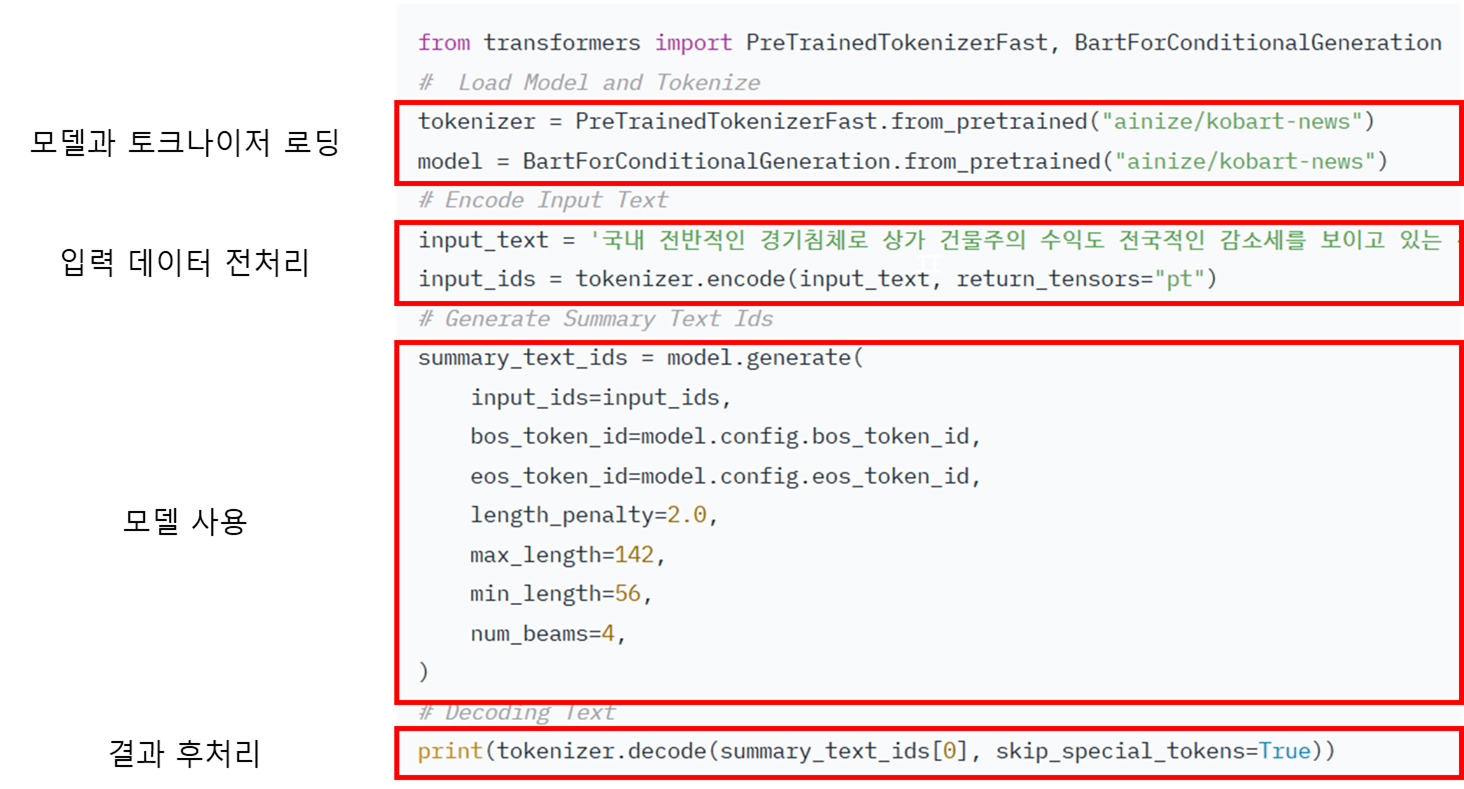
# 한국어 요약 모델
from transformers import PreTrainedTokenizerFast, BartForConditionalGeneration
# Load Model and Tokenize
# 모델과 tokenizer를 다운로드
tokenizer = PreTrainedTokenizerFast.from_pretrained("ainize/kobart-news")
model = BartForConditionalGeneration.from_pretrained("ainize/kobart-news")
# Encode Input Text
input_text = '''
국내 전반적인 경기침체로 상가 건물주의 수익도 전국적인 감소세를 보이고 있는 것으로 나타났다.
수익형 부동산 연구개발기업 상가정보연구소는 한국감정원 통계를 분석한 결과 전국 중대형 상가
순영업소득(부동산에서 발생하는 임대수입, 기타수입에서 제반 경비를 공제한 순소득)이 1분기 ㎡당
3만4200원에서 3분기 2만5800원으로 감소했다고 17일 밝혔다.
수도권, 세종시, 지방광역시에서 순영업소득이 가장 많이 감소한 지역은 3분기 1만3100원을 기록한 울산으로, 1분기 1만9100원 대비 31.4% 감소했다.
이어 대구(-27.7%), 서울(-26.9%), 광주(-24.9%), 부산(-23.5%), 세종(-23.4%), 대전(-21%), 경기(-19.2%), 인천(-18.5%) 순으로 감소했다.
지방 도시의 경우도 비슷했다.
경남의 3분기 순영업소득은 1만2800원으로 1분기 1만7400원 대비 26.4% 감소했으며
제주(-25.1%), 경북(-24.1%), 충남(-20.9%), 강원(-20.9%), 전남(-20.1%), 전북(-17%), 충북(-15.3%) 등도 감소세를 보였다.
조현택 상가정보연구소 연구원은 "올해 내수 경기의 침체된 분위기가 유지되며
상가, 오피스 등을 비롯한 수익형 부동산 시장의 분위기도 경직된 모습을 보였고
오피스텔, 지식산업센터 등의 수익형 부동산 공급도 증가해 공실의 위험도 늘었다"며
"실제 올 3분기 전국 중대형 상가 공실률은 11.5%를 기록하며 1분기 11.3% 대비 0.2% 포인트 증가했다"고 말했다.
그는 "최근 소셜커머스(SNS를 통한 전자상거래), 음식 배달 중개 애플리케이션, 중고 물품 거래 애플리케이션 등의
사용 증가로 오프라인 매장에 영향을 미쳤다"며 "향후 지역, 콘텐츠에 따른 상권 양극화 현상은 심화될 것으로 보인다"고 덧붙였다.
'''
# 전처리
input_ids = tokenizer.encode(input_text, return_tensors="pt") # tokenizer를 이용한 인코딩
# Generate Summary Text Ids : 모델 사용
summary_text_ids = model.generate(
input_ids=input_ids, # 입력 값(토큰화된 내용)
bos_token_id=model.config.bos_token_id, # 문장 시작 토큰 ID
eos_token_id=model.config.eos_token_id, # 문장 끝 토큰 ID
length_penalty=2.0, # 생성된 요약의 길이에 대한 패널티. 길이가 길어질수록 패널티가 증가하여 적절한 길이의 요약을 유도.
max_length=142, # 생성할 요약의 최대 길이. 이 길이를 초과하는 요약은 생성되지 않음.
min_length=56, # 생성할 요약의 최소 길이. 이 길이보다 짧은 요약은 생성되지 않음.
num_beams=4, # 빔 검색의 수. 여러 개의 후보 요약을 고려하여 최적의 요약을 선택하는 데 사용. 숫자가 클수록 더 다양한 후보를 고려하지만, 계산 비용이 증가함.
)
)
# Decoding Text : 후처리
print(tokenizer.decode(summary_text_ids[0], skip_special_tokens=True))5. 언어 모델 이해
5-1. 언어 모델링 절차
- 데이터 전처리
- Tokenize
- 문장을 의미 있는 단위로 쪼갬
- 사람이 결정해야하는 부분
- 문자 단위, 단어 단위, 형태소 단위(한국어는 형태소 단위가 일반적)
- 해당 단위에 번호를 붙임(vocab)
- 문장을 의미 있는 단위로 쪼갬
- 모델 사용
- Embedding Vector
- 토큰을 머신이 파악할 수 있는 수치로 변환
- 문서, 문장 내에서 단어의 의미와 문맥을 담음
- Transformer
- 문맥 파악
- 동음이의어는 여기서 문맥 파악으로 판단
- 결과 후처리

데이터 분석가&엔지니어를 희망하는 취준생