1. 개발 환경 준비
1-1. 라이브러리 설치
- 구글 드라이브에 새 폴더 생성
- 새 폴더 이름 : langchain
- Colab에서 구글 드라이브 연결
- Colab 코드에서 실행하여 연결
from google.colab import drive
drive.mount('/content/drive')- requirements.txt 파일 연결
- 라이브러리 설치
!pip install -r /content/drive/MyDrive/langchain/requirements.txt- requirements.txt
- openai==0.28
- langchain==0.1.20
- pymupdf
- spacy
- tiktoken
- chromadb==0.5.0
- wikipedia
1-2. 라이브러리 연결 및 API 설정
import pandas as pd
import numpy as np
import os
import openai
from langchain.document_loaders import PyMuPDFLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA #← RetrievalQA를 가져오기
from langchain.chat_models import ChatOpenAI
from langchain.retrievers import WikipediaRetriever
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
def load_api_key(filepath):
with open(filepath, 'r') as file:
return file.readline().strip()
path = '/content/drive/MyDrive/langchain/'
# API 키 로드 및 환경변수 설정
openai.api_key = load_api_key(path + 'api_key.txt') # 'api_key.txt'내에 api key 정보가 있어야 함
os.environ['OPENAI_API_KEY'] = openai.api_key2. LangChain
- 다양한 LLM 모델을 묶어 다양한 기능 제공
# LangChain으로 LLM 모델 연결
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(model = "gpt-3.5-turbo") # api 키가 필요하나, 위에서 환경 변수로 설정2-1. 특징
- 체인(Chain)
- 여러 언어 모델과 함수를 체인 형태로 연결하여 복잡한 작업을 단계별 처리 가능
- 질문 응답 시스템 구축 시, 먼저 질문 요약 후 질문에 대한 답 제공 가능
- 메모리(Memory)
- 대화형 응용 프로그램 작성 시 사용자와 이전 대화를 기록하여 자연스러운 상호작용 가능
- 에이전트(Agent)
- 특정 작업을 수행하기 위해 모델이 외부 도구나 API와 상호작용할 수 있도록 도움
- 다양한 데이터 소스 통합
- 데이터베이스, 검색 엔진, 웹 API를 통합하여 다양한 데이터 소스에서 정보 수집, 활용 가능
2-2. 모델 사용
- Langchain에서 사용하는 세 가지 유형의 Message
- SystemMessage : 시스템 역할 부여
- HumanMessage : 질문
- AIMessage : 답변
- 메세지를 구분하는 이유
- 대화 구조화
- 역할 분리
- 대화 관리
chat = ChatOpenAI(model = "gpt-3.5-turbo")
sys_role = '당신은 한국인 입니다'
question = '독도는 어느 나라 땅이야?'
result = chat([HumanMessage(content = question), # HumanMessage
SystemMessage(content = sys_role)]) # SystemMessage
print(result.content) # AIMessage2-2-1. 모델 사용 - 입력 구조화
- PromptTemplate
- 파이썬 입력과 프롬프트를 결합하도록 지원하는 모듈
from langchain import PromptTemplate
prompt = PromptTemplate(template = "{nation}의 인구수는?", input_variables = ["nation"])
print(prompt.format(nation = "한국")) # 한국의 인구수는?
result = chat([HumanMessage(content=prompt.format(nation = "한국"))])
print(result.content)
# 2021년 9월 기준으로 한국의 인구는 약 5천 100만명입니다.2-2-2. 모델 사용- 출력 구조화
- OutputParser
- 출력 형태를 지정하는 방법
- CommaSeparatedListOutputParser
- 콤마로 구분된 리스트 형태
# 출력파서 선언
output_parser = CommaSeparatedListOutputParser()
# 사용
result = chat([HumanMessage(content = "제주도 대표 관광지 5개 알려줘"),
HumanMessage(content = output_parser.get_format_instructions())])
# 결과 출력
print(result.content) # 한라산, 성산일출봉, 용두암, 성읍민속마을, 제주도 도립미술관
# 결과 출력2
output = output_parser.parse(result.content)
print(output) # ['한라산', '성산일출봉', '용두암', '성읍민속마을', '제주도 도립미술관']- 스트리밍 방식 출력
- 모델의 출력을 완성될 때 출력하는 것이 아닌, 생성되는 즉시 실시간으로 출력을 받아옴
# 스트리밍 방식으로 출력
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
chat2 = ChatOpenAI(model="gpt-3.5-turbo",
streaming=True, callbacks=[StreamingStdOutCallbackHandler()]) # 스트리밍 설정
# streaming = True : 모델의 응답을 스트리밍 방식으로 받아옴
# callbacks=[StreamingStdOutCallbackHandler()] : 스트리밍 중 생성된 응답을 실시간으로 콘솔 출력으로 내보냄
sys_role = '당신은 한국인입니다.'
question = "독도가 왜 한국 땅인지 근거를 설명해줘"
result = chat2([HumanMessage(content=question), SystemMessage(content = sys_role)])3. RAG
- Retrieval Augmented Generation
- 사전 학습된 LLM이 존재할 경우
- 나의 데이터를 이용하여 추가 학습 : Fine-tuning
- 나의 데이터를 이용하여 답변 : RAG
3-1. LLM 모델과 RAG
- LLM의 문제점
- 컴퓨터 자원 문제
- 정보 수집 빛 처리 문제
- 잘못된 정보
- 훈련 시간
- 편향된 데이터
- 환경 문제 야기
-> 이 중 일부는 RAG로 어느정도 해결 가능
- LLM 모델은 학습하지 않은 내용은 모름
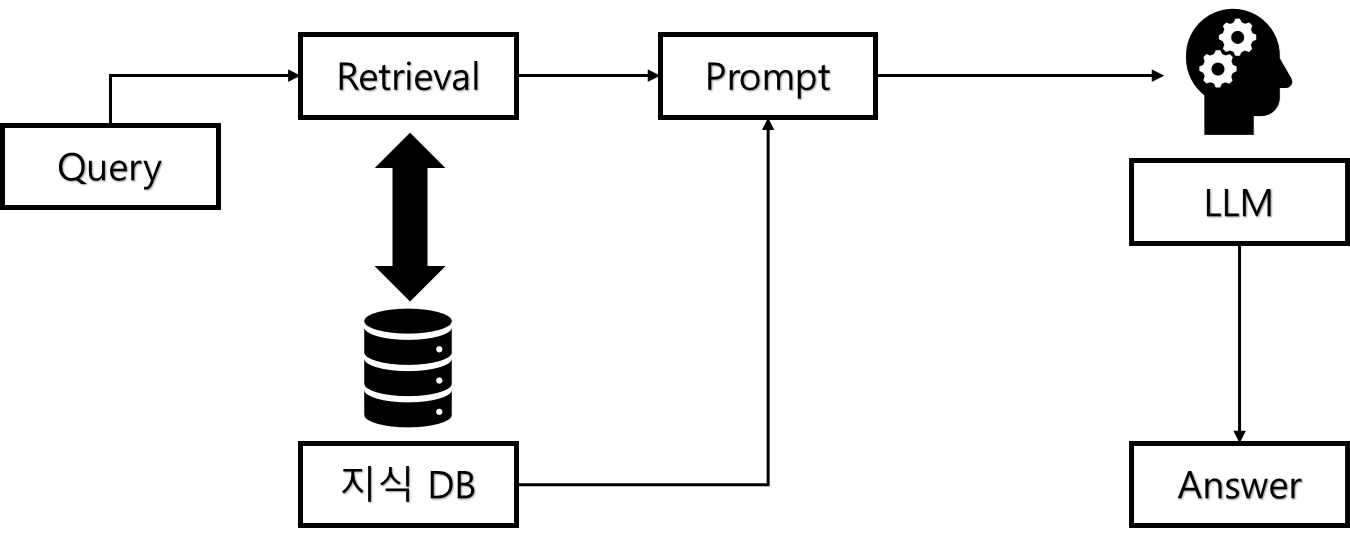
- LLM 모델을 RAG와 함께 사용 시
- 사용자 질문을 받고, 지식 DB에서 답변에 필요한 문서 검색
- 필요한 문서를 포함한 프롬프트 생성
- 답변
3-2. Vector DB
- 문장, 이미지 등 비정형 데이터를 벡터 형태로 변환 후,.저장, 빠른 검색 기능 제공
- LLM with RAG 절차 중 지식 DB에서 답변에 도움이 되는 문서를 찾을 때, 질문 벡터와 DB 내 저장된 문서 벡터와의 유사도 계산 -> 가장 유사도가 높은 문서를 찾음
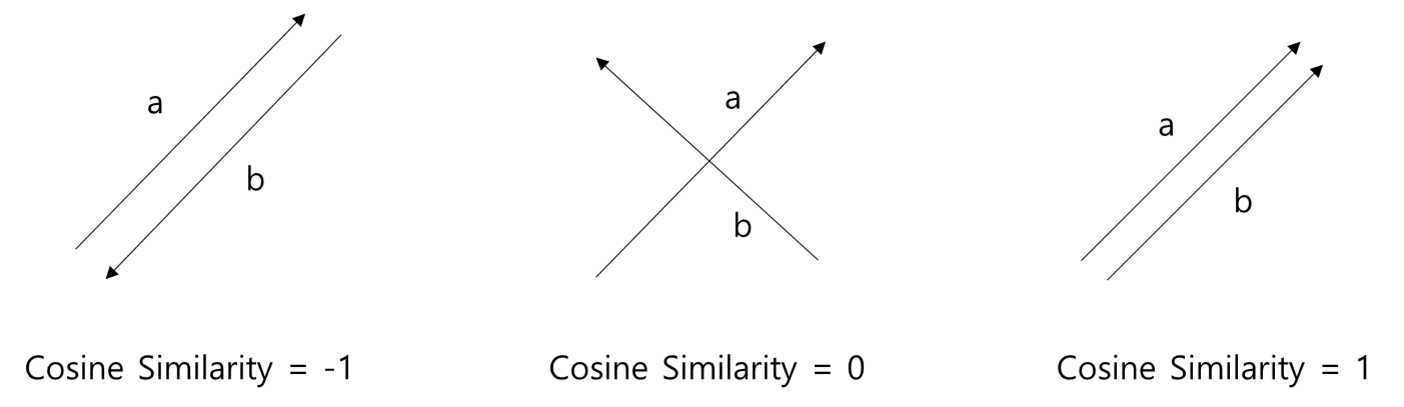
- 유사도(Similarity Score)
- Cosine Distance 이용
- Cosine Distance(a, b) = 1 - Cosine Similarity(a, b)
- 0에 가까울수록 유사도가 높음
- Cosine Similarity(a, b)
- Vector DB로 Chroma DB 사용
- SQLit3 기반 Vector DB
- LLM과의 통합을 염두에 두고 설계된 벡터 데이터베이스
- 텍스트 데이터를 효율적으로 인코딩하고 검색하는데 최적화
3-2-1. Vector DB 구축 절차
- 텍스트 추출(Document Loader)
- 다양한 문서로 부터 텍스트 추출
- 텍스트 분할(Text Splitter)
- chunk 단위로 분할
- Document 개체로 만들기
- 텍스트 벡터화(Text Embedding)
- Vector DB로 저장(Vector Store)
3-2-2. DB 생성 코드
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002") # GPT 3.5가 쓰는 임베딩 모델
database = Chroma(persist_directory = path + "db", # 경로 지정(구글 드라이브에서 db 폴더 생성)
embedding_function = embeddings) # 임베딩 벡터로 만들 모델 지정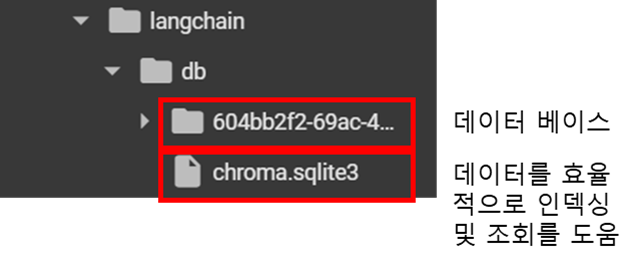
3-3-3. 데이터 Insert
- 단순 텍스트 입력
- 각 단위 텍스트를 리스트 형태로 입력
- .add_texts()
input_list = ['test 데이터 입력1', 'test 데이터 입력2']
# 입력시 인덱스 저장(조회시 사용)
ind = database.add_texts(input_list)
database.get(ind)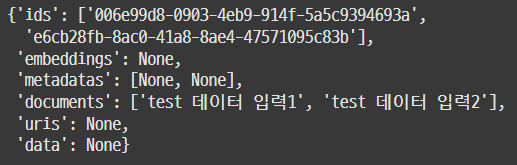
- 텍스트와 메타데이터 입력
- 각 단위 텍스트와 메타 정보를 함께 입력
- .add_documents()
input_list2 = ['오늘 날씨는 매우 맑음. 낮 기온은 30도 입니다.', '어제 주가는 큰 폭으로 상승했습니다.']
metadata = [{'category':'test'}, {'category':'test'}]
doc2 = [Document(page_content = input_list2[i], metadata = metadata[i]) for i in range(2)]
ind2 = database.add_documents(doc2)
database.get(ind2)
3-3-3-1. 조회 방법
# 전체 조회
database.get()
# 인덱스 조회
database.get(index)
# 조건 조회(ChromaDB에서 제공하지 않으나 Dataframe으로 변환 후 사용 가능)
data = database.get() # 전체 데이터를 불러와서
data = pd.DataFrame(data) # 데이터 프레임 화
data.loc[data['metadatas'] == {'category': 'test'}]# 유사도가 높은 문서 가져오기
query = '오늘 낮 기온은?'
k = 2 # 유사도 상위 k개 문서
# 데이터베이스에서 유사도가 높은 문서 가져오기
result = database.similarity_search_with_score(query, k = k)
print(result)
'''
[(Document(page_content='오늘 날씨는 매우 맑음. 낮 기온은 30도 입니다.', metadata={'category': 'test'}), 0.22618641133398137),
(Document(page_content='어제 주가는 큰 폭으로 상승했습니다.', metadata={'category': 'test'}), 0.38118057585848064)
'''
for doc in result :
print(f'유사도 점수 : {round(doc[1], 5)}, 문서 내용 : {doc[0].page_content}')
3-3. RAG 구성 함수
- RAG용 QA chat 함수
- llm : 언어 모델
- retriever : Rag로 연결할 VectorDB
- return_source_documents = True : 모델이 답변을 생성하는 것 뿐만 아니라 그 답변에 사용된 출처 문서 함께 반환
- 문서의 내용을 반환하는 것이 아닌 문서의 내용을 기반으로 새로운 답변 생성
from langchain.embeddings import OpenAIEmbeddings
chat = ChatOpenAI(model="gpt-3.5-turbo")
retriever = database.as_retriever() # database를 지식 db로 사용할 것이다
qa = RetrievalQA.from_llm(llm=chat, retriever=retriever, return_source_documents=True )
query = "생성형 AI 도입시 예상되는 보안 위협은 어떤 것들이 있어?"
result = qa(query)
print(result["result"]) # 지식 db의 내용을 기반으로 새로운 내용을 생성
'''
생성형 AI 프로젝트를 도입할 때 예상되는 보안 위협은 다양합니다.
이러한 위협에는 악의적인 공격자가 프로젝트 팀에 침투하여 소프트웨어에 악성 코드를 추가하거나 훈련 데이터,
미세 조정 또는 가중치를 오염시키는 것, 모델을 재학습시켜 사용자 인프라에 침입하는 것,
가짜 뉴스나 잘못된 정보로 모델을 훈련시키는 것 등이 있습니다.
또한, 오픈소스 AI 모델을 무단으로 다운로드하여 해킹을 시도하거나,
모델의 출력물에 워터마크를 추가해도 공격을 막지 못하는 등의 위협도 있을 수 있습니다.
함부로 생성형 AI를 도입할 때는 이러한 보안 측면을 신중히 고려해야 합니다.
'''- 이전 질문과 대답을 기억하지 못함
3-4. Memory
- 이전의 대화를 기억하여 현재 대화를 진행
- 이전 질문 답변을 Memory에 저장 후 Prompt에 포함
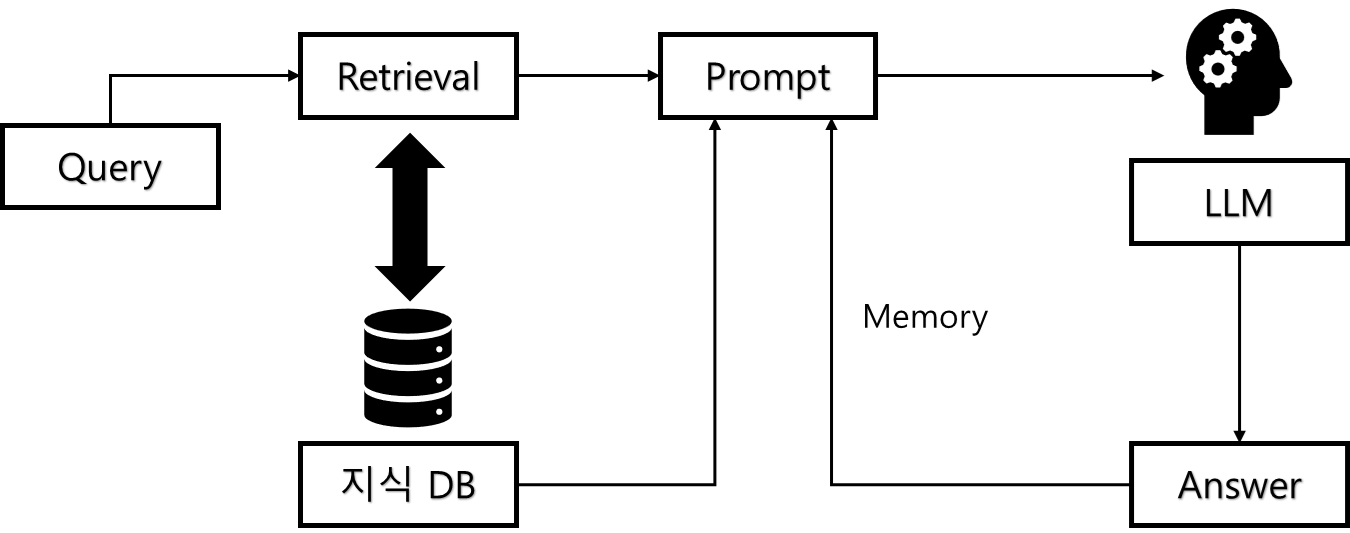
3-4-1. Memory 코드
- ConversationBufferMemory 함수
- 대화를 저장하는 메모리
- .save_context()
- 딕셔너리 형태로 저장
- input : HumanMessage
- output : AIMessage
- .load_memory_variables({})
- 현재 메모리 내용 전체 조회
from langchain.memory import ConversationBufferMemory
# 메모리 선언하기(초기화)
memory = ConversationBufferMemory(return_messages=True)
# 저장
memory.save_context({"input": "안녕하세요!"},
{"output": "안녕하세요! 어떻게 도와드릴까요?"})
memory.save_context({"input": "메일을 써야하는데 도와줘"},
{"output": "누구에게 보내는 어떤 메일인가요?"})
# 현재 담겨 있는 메모리 내용 전체 확인
memory.load_memory_variables({})
# 위에 만든 챗봇에 연결
query = "생성형 AI 도입시 예상되는 보안 위협은 어떤 것들이 있어?"
result = qa(query)
memory = ConversationBufferMemory(return_messages=True)
memory.save_context({"input": query},
{"output": result['result']})
memory.load_memory_variables({})- 하지만 해당 방법으로는 답변이 이전 대화와 연결되지 않음
-> 맥락을 유지하기 위해 메세지의 내용을 프롬프트에 연결 필요
-> 이를 손쉽게 엮는 방법이 Chain
3.5 Chain
- LLM 모델, retriever, memory 모델을 모두 연결
- ConversationalRatrievalChain 함수
qa = ConversationalRetrievalChain.from_llm(llm=chat, retriever=retriever, memory=memory,
return_source_documents=True, output_key="answer")
# ouput_key : 모델의 출력이 저장될 키
memory = ConversationBufferMemory(memory_key="chat_history", # 메모리에서 대화 기록 저장을 위한 키(해당 키를 통해 대화 내역을 저장하고 불러올 수 있음)
input_key="question", # 사용자 질문키(이 키를 통해 사용자의 질문이 메모리에 저장)
output_key="answer", # 모델의 출력키(이 키를 통해 모델의 답변이 메모리에 저장)
return_messages=True) # 메모리에 저장된 대화 내역이 메시지 형식으로 반환4. 전체 챗봇 코드
# 코랩 기준
# 구글 드라이브 연결
from google.colab import drive
drive.mount('/content/drive')
# 필요 라이브러리 설치
!pip install -r /content/drive/MyDrive/langchain/requirements.txt
# 라이브러리 Import
import pandas as pd
import numpy as np
import os
import sqlite3
from datetime import datetime
import openai
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage, Document
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
# OpenAI API Key 등록
def load_api_key(filepath):
with open(filepath, 'r') as file:
return file.readline().strip()
path = '/content/drive/MyDrive/langchain/'
# API 키 로드 및 환경변수 설정
openai.api_key = load_api_key(path + 'api_key.txt')
os.environ['OPENAI_API_KEY'] = openai.api_key
# Vector DB 생성
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
database = Chroma(persist_directory="./db", embedding_function = embeddings )
## DB 초기화
# ids = database.get()
# if ids['ids']:
# database.delete(ids = ids['ids'])
data = pd.read_csv(path + 'aivleschool_qa.csv', encoding='utf-8') # 데이터가 들어있는 파일 연결
qa_list = data['QA'].tolist()
cat_list = [{'category':text} for text in data['구분'].tolist()]
# 각 행의 데이터를 Document 객체로 변환
documents = [Document(page_content=qa_list[i], metadata = cat_list[i]) for i in range(len(qa_list))]
# 데이터프레임에서 문서 추가
database.add_documents(documents)
# RAG + LLM 모델
chat = ChatOpenAI(model="gpt-3.5-turbo")
k=3
retriever = database.as_retriever(search_kwargs={"k": k})
# 대화 메모리 생성
memory = ConversationBufferMemory(memory_key="chat_history", input_key="question",
output_key="answer", return_messages=True)
# ConversationalRetrievalQA 체인 생성
qa = ConversationalRetrievalChain.from_llm(llm=chat, retriever=retriever, memory=memory,
return_source_documents=True, output_key="answer")
# 질문이 들어올 경우 자동으로 question 키로 메모리에 저장(memory에 명시적으로 지정해놨기에 qa 모델에선 지정 안해도 됨)
# output_key 같은 경우 답변 외에 다른 정보가 포함 될 수 있기에 명확하게 어느 키에 저장 되는지 표시해야 함# 질문
query = "지원하는데 나이 제한이 있나요?" # 질문할 문장
# 답변
result = qa(query)
answer = result["answer"]
print(answer)
데이터 분석가&엔지니어를 희망하는 취준생