1. Object Detection
- Classification + Localization
- Classification : 이미지 내 객체가 무엇인지 식별
- Localization : 해당 객체가 이미지 내에 어디에 위치해 있는 지 확인
- Multi-Labeled Classification + Bounding Box Regression
- Multi-Labeled Classification : 하나의 이미지 내에 존재하는 다수의 객체를 여러 개의 라벨로 예측
- Bounding Box Regression : 객체의 위치를 정확하게 찾기 위해 경계 상자(bounding box)의 좌표를 회귀로 예측

2. Object Detection 주요 개념
2-1. Class Classification
- 객체를 구분하는 것
2-2. Bounding Box
- 하나의 Object가 포함된 박스
- x_min, y_min, x_max, y_max, x_center, y_center, width, height,,, 등 위치 정보를 가짐
- '모델이 객체가 있는 위치를 잘 예측하는 가' 판단
2-3. IoU
- Intersection over Union
- 두 박스의 중복 영역 크기를 통해 측정
- 겹치는 영역이 넓을 수록 좋은 예측
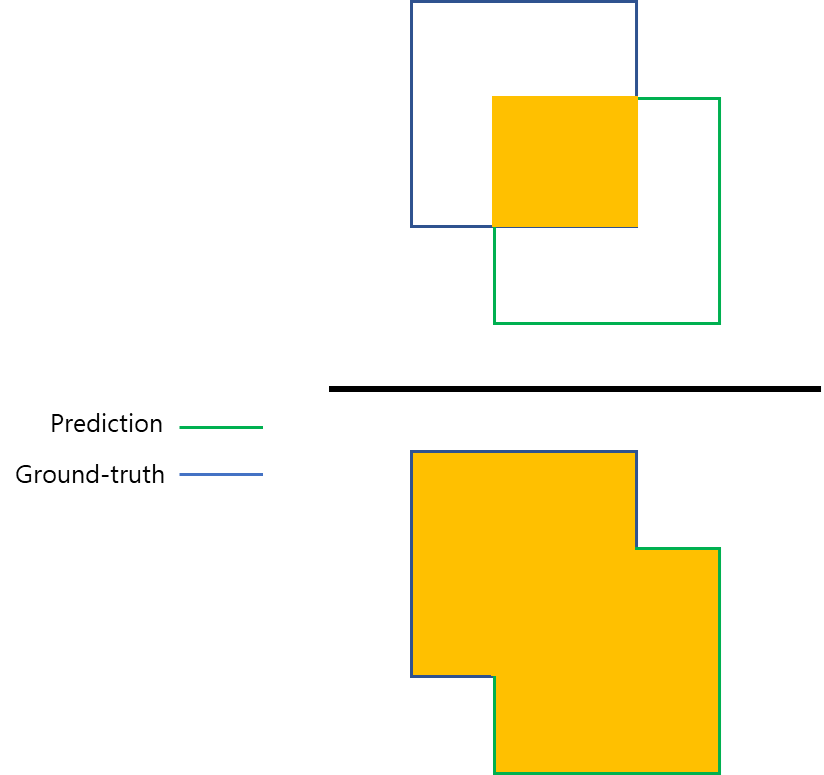
- 0 ~ 1 사이의 값 -> 값이 클수록 좋은 예측
2-4. Confidence Score
- Bounding Box 내에 객체가 존재하는지에 대한 모델의 확신도
- 0 ~ 1 사이의 값 -> 값이 클수록 모델은 Bounding Box 내에 객체가 있다고 판단
- 모델에따라 계산하는 방법은 조금씩 다름
2-5. Precision, Recall, AP, mAP
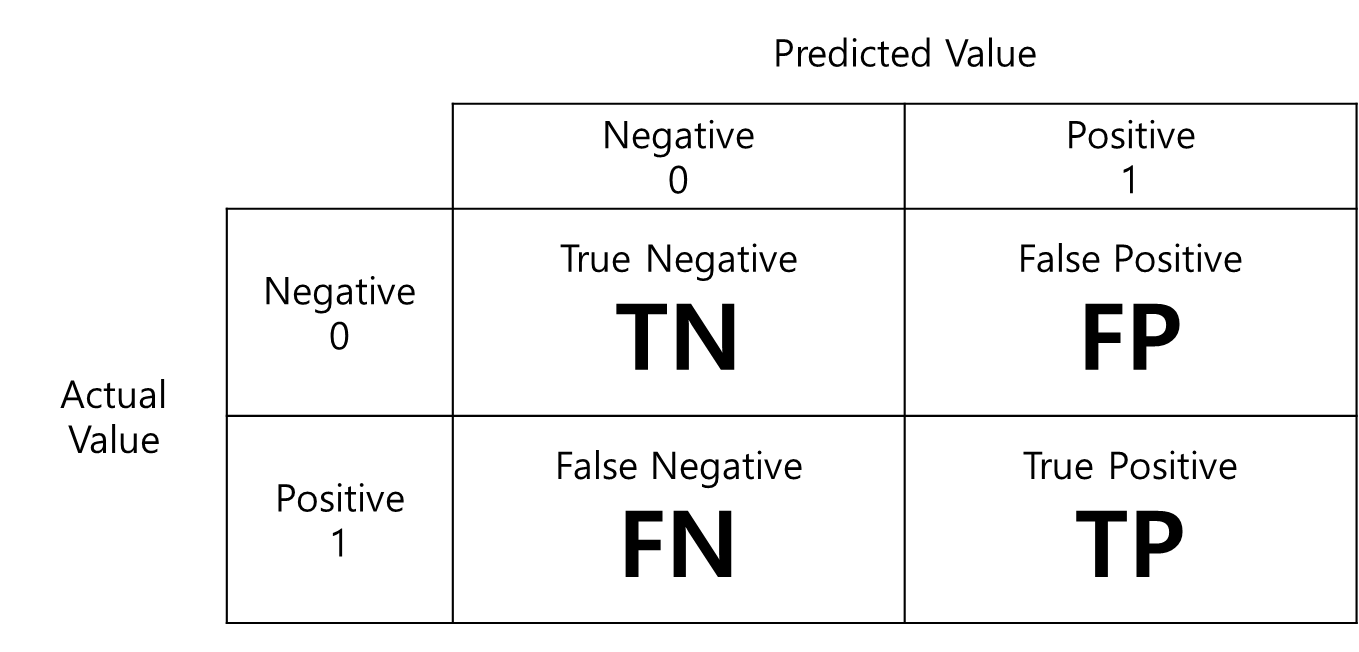
2-5-1. Precision
- 모델이 Object라 예측한 것 중 실제 Object의 비율
2-5-2. Recall
- 실제 Object 중 모델이 예측하여 맞춘 Object의 비율
2-5-3. Confusion score Threshold 값에 따라 Precision, Recall의 변화
- Confusion score Threshold 값 증가
- TP라 판단하는 기준이 높아짐
- Precision 증가, Recall 감소
- Confusion score Threshold 값 감소
- TP라 판단하는 기준이 낮아짐
- Recall 증가, Precision 감소
2-5-4. AP와 mAP
- Precision - Recall Curve
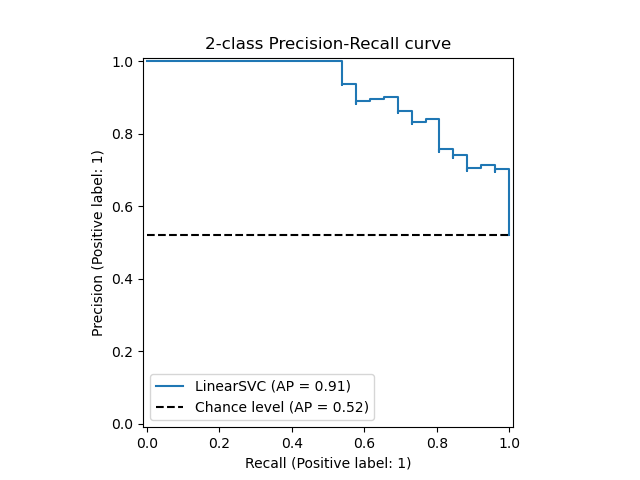
- Confidence score threshold에 따른 Precision과 Recall를 모두 감안한 지표
- AP(Average Precision)는 해당 그래프 아래의 면적
- mAP(mean Average Precision)는 각 클래스 별 AP를 합산하여 평균을 낸 것
2-5-5. AP와 mAP 구하는 과정
- AP
- 특정 클래스 선택
- IoU 임계값 설정 : 0.50에서 일반적 시작
- Confidence score 임계값이 다양하게 변화하면서 P-R curve를 그림
- IoU 임계값 설정에 따른 P-R curve 아래의 면적 계산
- IoU 임계값을 0.05 높이고, 3~4번 과정 반복(0.95까지)
- 5번까지의 과정을 통해 구한 면적들의 평균 계산
- mAP
- 모든 클래스에 AP 계산 과정을 적용하여 클래스별 AP 산출
- 1번 과정을 통해 만들어진 AP들의 평균 계산
2-6. NMS
- Non-Maximum Suppression
- 추론 과정의 알고리즘
- 동일 Object에 대한 중복 박스 제거

- NMS 과정
- Confidence score 임계값 이하의 Bounding Box 제거
- 남은 Bounding Box들을 Confidence score 내림차순으로 정렬
- 첫 Bounding Box(Confidence score가 가장 높은 Bounding Box)와의 IoU 값이 임계값 이상인 다른 박스 제거
- Bounding Box가 하나가 될 때까지 반복
- IoU가 임계값 이상인 경우 두 Bounding Box가 동일한 Object를 나타내는 것이라 판단하여, Confidence score가 낮은 Bounding Box 제거
- Confidence score threshold가 높을 수록, IoU threshold가낮을 수록 중복 박스에 대한 판단이 엄밀해짐
- Confidence score threshold와 IoU threshold는 사용자가 조절하는 HyperParameter
2-7. Annotation
- 이미지 내 정보에 대해 별도의 파일이 제공되는 것
- Annotation 파일 내에는 Object의 위치 정보, 클래스 정보, 클래스명 등의 정보 존재
- YOLO의 경우 .txt 파일로 존재(class명, x, y, w, h 정보가 들어있음)
3. UltraLytics : YOLO
- YOLO(You only look once)
- 이미지를 한번만 보고 바로 물체를 검출하는 딥러닝 기술
- 한번만 보고 판단하기에 실시간 물체 검출이 가능해짐
- UltraLytics : YOLO
- YOLO 모델의 PyTorch 구현을 제공하는 라이브러리
- 쉽고 직관적인 API 제공
- 이미 사전 훈련된 모델 제공
3-1. 코드
# 라이브러리 설치
!pip install ultralytics
import os
os.environ['WANDB_MODE'] = 'disabled' # 새로 생긴 설정인데, abled로 설정 할 경우 오류를 일으키는 경우가 많아 disabled 설정
# yolo 설정
from ultralytics import settings
settings['datasets_dir'] = '/content/' # datasets_dir의 경로 변경
# 원래 /content/datasets 이나, 해당 폴더를 안 만든 상태이기에 경로 변경
settings
# YOLO 모델 선언
from ultralytics import YOLO
model = YOLO(model='yolo11n.pt', task='detect') # 둘 다 default 값
# 실행 시 yolo11n.pt 파일 생성
# 해당 파일엔 이미 학습된 가중치 정보가 들어있음
# 11 : 버전, n : 크기(경량화 된 nano 모델)
model.train(model = '/content/yolo11n.pt', # 넣는 이유 -> 나중에 잘 커스텀 학습된 모델을 쓸 때 명시해야하기에
data='coco8.yaml', # Object Detection 모델을 학습할 때 사용한 데이터 셋(이미 해당 데이터로 훈련되어 있음)
epochs=20, # 기본값 100
patience=5, # 기본값 100
# batch = 16 # 기본값 16, -1 일 경우 자동 설정
# save=True, # 학습 과정을 저장할 것인지 설정, 기본값 True
# project='trained', # 학습 과정이 저장되는 폴더 명
# name='trained_model', # project 내부에 생성되는 폴더 이름
# exist_ok=False, # 동일한 이름의 폴더가 있을 때 덮어씌울 것인지 설정, 기본값 False
pretrained=True, # 사전에 학습된 모델을 사용할 것인지 설정, 기본값 True (False 할 경우 학습 시간이 오래걸림)
# optimizer='auto', # 기본값 'auto'
# verbose=False, # 기본값 False
# seed=2024,
# resume=False, # 마지막 학습부터 다시 학습할 것인지 설정, 기본값 False
# freeze=None # 첫 레이어부터 몇 레이어까지 기존 가중치를 유지할 것인지 설정. default None
)
- 실행 시 모델 설명 출력

- 최고 성능 모델과 마지막 모델 성능 저장 위치 표시
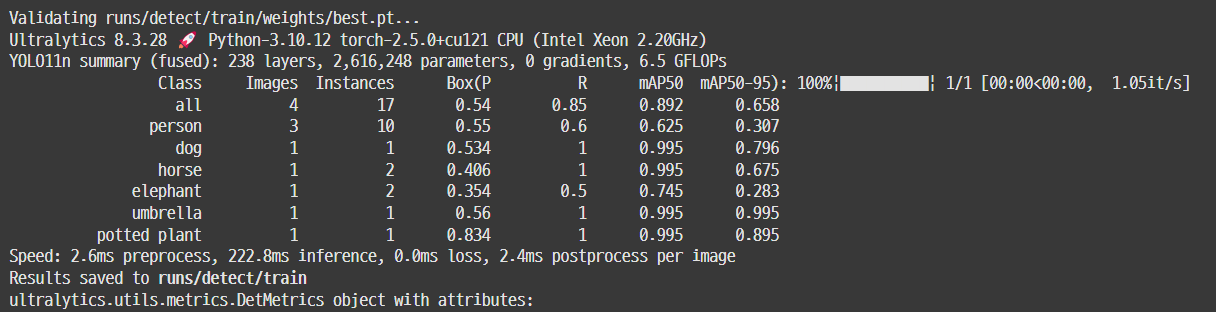
- best 모델일 때 검증 데이터 결과값
- YOLO는 훈련 중 검증도 자동 수행
# 예측
# conf와 iou를 직접 설정하여 예측 결과 값을 수정 가능
# source : 예측 대상 이미지/동영상의 경로
# conf : default 0.25
# iou : NMS에 적용되는 IoU threshold. default 0.7.
# save : 예측된 이미지/동영상을 저장할 것인지 설정. default False
# save_txt : Annotation 정보도 함께 저장할 것인지 설정. default False
# save_conf : Annotation 정보 맨 끝에 Confidence Score도 추가할 것인지 설정. default False
# line_width : 그려지는 박스의 두께 설정. default None
results = model.predict(source='https://images.pexels.com/photos/139303/pexels-photo-139303.jpeg',
# conf=0.5,
# iou=0.5,
save=True, save_txt=True, line_width=2)
-
파일이 저장된 위치를 알려줌
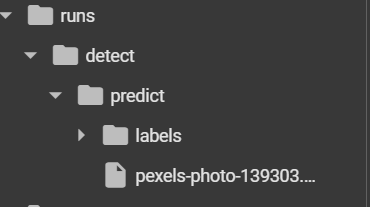
-
결과물

4. Roboflow를 이용한 YOLO 학습
4-1. Roboflow
- 컴퓨터 비전과 관련된 다양한 자료 제공
- 해당 사이트에 들어가 학습에 필요한 다양한 데이터 셋을 제공 받을 수 있음
4-2. 데이터셋 다운로드
- 사이트 접속 후 왼쪽 하단에 Univers 선택
- 원하는 프로젝트 검색 후 선택
- Download Project 선택
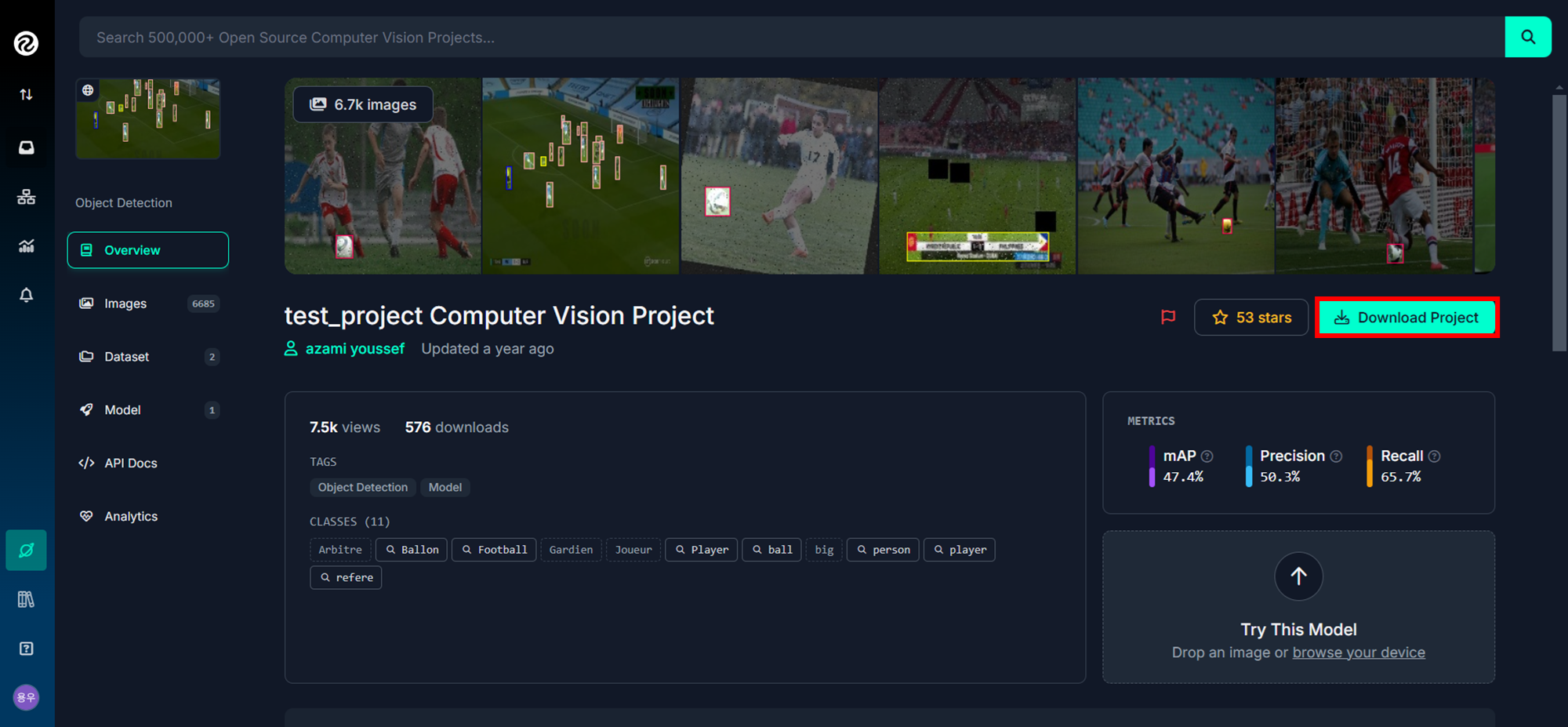
- 사용할 데이터 버전과 데이터 포멧 선택(본인은 YOLOv11 사용)
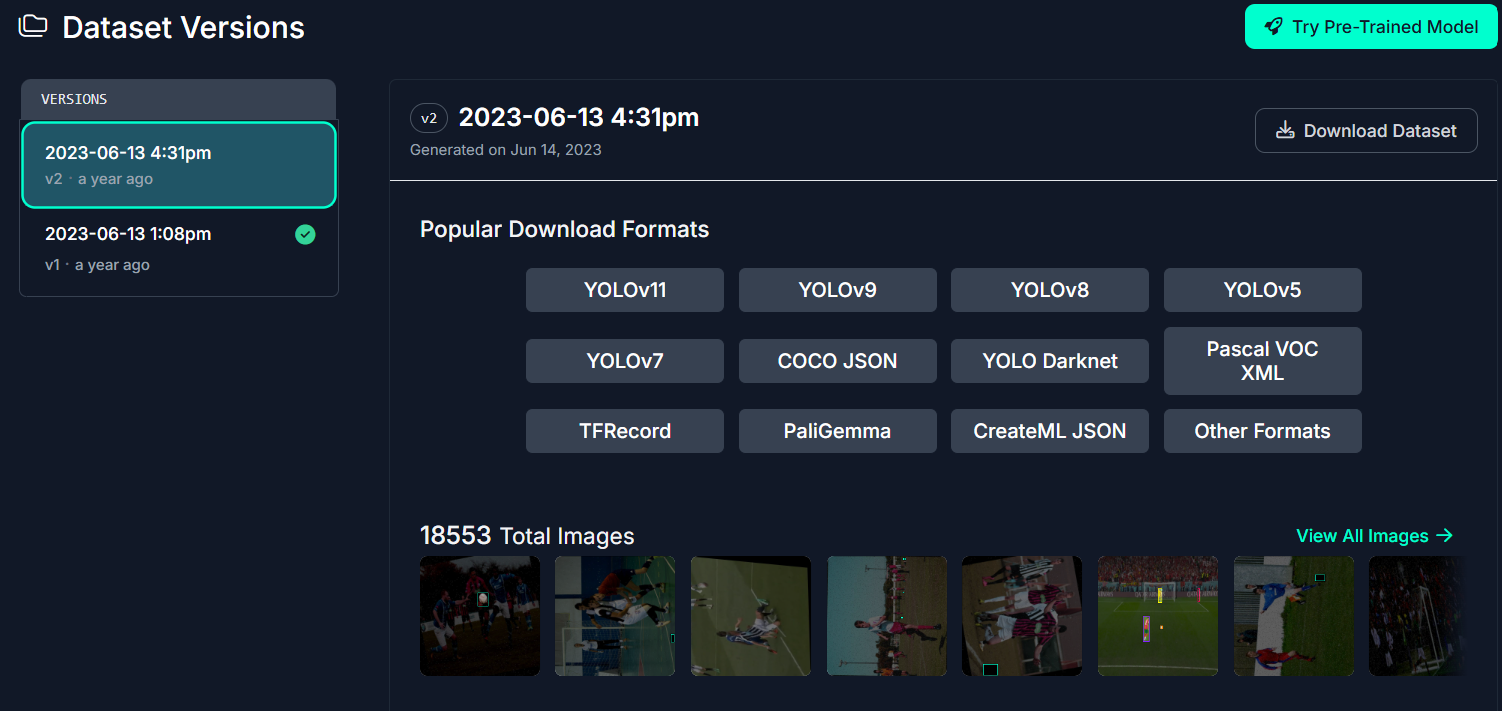
- 다운로드 방식 선택
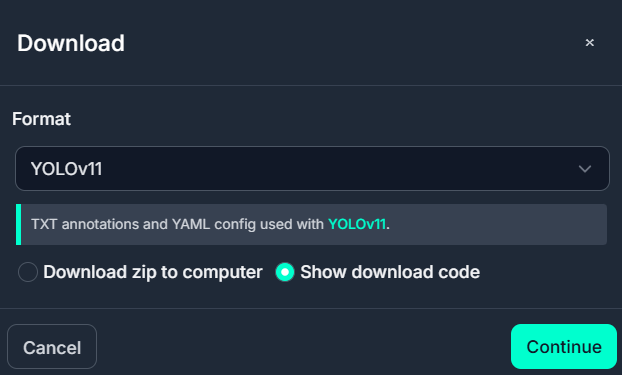
- Download zip to computer : 컴퓨터 자체에 데이터 다운로드
- Show download code : 코드를 이용한 다운로드
- Show download code 선택 후 코드 다운로드 방식 선택
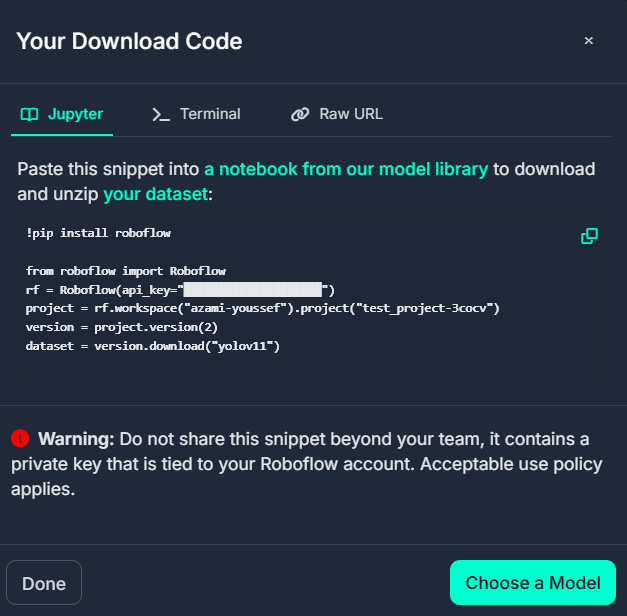
4-3. 코드 사용
!pip install roboflow
from roboflow import Roboflow
# 위 방법으로 가져온 데이터 다운로드 코드 입력
rf = Roboflow(api_key="API") # API 공개 불가
project = rf.workspace("azami-youssef").project("test_project-3cocv")
version = project.version(2)
dataset = version.download("yolov11")
- 데이터가 들어있는 폴더 생성
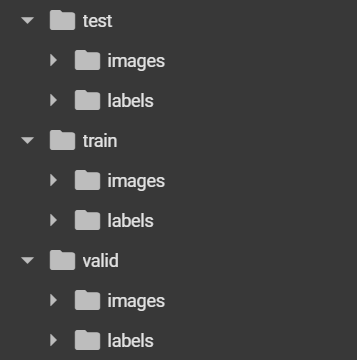
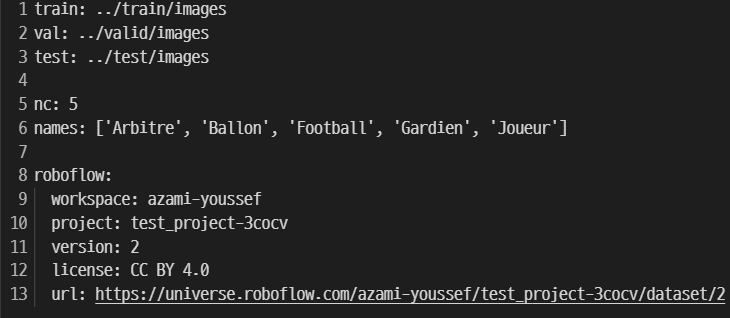
- 해당 폴더에는 이미지와 해당 이미지에 대한 클래스 정보, Normalize 된 x, y, w, h 값이 들어가 있음
- data.yaml 폴더
- train, val, test 데이터의 경로
- nc : 클래스 수
- names : 클래스별 이름
results_train = model_transfer.train(model='/content/yolov11n.pt',
data='/content/test_project-2/data.yaml',
# 학습할 데이터(data.yaml) 입력
epochs=10,
seed=2024,
pretrained=True,
)5. Roboflow를 이용한 데이터셋 생성
- Roboflow 접속 후 New Project 선택
- Project Name과 Annotation Group 입력 후 원하는 작업 선택(본인은 Object Detection 선택)
- 이미지 업로드 후 Save and Continue 선택
- 라벨링 옵션 선택
- Auto Label : 유료
- Roboflow Labeling : 유료
- Manual Labeling : 무료
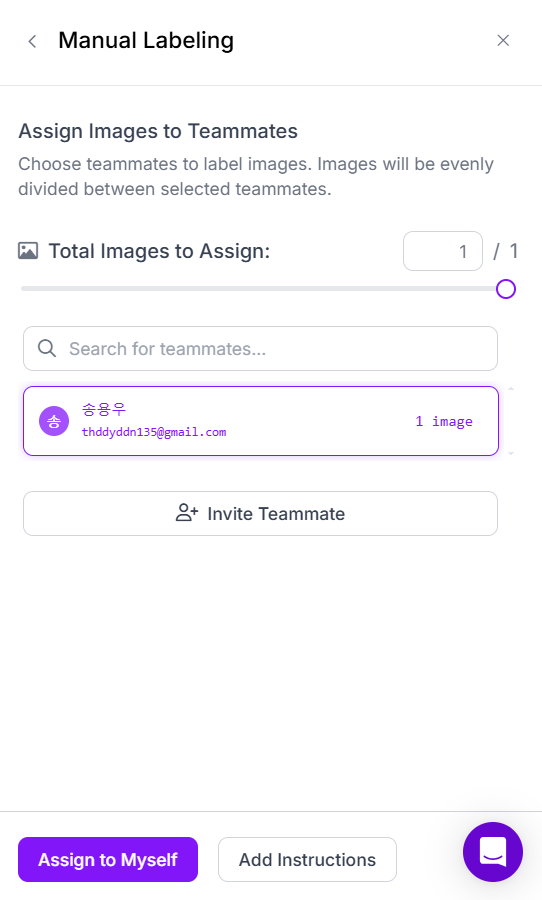
- Invite Teammate로 협업할 동료 이메일 기입 가능
- Starting Annotating 선택
- 라벨링 시작
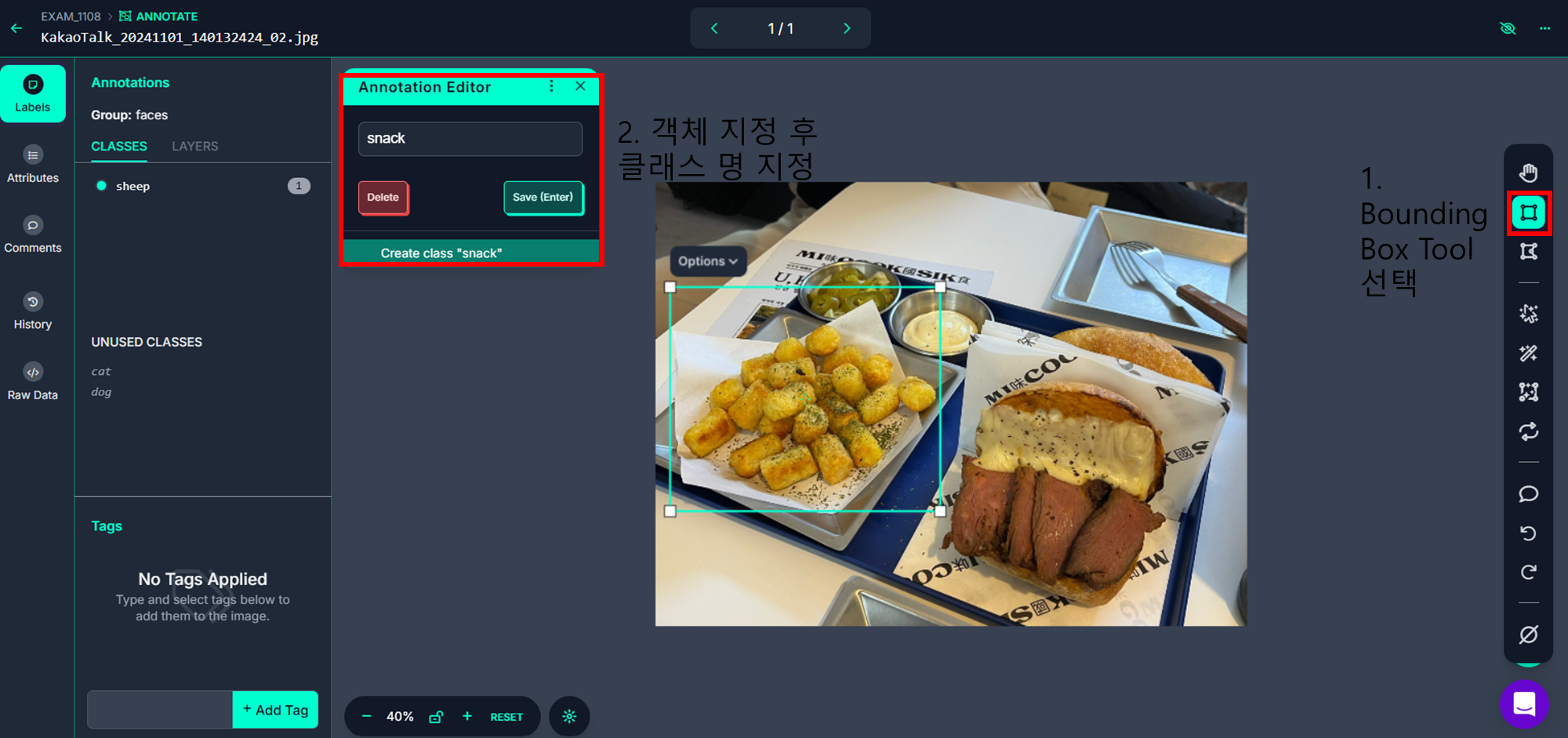
- ESC를 누를 경우 Annotate 페이지로 돌아옴
- Add 'N' image to Dataset 선택
- 데이터셋 비율 설정
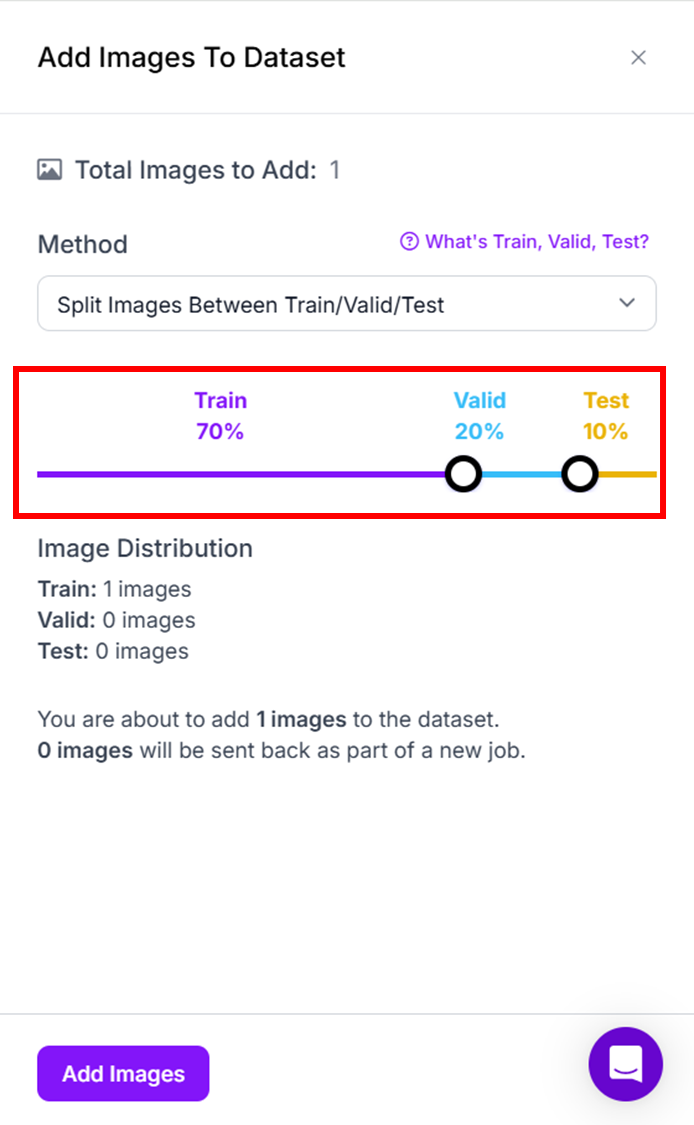
- 우측 상단의 New Version 선택
- 데이터 처리 방식 선택
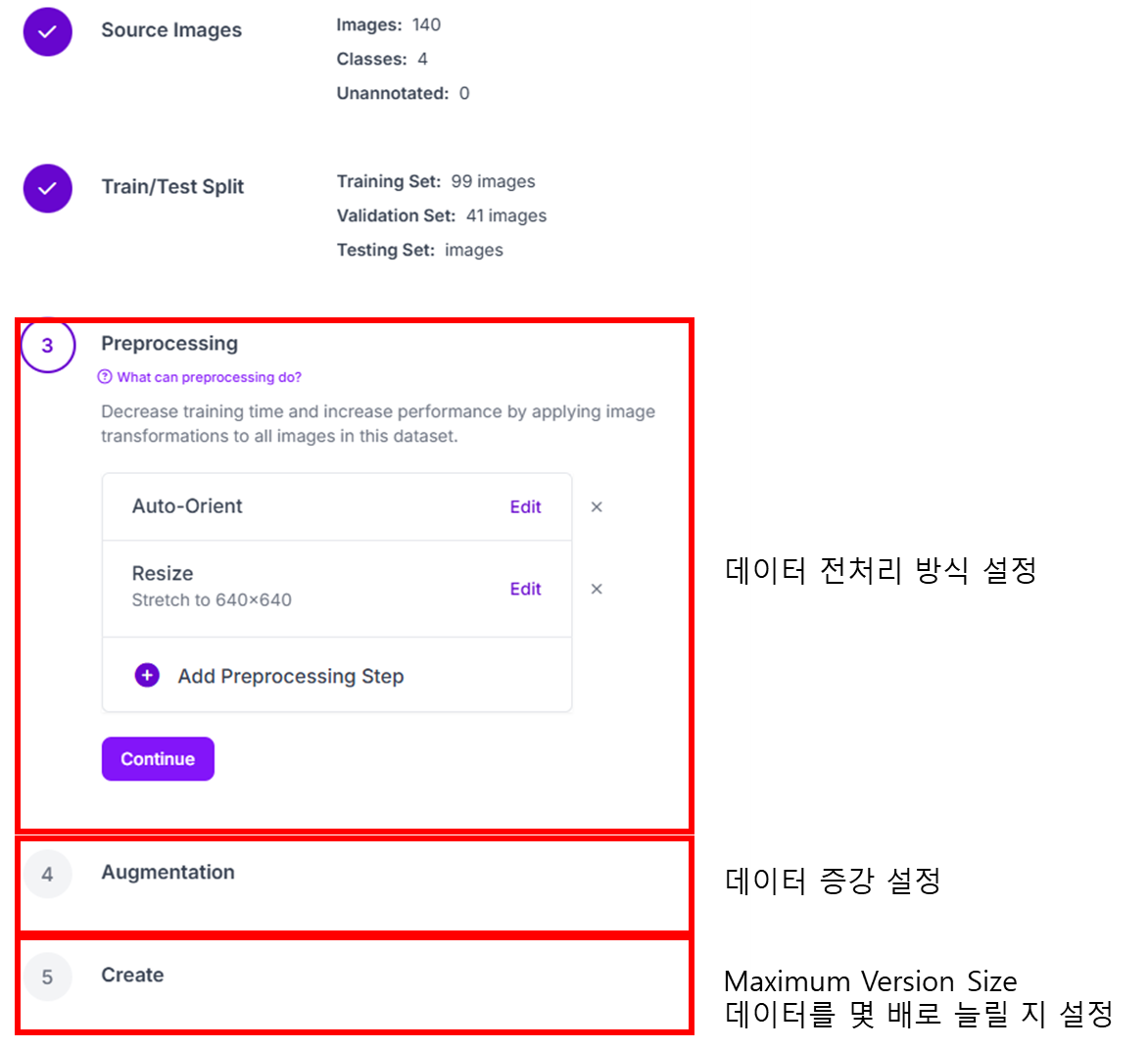
- 데이터셋 사용
- 우측 상단에 Download Dataset를 선택하여 데이터셋 다운로드 가능
- Univers와 사용법 동일

데이터 분석가&엔지니어를 희망하는 취준생