ArchesWeather 논문 리뷰: An efficient AI weather forecasting model at 1.5º resolution
https://github.com/gcouairon/ArchesWeather.
Abstract
기상 예측 시스템을 설계할 때 물리적 제약을 Neuralnet에 유도편향(Inductive prior) 으로 포함하는 것이 일반적이다. 대표적인 예로, Pangu-weather에서 3D local attention을 적용하여 (대기의 상층과 하층의 인접한 기압 level 사이의 상호작용을 강조) locality를 적용한 대표적인 사례이다. 반면, 일부 연구에서 이런거 없이도 뛰어난 기상 예측 성능을 달성할 수 있음을 보였으나, 그만큼 모델이 무겁다. (많은 파라미터를 필요로 한다)
이 논문에서는 Pangu-Weather의 3D local processing이 연산적으로 최적이 아님을 보인다. 이를 개선하기 위해 2D-attention과 column단위의 attention 기반 feature interaction module을 결합한 ArchesWeather 모델을 만들었다고 한다.
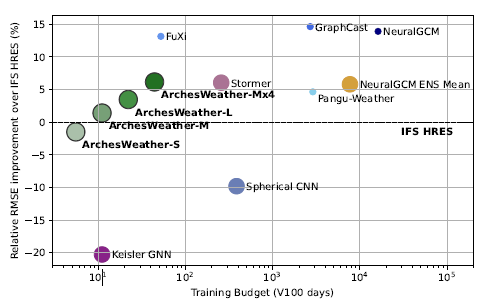
x축 : 학습하는데 걸린 시간 (V100기준)
y축 : 기존 수치모델(NWP)보다 얼마나 개선 됐는지
ArchesWeather-M : 단일모델
ArchesWeather-M x 4 : 4개 앙상블
ArchesWeather은 1.5° 해상도와 24h Leadtime으로 train 되었고, 학습도 며칠 안걸린다. inference-cost도 낮은데 4개의 ArchesWeather모델을 앙상블한 결과 IFS HRES보다 좋았고, 1.4º 해상도 50개 앙상블한 NeuralGCM과 비교해도 1~3일 예측에선 경쟁력이 있다고 한다.
Instroduction
기상 예측 분야는 AI 모델의 발전과 함께 변화를 겪고 있다. ERA5 reanalysis dataset으로 학습된 AI 모델들이 기존수치 기상 예측(NWP, Numerical Weather Prediction) 모델인 IFS-HRES보다 뛰어난 성능을 보이고 있으며, 동시에 inference-cost도 몇 배 이상 절감할 수 있는 수준에 이르렀다고 한다.
보통 얘네들은 ComputerVision 분야에서 발전된 구조를 채택하며 물리적 기상 데이터를 효과적으로 처리하기 위해 inductive priors 를 포함하고 있다.
단기로 보면 물리적 제약이 필요 없는데 장기적으로 볼땐 얘네가 필요하다고 한다. 예를 들어 바다를 생각해보면, 물은 비열이 높기 때문에 에너지를 장기간 축적하고 이 에너지가 장기적 예측에 영향을 주기 때문에 이 feature가 단기로 볼땐 필요 없고 장기 예측엔 필수적이다.
- Pangu-Weather : 3D loacl attention을 활용하여 대기의 지역적 특성을 반영
- FourCastNet : 푸리에 변환 기반 연산(Fourier Spherical Operators)을 사용
- GraphCast : 구형 메시(mesh) 위에서의 그래프 신경망(GNN)을 적용
- NeuralGCM : 기존의 수치 예측 모델의 동역학 코어(dynamical core) 개념을 도입
이런 priors들은 수치 모델과의 유사성을 높이고 적은 파라미터로도 높은 성능을 달성 가능한 장점이 있다. 그러나 최근 연구들에선(Nguyen et al., 2023; Chen et al., 2023; Lessig et al., 2023) priors가 줄어든 모델 도 충분히 일반화 가능하며 오히려 train cost가 적게든다는 점을 강조하고 있다. 많은 priors를 가진 모델이 최적화가 어렵다는 것이다.
이 연구들에선 ERA5 Data를 위성 이미지처럼 다루고 상층 대기변수를 channel 차원에 추가하는 방식을 통해 ViT 아키텍처를 적용했다. 하지만 기존 연구보단 훨씬 더 많은 파라미터 (Stormer: 300M, FuXi:1.5B)를 요구하는 단점이 있다.
뭐 여튼간에, 이 연구에선 Pangu-Weather가 사용하는 3D local-attention의 비효율성을 지적하면서 새로운 Cross-Level Attention(CLA) 기법을 제안한다.
기존 Pangu-Weather의 3D loacl-attention 문제점:
1. 신경망 내부에서 인접한 기압 level 간의 상호작용만 고려하는 구조를 가진다.
-> 물리적 특성을 반영하려 하였으나 연산적으로 비효율적임, golbal feature interaction이 부족함.
ArchesWeather의 해결책:
3D local attention을 제거하고 2D attention + colunmn단위의 Cross-Level Attention(CLA)기법 적용
-> 수직적 대기 상호작용을 효과적으로 모델링 하면서도 computing cost를 줄임
또한, ERA5 Data의 2000년 이전과 이후 발생하는 distribustion shift가 존재해서 최근 데이터로 fine-tuning하는 기법을 적용하였다고 한다.
1.5º에서 학습, 경량모델(학습하는데 며칠 안걸림), low copute cost, 최신데이터 finetuning
Methods
Notation;
-
(과거 기상 데이터)
는 기상 변수들의 과거 시간에 대한 연속적인 변화(trajectory)를 나타냄.
즉, 현재까지의 기상 데이터(history)를 의미. -
(미래 기상 상태 예측값)
는 주어진 를 기반으로 예측해야 하는 미래의 기상 상태를 의미.
예를 들어, 가 2025년 3월 5일 00:00 UTC의 기상 상태라면, 는 2025년 3월 6일 00:00 UTC의 예측 값이 됨. -
(Lead Time)
는 예측하고자 하는 미래 시점까지의 시간 차이
논문에서는 = 24h로 설정됨 → 즉, 24시간 후의 기상 상태를 예측하는 문제2.1. Data, Evaluation and Metrics
Data
-
ERA5 dataset, 1.5º resolution
-
6 Upper air variable (temperature, geopotential, Specific Humidity, Wind components U,V,W)
상층 대기 변수(기온, 지오포텐셜, 습도, 바람성분 동서, 남북, 상하)
13pressure level -
Surface Variable(2m temperature; T2M, mean sea-Level Pressure; SP, 10m wind;U10M, V10M)
-
6시간 간격으로 샘플링(00UTC, 12UTC)
Evaluation, Metrics
-
train (1979-2018), val (2019), test (2020)
-
RMSE, RRH
RRH(Relative RMSE Improvement) 지표를 사용하여 AI 모델이 IFS HRES 대비 얼마나 개선되었는지 평가
2.2 Architecture
-
3D Swin U-Net transformer 사용 (Pangu-weather에서 영감을 얻음)
Earth-specific Positional bias적용함 -
surface 또는 Upper-air variable을 하나의 tensor로 임베딩 (d,Z,H,W)
d: dimension, Z : vertical-dim (기압레벨) H,W : latitude, longitude
-> 이후 U-Net transformer가 처리함
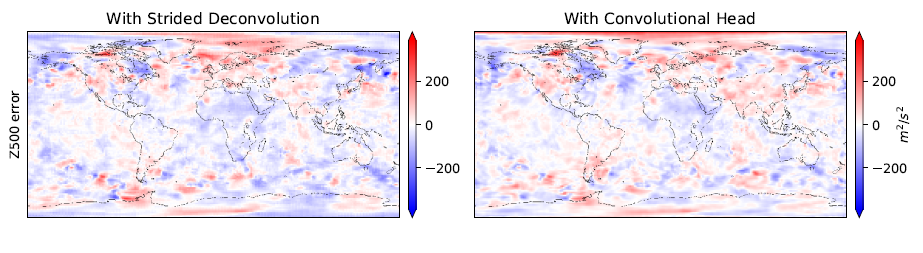
보통 final projection 할 때, strided deconvolution을 쓰는데 이건 약간 비물리적 경향(un-physical artefacts)이 나타남. 북극과 남극 근처에 checkerboard artefact가 나타남. 그래서 대신에! 이 논문은 Bilinear Upsampling + convolutional Head를 사용함
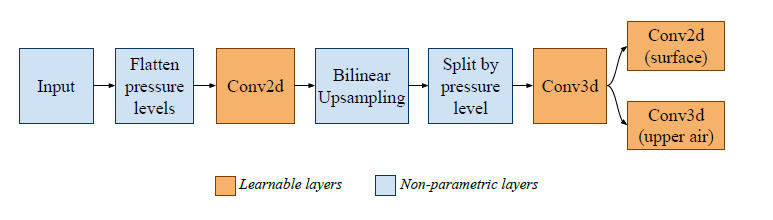
Bilinear Upsampling 앞 뒤에 conv를 넣음
그래서 오른쪽 그림(With Convolutional Head)을 보면 좀 부드럽게 되었다고 함.
2.3 Improving efficiency with Cross-Level Attention(CLA)
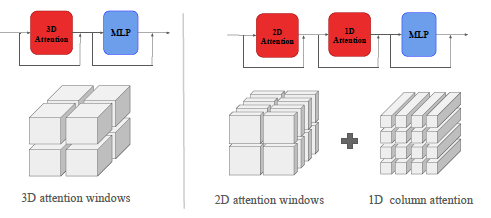
왼쪽이 Pangu-Weather scheme이고, 오른쪽이 우리꺼.
왼쪽 보면, 입력 tensor를 겹치지 않는 작은 window로 분할 후, 각 윈도우를 독립적으로 Self-Attention 레이어에서 처리하는 방식으로 구성된다.
데이터를 Half-window 크기만큼 이동하여 다음 Self-Attention 계산하고, 이를 통해 서로 다른 attention window 간에 상호작용이 가능해진다.
Pangu-Weather에서는 input tensor를 (2,6,12) 크기의 3차원 window로 분할한다.
2개 층, 6개(위도방향), 12개(경도방향) 즉 2개 층만 직접 연결하면서 짧은기간내에 상하층간의 상호작용을 local로 주고 받는다는 물리적 원리가 있는거다. 이 inductive prior은 물리적 현상을 재현하면서 parameter도 줄이는 역할을 한다.
Limitation
coputational 관점에서 보면 이런 Inductive Prior는 제한점이 된다.
서로 다른 대기층(atmospheric layer)에서 발생하는 유사한 현상은 각 층에서 독립적이고 parallel하다.
만약 Global Vertical interation이 가능하면 computation이 공유될 수 있어 resource를 allocating 할 수 있다. 계산 복잡한 변수 애들도 더 빠르게 여러층에 전잘 될 수 있어서 오차를 줄일 수 있다. 마지막으로, physical 관점에서 봤을때도 vertical interaction은 대기의 수직구조(vertical Profile)를 더 잘 감지할 수 있고 발전된 processing을 할 수 있다.
Computational 문제를 해결하기 위해 두 가지 정도 제안 할 수 있는데 한계도 있다.
첫 번째는, attention window 크기를 늘리는 것이다. (2,6,12)에서 (4,6,12)로 바꾸면 vertical 정보교환이 빨라진다. 대신 inference 속도는 quadratic으로 비용이 증가한다.
두 번째로는, 2D transformer를 사용하는거다. 모든 spatial position에서 각 기압층 변수를 하나의 vector로 표현하는거다(:stack variable). 근데 그러면 기압층의 embedding dimension을 라고 하고 가 기압층 개수면 시간 복잡도가 된다.
결론은 Stormer 모델은 ViT-L구조로 3억개 param, FuXi는 SwinV2 아키텍처 사용해서 1.5억개 param을 가진다.
Proposed solution
3D local attention 방식을 대체하여, Cross-level Attention 기법을 제안함.
Z방향에서 기압층 간 정보를 교환하면서 연산량을 줄이는 방식이다.
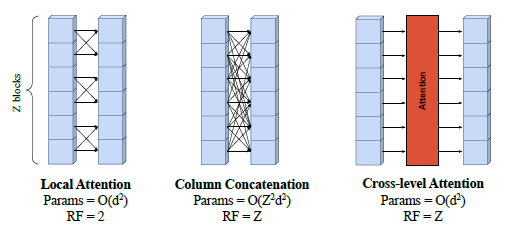
(Left: Pangu) (Middle: Stormer, FuXi) (Right : Ours)
| Attention 방식 | 파라미터 수 (Params) | Receptive Field (RF, 수직 정보 범위) | 특징 |
|---|---|---|---|
| Local Attention (Pangu-Weather) | O(d²) | RF = 2 (이웃한 두 기압층만 상호작용) | 국소적인(Local) 정보만 학습, 계산량 적음 |
| Column Concatenation (Stormer, FuXi) | O(d²Z²) | RF = Z (모든 기압층을 연결 가능) | 긴 범위 정보를 학습할 수 있지만, 파라미터 수가 많아짐 |
| Cross-Level Attention (CLA, ARCHESWEATHER) | O(d²) | RF = Z (모든 기압층을 연결 가능) | 적은 계산량으로 전체 Z 레벨 정보 학습 가능 |
CLA의 핵심 아이디어
- Vertical Dimension에서만 어텐션을 수행하는 Column-wise Attention을 추가함.
- 각 기압층(Z)데이터를 하나의 Sequence로 간주하여 Self-Attention 수행.
- 즉, Z방향에서 모든 기압층이 연결되어 정보를 주고받을 수 있음.
- Pangu-Weather의 3D window (2,6,12) 대신, (1,6,12) window 사용하여 Z방향 Local attention 제거
계산량이 감소해서 더 효율적인 모델이 가능해진 것이다.
2.4 Training detail
모델은 파라미터와 앙상블에 따라 여러 버전이 있는데, 초기 모델은 옛날 데이터를 잘 못만춘다고 한다.
ARCHESWEATHERS,
16 transformer layers (49M parameters);
ARCHESWEATHER-M, 32 layers (89M parameters);
ARCHESWEATHER-L, 64 layers (164M parameters)
ARCHESWEATHER-MX4 (four Mmodels)
ARCHESWEATHER-LX2 (two L models). 등등..
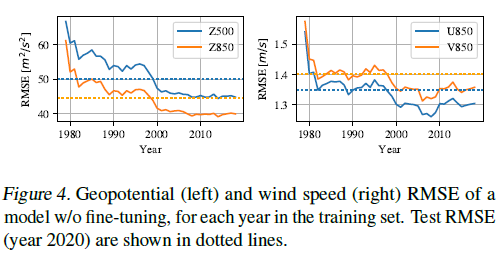
- 아마 옛날이라 위성 데이터가 부족해서 그렇다는데 그래서 Auto-Regressive Rollout Fine-Tuning을 20,000(20k) 스텝 동안 적용하여 모델의 장기 예측 성능을 향상시킴.
Auto-Regressive Rollout Fine-Tuning 과정
- 300,000(300k) 스텝까지 기본 훈련 진행
- 300k 이후 20k 스텝 동안 Auto-Regressive Fine-Tuning 적용
- K = 2: 처음 8,000(8k) 스텝 동안 2스텝 롤아웃(48h 예측)
- K = 3: 다음 8,000(8k) 스텝 동안 3스텝 롤아웃(72h 예측)
- K = 4: 마지막 4,000(4k) 스텝 동안 4스텝 롤아웃(96h 예측)
각 단계에서 롤아웃된 예측값의 손실을 평균화하여 학습 진행
그래서 결과는??
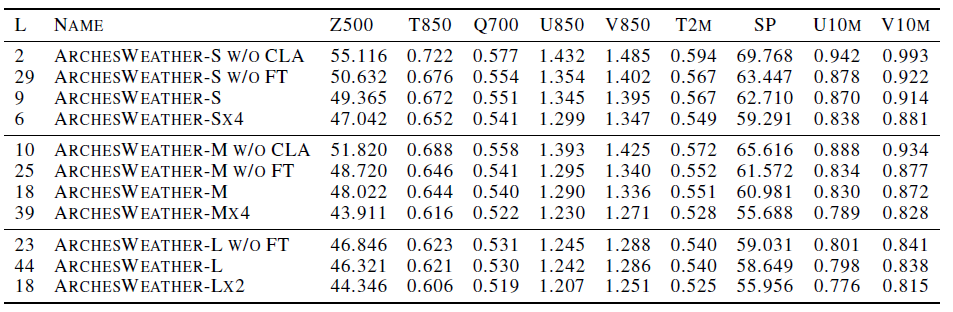
(w/o: without, FT: finetuneing, CLA: Cross-Level-Attention) 변수별로 RSME를 보여주는 표인데, 실험결과들을 보면 점점 성능이 좋아지는 것을 볼 수 있다. 근데 앙상블은 신인가?
Train 여러가지 기술
- normalized 하고, 학습 할 때 변화량을 학습하도록 했다고 한다.(GraphCast, Pangu-Weather도 비슷한 방식을 쓴다고함)
그러니까, 가 아니라 -를 학습하도록 한 것이다. - AdamW, 3e-4, cosine schedule, weight decay: 0.05
3e-4는 국룰인가? - Density-Based Weighting : 대기 밀도를 반영한 가중치 조정
-> 대기 밀도 비례하여 손실 조정, GraphCast도 비슷하다고 한다. 그래서 surface(낮은 기압층)의 변수를 더 중요하도록 유도하는 것이다. - Surface Variable에 추가 가중치를 준다. (T2M:temperature at 2m 얘는 중요해서 1, Wind component 얘는 덜 중요해서 0.1)
Comparision of AI weather model
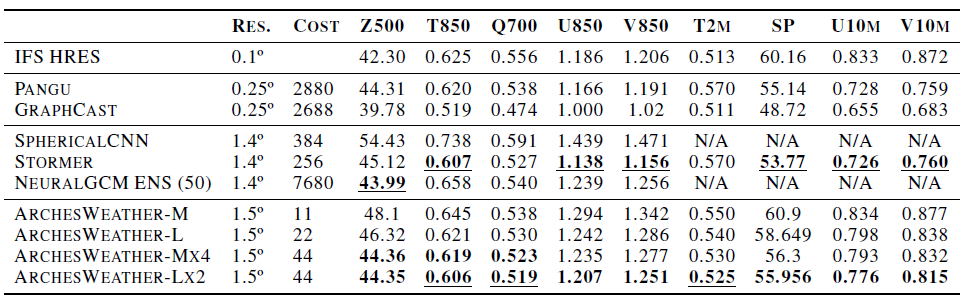
RMSE score이고, 24 lead-time, V100, Best score: Bold + 밑줄, second best score : Bold
-
SphericalCNN
cost 40배 능가!! (10 vs 384), RMSE 능가!!@ -
NeuralGCM(50개 모델 앙상블)
50개 모델 앙상블은 cost 너무 비싸! 하지만 우리는 겨우 4개로도(Mx4) 비슷한 성능을 낸다고! -
Pangu-Weather, Stormer
거의 비슷한데, 바람 변수(U850, V850, U10M, V10M)에서 조금 성능이 딸림.
하지만! Stormer는 모델 크기도 크고, 훈련데이터도 많고, 한 번 예측할 때 16번의 forward pass가 있기 때문에!
우리게 좀 더 낫다.;
24h (직접 24시간 예측)
12h-12h (12시간씩 두 번 예측)
12h-6h-6h
6h-12h-6h
6h-6h-12h
6h-6h-6h-6h 이런식으로 평균 내서 예측하는데 어떻게 이겨.. 그래서! Appendix의 2번을 보면 이렇게 써져 있습니다.
Stormer vs. ARCHESWEATHER 비교
| 비교 항목 | Stormer | ARCHESWEATHER |
|---|---|---|
| 파라미터 수 | 300M | 89M ~ 164M |
| 예측 방식 | 여러 리드 타임 조합 사용 (6h, 12h, 24h) 후 평균화 | 단순한 24h 예측 수행 (Auto-Regressive Rollout 사용 가능) |
| Forward Pass 횟수 | 16번 실행 필요 | 2~4번 실행 |
| 연산 비용 | 매우 높음 (16배 더 많은 계산량) | 훨씬 낮음 (최대 13배 더 효율적) |
| 실시간 예측 가능성 | 높은 계산 비용으로 실시간 예측 어려움 | 더 적은 연산량으로 실시간 예측 가능 |
연산량 비교
| 모델 | 파라미터 수 (Parameters) | Forward Pass 횟수 | 총 연산량 |
|---|---|---|---|
| Stormer | 300M | 16번 | 4800M (4.8B) |
| ARCHESWEATHER-LX2 (2개 모델 앙상블) | 164M | 2번 | 328M |
| ARCHESWEATHER-MX4 (4개 모델 앙상블) | 89M | 4번 | 356M |
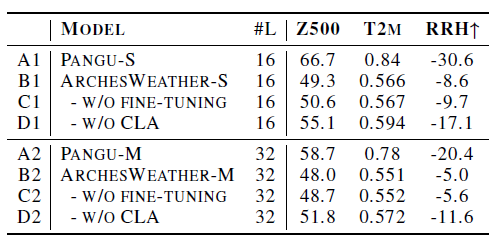
Pangu-Weather(동일한 환경에서 재훈련된 버전)과 비교했을 때, Cross-Level Attention(CLA)이나 FineTuning(FT)을 적용하지 않은 ARCHESWEATHER 모델도 성능이 크게 향상되었다(rows D vs. A).
이러한 성능 향상은 주로 GraphCast의 방법론적 개선(Pangu-Weather 대비 -를 예측하는 방식, 바람 변수의 수직 성분 포함, 날짜 및 월별 조건 추가, Convolutional Head 사용) 덕분이다.
Conclusion
ARCHESWEATHER를 소개하였다.
이 모델은 1.5º 해상도에서 동작하며, 훈련에 필요한 연산량이 적고, 1TB 미만의 비교적 작은 데이터셋만으로도 학습할 수 있다.
그럼에도 불구하고, 훨씬 높은 계산 자원을 사용하여 훈련된 일부 모델들과 유사한 성능을 달성하였다.
또한, 최근 데이터로 Fine-Tuning을 수행하면 예측 성능이 소폭 향상됨을 확인하였다.
그러나, ARCHESWEATHER는 태풍 추적(cyclone tracking)이나 지역 예측(regional forecasting)처럼 더 높은 해상도를 필요로 하는 응용 분야에는 적합하지 않을 수 있다.
향후 연구에서는 ARCHESWEATHER의 출력을 더 높은 해상도로 다운스케일링하고, 물리적으로 일관된 상태로 보정하는 방법(예: 확산 모델(Diffusion Models) 활용)을 탐색할 수 있을 것이다.
