CTAB-GAN+:Enhancing Tabular Data Synthesis
CTAB-GAN+:Enhancing Tabular Data Synthesis
Abstract
오늘날 데이터 중심의 세계에서 데이터를 공유하고 활용하는 능력은 다양한 산업 분야에서 혁신과 지식 개발을 촉진하는 데 매우 중요하다. 그러나 개인정보 보호 문제와 GDPR(일반 데이터 보호 규정)과 같은 엄격한 규제 프레임워크는 데이터의 자유로운 흐름을 크게 제한한다. 이러한 문제를 해결하기 위해 CTAB-GAN+는 차별적 개인정보 보호(DP)를 통해 높은 품질의 합성 테이블 데이터를 생성하는 새로운 조건부 테이블 GAN 모델을 도입하였다.
CTAB-GAN+ Introduction
CTAB-GAN+는 이전의 테이블 데이터 합성 모델들과는 다른 여러 가지 고급 기능과 기술을 통합하여 차별화된다:
- 조건부 GAN 구조: 특정 속성에 따라 데이터를 생성할 수 있어 데이터 불균형 문제를 효과적으로 해결한다.
- 고급 특성 인코딩: 연속형, 범주형, 혼합형 데이터를 포함한 다양한 데이터 타입을 정확하게 모델링하기 위해 혁신적인 인코딩 방법을 사용한다.
- Wasserstein Loss 및 그래디언트 패널티(Was+GP): 훈련 과정의 안정성과 성능을 향상시켜, 그래디언트 폭발과 소실 문제를 해결한다.
- Differential privacy(DP): differential privacy를 구현하여 학습 과정에서 민감한 정보를 보호하고, DP-SGD(차별적 개인정보 보호 확률적 경사 하강법)를 사용하여 개인정보 보호를 보장한다.
주요 구성 요소
G,D,A
CTAB-GAN+는 세 가지 주요 구성 요소로 구성되어 있다:
- Generator: 입력 데이터의 다양한 특성을 학습하여 새로운 합성 데이터를 생성한다.
- Discriminator: 실제 데이터와 합성 데이터를 구별하여 생성기가 더 현실적인 데이터를 생성하도록 유도한다.
- Auxiliary Component: 생성된 데이터의 유용성을 높이기 위해 추가적인 학습 신호를 제공하며, 분류 문제에서는 분류기, 회귀 문제에서는 회귀 분석기로 작동할 수 있다.
Conditional GAN Architecture
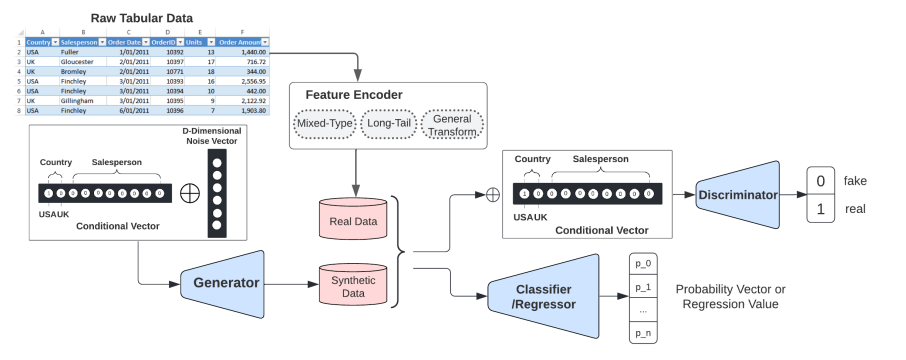
CTAB-GAN+는 조건부 GAN 프레임워크를 채택하여 특정 조건에 맞는 데이터를 생성할 수 있다. 이 구조는 데이터셋 내 클래스 불균형 문제를 해결하는 데 특히 유용하며, 부족한 클래스의 데이터를 더 많이 생성할 수 있도록 한다. 이 구조는 데이터 불균형이 있는 상황에서도 합성 데이터 분포가 실제 데이터 분포와 유사하도록 보장한다.
Mixed-type Encoder
CTAB-GAN+는 다양한 테이블 데이터 특성을 처리하기 위해 고급 인코딩 전략을 도입하였다:
- Continuos: 복잡한 분포를 효과적으로 처리하기 위해 모드별 정규화(MSN:Mode-Specific Normalization)를 사용한다.
- Categorical: 원-핫 인코딩을 사용하되, 범주 수가 많은 변수를 처리할 때 차원 폭발 문제를 방지한다.
- Mixed - type : 연속형과 범주형 요소를 모두 포함하거나 결측값이 있는 변수를 처리하기 위해 새로운 혼합형 인코더를 사용한다. 이 인코더는 값을 값-모드 쌍으로 처리하여 정확한 표현과 처리가 가능하도록 한다.
Wasserstein Loss 및 그래디언트 패널티(Was+GP)
GAN 훈련의 안정성을 향상시키기 위해 CTAB-GAN+는 Wasserstein Loss과 그래디언트 패널티를 사용한다. 이 접근법은 그래디언트 폭발과 소실 문제를 완화하고, 훈련 과정을 안정화하며 광범위한 하이퍼파라미터 튜닝의 필요성을 줄인다. Was+GP 손실은 더 부드럽고 일관된 훈련 동력을 제공하여 높은 품질의 합성 데이터를 생성할 수 있도록 한다.
Differential Privacy
CTAB-GAN+는 DP-SGD를 통해 차별적 개인정보 보호를 구현하였다. 이는 훈련 중 그래디언트 계산에 노이즈를 추가하여 개별 데이터 포인트가 모델 매개변수에 미치는 영향을 최소화함으로써 강력한 프라이버시 보장을 제공한다. 훈련 과정이 차별적 프라이버시를 준수하도록 보장하여 GDPR과 같은 규제 요구사항을 충족한다.
Technical Background
Table GAN
이전의 테이블 GAN 모델은 주로 연속형 또는 범주형 데이터 생성에 초점을 맞췄지만, 혼합형 데이터 또는 불균형 데이터 처리가 부족하였다. 또한, 이러한 모델들은 차별적 개인정보 보호를 충분히 고려하지 않아 데이터 프라이버시 문제가 발생할 수 있었다. CTAB-GAN+는 이러한 한계를 극복하기 위해 설계되었다.
Differential Privacy
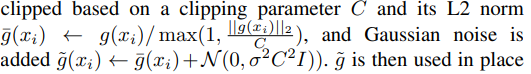
차별적 개인정보 보호(DP)는 개인 데이터 포인트의 영향을 최소화하는 수학적 프레임워크이다. CTAB-GAN+는 더 엄격한 프라이버시 보장을 제공하는 Rényi Differential Privacy(RDP)를 사용하며, DP-SGD를 통해 이를 구현한다. 이는 훈련 중 노이즈를 추가하여 그래디언트 업데이트에 개별 데이터 포인트의 영향을 줄인다.
실험
CTAB-GAN+는 다양한 데이터셋에서 엄격한 평가를 거쳤으며, 기존의 최첨단 테이블 데이터 생성 모델에 비해 기계 학습 유용성과 통계적 유사성 모두에서 뛰어난 성능을 보였다.
데이터셋 및 평가 지표

평가에는 7개의 다양한 데이터셋이 사용되었다:
- Adult: 소득 수준을 예측하는 분류 데이터셋.
- Covertype: 숲 덮개 유형을 예측하는 분류 데이터셋.
- Credit: 신용카드 사기 탐지 데이터셋.
- Intrusion: 네트워크 침입 탐지 데이터셋.
- Loan: 대출 승인 예측 데이터셋.
- Insurance: 보험료를 예측하는 회귀 데이터셋.
- King: 주택 가격을 예측하는 회귀 데이터셋.
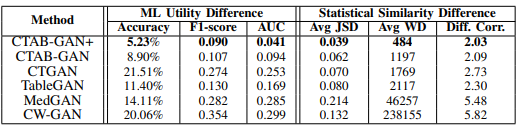
- 기계 학습 유용성: 분류 작업의 경우 정확도, F1-점수, AUC; 회귀 작업의 경우 평균 절대 퍼센티지 오차(MAPE), 설명된 분산 점수(EVS), R² 점수.
- 통계적 유사성: Jensen-Shannon Divergence(JSD), Wasserstein Distance(WD), 변수 간 상관 관계 차이.
결과
CTAB-GAN+는 모든 평가 지표에서 기존 모델을 능가하는 성능을 보였다. 주요 결과는 다음과 같다:
- 분류 성능: CTAB-GAN+는 AUC와 정확도에서 각각 56.4%와 41.2%의 개선을 이루었다.
- 회귀 성능: CTAB-GAN+는 MAPE, EVS, R² 점수에서 높은 예측 정확도를 나타냈다.
- 통계적 유사성: CTAB-GAN+는 JSD, WD, 변수 간 상관 관계 차이에서 기존 모델보다 뛰어난 성능을 보였다.
결론
CTAB-GAN+는 합성 테이블 데이터 생성에서 중요한 발전을 이루어 데이터 유용성과 개인정보 보호의 균형을 유지하는 강력한 솔루션을 제공한다. 고급 특성 인코딩, Was+GP의 안정성, DP-SGD의 프라이버시 보장 등을 결합하여, 금융, 보험, 제조업과 같은 데이터 공유가 중요한 산업에서 유용한 도구로 활용될 수 있다.
미래 연구는 CTAB-GAN+의 적용 범위를 확장하고 추가 실험을 통해 성능을 더욱 향상시키는 것을 목표로 한다. CTAB-GAN+는 합성 데이터 생성의 새로운 기준을 제시하며, 프라이버시 규정을 준수하면서 데이터 공유를 더욱 안전하고 효과적으로 할 수 있는 방법을 제공할 것이다.
부록
기술 세부 사항
- 모드별 정규화(MSN): 연속형 변수를 인코딩하기 위해 Gaussian 혼합 모델(GMM)을 적용하여 각 값을 모드별로 정규화한다.
- 혼합형 인코더: 혼합형 변수를 값-모드 쌍으로 인코딩하여 연속형과 범주형 요소를 모두 정확하게 표현한다.
- 일반 변환(GT): 단일 모드 Gaussian 분포에 대한 대체 인코딩 방법으로, 생성기의 출력 범위와 호환성을 유지한다.
- 긴 꼬리 분포 처리: 긴 꼬리 분포를 가진 변수를 로그 변환하여 데이터의 중심과 꼬리 간 거리를 압축하고 줄인다.
차별적 개인정보 보호 구현
- DP-SGD: 그래디언트 업데이트에 노이즈를 추가하여 개별 데이터 포인트의 영향을 최소화한다.
- RDP Accountant: 누적된 프라이버시 손실을 추적하여 더 엄격한 프라이버시 보장을 제공하고, 프라이버시 예산을 준수한다.
