CNN 실습 예제 따라하기
1. MNIST 이미지 분류
2. 개, 고양이 이미지 분류 (generator사용)
실습1. MNIST 이미지 분류
1-1. 간단한 컨브넷 만들기
- ConvNet은 (image_height, image_width, image_channels) 크기의 입력텐서를 사용한다.
- 이 예제에서 MNIST 이미지 포맷인 (28,28,1)크기의 입력을 처리하도록 ConvNet을 설정해야 하므로 첫 번째 층의 매개변수로 input_shpe(28,28,1)을 전달한다.
- Conv2D와 MaxPooling2D층의 출력은 (height, width, channels) 크기의 3D텐서이다. 높이(height)와 너비(width)는 네트워크가 깊어질수록 작아지는 경향이 있다. 채널(channels)의 수는 Conv2D층에 전달된 첫 번째 매개변수에 의해 조절된다.
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3,3), activation='relu', input_shape=(28,28,1)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3), activation='relu'))
model.summary()실행결과:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 3, 3, 64) 36928
=================================================================
Total params: 55,744
Trainable params: 55,744
Non-trainable params: 0
_________________________________________________________________1-2. 컨브넷 위에 분류기 추가하기
- 위 단계에서 마지막 층의 (3,3,64)크기인 출력 텐서를 완전 연결 네트워크에 주입한다.
- 완전 연결 네트워크는 Dense층을 쌓은 '분류기'이다.
- 이 분류기는 1D벡터를 처리하는데, 이전 층의 출력이 3D텐서이므로, 3D출력을 1D텐서로 펼쳐야 한다. >> Flatten
- 그 다음에 몇 개의 Dense층을 추가한다.
- 10개의 클래스(숫자 0~9)를 분류하기 위해 마지막 층의 출력 크기를 10으로 하고, softmax활성화함수를 사용한다.
model.add(layers.Flatten()) # (3,3,64)출력이 (576,)벡터로 펼쳐진 후 Dense층에 주입된다.
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
model.summary()실행결과:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 3, 3, 64) 36928
_________________________________________________________________
flatten (Flatten) (None, 576) 0
_________________________________________________________________
dense (Dense) (None, 64) 36928
_________________________________________________________________
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 93,322
Trainable params: 93,322
Non-trainable params: 0
_________________________________________________________________1-3. MNIST 이미지에 컨브넷 훈련하기
from keras.datasets import mnist
from keras.utils import to_categorical
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=64)실행결과:
Epoch 1/5
938/938 [==============================] - 51s 54ms/step - loss: 0.0068 - accuracy: 0.9981
Epoch 2/5
938/938 [==============================] - 50s 54ms/step - loss: 0.0061 - accuracy: 0.9984
Epoch 3/5
938/938 [==============================] - 50s 54ms/step - loss: 0.0031 - accuracy: 0.9991
Epoch 4/5
938/938 [==============================] - 50s 54ms/step - loss: 0.0033 - accuracy: 0.9990
Epoch 5/5
938/938 [==============================] - 50s 54ms/step - loss: 0.0024 - accuracy: 0.9993
<tensorflow.python.keras.callbacks.History at 0x7fe333f65090>test_loss, test_acc = model.evaluate(test_images, test_labels)
test_acc실행결과:
313/313 [==============================] - 3s 10ms/step - loss: 0.0517 - accuracy: 0.9924
0.9923999905586243실습2. 개, 고양이 이미지 분류 (데이터증식)
kaggle의 dogs vs. cats데이터를 사용한다.
2-1. 훈련, 검증, 테스트 폴더로 이미지 복사하기
원래라면 코드를 통해 이미지를 복사하면 되는데 이 코드가 원하는대로 실행되려면 구글드라이브에 이미지파일을 모두 압축해제 해놓아야 한다. 하지만 몇 차례 시도한 결과 3시간에 30퍼의 진행률을 보이며 도저히 2만개가 넘는 이미지를 모두 압축해제 할 수 있을 것 같지 않았다.
그래서 로컬에 압축해제 하고, 직접 구글 드라이브로 개 or 고양이 이미지를 0~999번까지는 train, 1000~1499까지는 validation, 1500~1999까지는 test폴더에 드래그로 옮겨주니 훨씬 빨리 복사할 수 있었다. 여러 시행착오를 겪고 성공한거라 폴더 안의 이미지 수가 딱 떨어지진 않는다.ㅜㅜ
import os, shutil
original_dataset_dir = './drive/MyDrive/Colab Notebooks/datasets/cats_and_dogs/train'
base_dir = './drive/MyDrive/Colab Notebooks/datasets/cats_and_dogs_small'
os.makedirs(base_dir)
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
# fnames = ['cat.{}.jpg'.format(i) for i in range(1000)]
# for fname in fnames:
# try:
# src = os.path.join(original_dataset_dir, fname)
# dst = os.path.join(train_cats_dir, fname)
# shutil.copyfile(src, dst)
# except FileNotFoundError:
# pass
# fnames = ['cat.{}.jpg'.format(i) for i in range(1000, 1500)]
# for fname in fnames:
# src = os.path.join(original_dataset_dir, fname)
# dst = os.path.join(validation_cats_dir, fname)
# shutil.copyfile(src, dst)
# fnames = ['cat.{}.jpg'.format(i) for i in range(1500, 2000)]
# for fname in fnames:
# try:
# src = os.path.join(original_dataset_dir, fname)
# dst = os.path.join(test_cats_dir, fname)
# shutil.copyfile(src, dst)
# except FileNotFoundError:
# pass
# fnames = ['dog.{}.jpg'.format(i) for i in range(1000)]
# for fname in fnames:
# try:
# src = os.path.join(original_dataset_dir, fname)
# dst = os.path.join(train_dogs_dir, fname)
# shutil.copyfile(src, dst)
# except FileNotFoundError:
# pass
# fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1500)]
# for fname in fnames:
# try:
# src = os.path.join(original_dataset_dir, fname)
# dst = os.path.join(validation_dogs_dir, fname)
# shutil.copyfile(src, dst)
# except FileNotFoundError:
# pass
# fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 2000)]
# for fname in fnames:
# try:
# src = os.path.join(original_dataset_dir, fname)
# dst = os.path.join(test_dogs_dir, fname)
# shutil.copyfile(src, dst)
# except FileNotFoundError:
# pass
print('훈련용 고양이 이미지 전체 개수: ', len(os.listdir(train_cats_dir)))
print('훈련용 강아지 이미지 전체 개수: ', len(os.listdir(train_dogs_dir)))
print('검증용 고양이 이미지 전체 개수: ', len(os.listdir(validation_cats_dir)))
print('검증용 강아지 이미지 전체 개수: ', len(os.listdir(validation_dogs_dir)))
print('테스트용 고양이 이미지 전체 개수: ', len(os.listdir(test_cats_dir)))
print('테스트용 강아지 이미지 전체 개수: ', len(os.listdir(test_dogs_dir)))실행결과:
훈련용 고양이 이미지 전체 개수: 1076
훈련용 강아지 이미지 전체 개수: 1020
검증용 고양이 이미지 전체 개수: 500
검증용 강아지 이미지 전체 개수: 501
테스트용 고양이 이미지 전체 개수: 500
테스트용 강아지 이미지 전체 개수: 5082-2. 강아지 vs. 고양이 분류를 위한 소규모 컨브넷 만들기
from keras import layers
from keras import models
model = models.Sequential()
model.add(layers.Conv2D(32, (3,3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128, (3,3), activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()실행결과:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 6272) 0
_________________________________________________________________
dense (Dense) (None, 512) 3211776
_________________________________________________________________
dense_1 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainable params: 3,453,121
Non-trainable params: 0
_________________________________________________________________2-3. 모델의 훈련 설정하기
from keras import optimizers
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])2-4. ImageDataGenerator를 사용하여 디렉터리에서 이미지 읽기
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary'
)
for data_batch, labels_batch in train_generator:
print('배치 데이터 크기: ', data_batch.shape)
print('배치 레이블 크기: ', labels_batch.shape)
break실행결과:
Found 2096 images belonging to 2 classes.
Found 1001 images belonging to 2 classes.
배치 데이터 크기: (20, 150, 150, 3)
배치 레이블 크기: (20,)2-5. 배치 제너레이터를 사용하여 모델 훈련하기
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)실행결과:
Epoch 1/30
100/100 [==============================] - 113s 1s/step - loss: 0.6904 - acc: 0.5291 - val_loss: 0.6770 - val_acc: 0.5390
Epoch 2/30
100/100 [==============================] - 113s 1s/step - loss: 0.6569 - acc: 0.6027 - val_loss: 0.6716 - val_acc: 0.5586
Epoch 3/30
100/100 [==============================] - 123s 1s/step - loss: 0.6124 - acc: 0.6573 - val_loss: 0.7135 - val_acc: 0.6351
.
.
.
Epoch 28/30
100/100 [==============================] - 112s 1s/step - loss: 0.0892 - acc: 0.9694 - val_loss: 1.0027 - val_acc: 0.7278
Epoch 29/30
100/100 [==============================] - 112s 1s/step - loss: 0.0811 - acc: 0.9729 - val_loss: 1.8023 - val_acc: 0.7227
Epoch 30/30
100/100 [==============================] - 113s 1s/step - loss: 0.0632 - acc: 0.9840 - val_loss: 1.2665 - val_acc: 0.73192-6. 모델 저장하기
model.save('cats_and_dogs_small_1.h5')2-7. 훈련의 정확도와 손실그래프 그리기
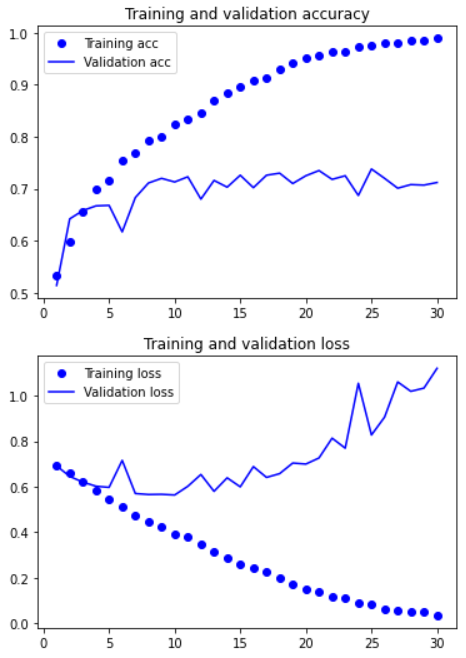
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(acc) + 1)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()실행결과:
2-8. ImageDataGenerator를 사용하여 데이터 증식 설정하기
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
fill_mode='nearest'
)2-9. 랜덤하게 증식된 훈련 이미지 그리기
from keras.preprocessing import image
fnames = sorted([os.path.join(train_cats_dir, fname) for
fname in os.listdir(train_cats_dir)])
img_path = fnames[3]
img = image.load_img(img_path, target_size=(150,150))
x = image.img_to_array(img)
x = x.reshape((1,) + x.shape)
i=0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i+=1
if i % 4 == 0:
break
plt.show()실행결과:


2-10. 드롭아웃을 포함한 새로운 컨브넷 정의하기
from keras import layers
from keras import models
from keras import optimizers
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])2-11. 데이터 증식 제너레이터를 사용하여 컨브넷 훈련하기
from keras.preprocessing.image import ImageDataGenerator
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)실행결과:
Found 2096 images belonging to 2 classes.
Found 1001 images belonging to 2 classes.
Epoch 1/100
100/100 [==============================] - 684s 7s/step - loss: 0.6893 - acc: 0.5377 - val_loss: 0.6676 - val_acc: 0.5789
Epoch 2/100
100/100 [==============================] - 30s 301ms/step - loss: 0.6807 - acc: 0.5634 - val_loss: 0.6159 - val_acc: 0.5914
Epoch 3/100
100/100 [==============================] - 30s 295ms/step - loss: 0.6577 - acc: 0.6016 - val_loss: 0.6913 - val_acc: 0.6189
Epoch 4/100
100/100 [==============================] - 30s 300ms/step - loss: 0.6411 - acc: 0.6363 - val_loss: 0.6605 - val_acc: 0.6190
Epoch 5/100
100/100 [==============================] - 29s 292ms/step - loss: 0.6259 - acc: 0.6395 - val_loss: 0.7564 - val_acc: 0.6728
.
.
.
Epoch 95/100
100/100 [==============================] - 28s 285ms/step - loss: 0.3313 - acc: 0.8546 - val_loss: 0.2591 - val_acc: 0.8192
Epoch 96/100
100/100 [==============================] - 31s 310ms/step - loss: 0.3347 - acc: 0.8540 - val_loss: 0.2464 - val_acc: 0.8224
Epoch 97/100
100/100 [==============================] - 28s 280ms/step - loss: 0.3273 - acc: 0.8532 - val_loss: 0.2781 - val_acc: 0.8497
Epoch 98/100
100/100 [==============================] - 32s 317ms/step - loss: 0.3148 - acc: 0.8643 - val_loss: 0.4643 - val_acc: 0.8121
Epoch 99/100
100/100 [==============================] - 29s 294ms/step - loss: 0.3310 - acc: 0.8554 - val_loss: 0.4055 - val_acc: 0.8256
Epoch 100/100
100/100 [==============================] - 30s 297ms/step - loss: 0.3175 - acc: 0.8527 - val_loss: 0.3398 - val_acc: 0.8301코드 5-15. 모델 저장하기
model.save('cats_and_dogs_small_2.h5')[참고]
케라스 창시자에게 배우는 딥러닝

hi