
Similarity Search란 단어의 직역대로 나와 비슷한 친구를 찾는 알고리즘을 말한다. 머신러닝에서 Unsupervised method로 분류될 수 있는 이 방법이 갖는 장점과 단점을 소개한다.
Similarity Search의 필요성
- 나는 지금 딥러닝을 활용한 Classifier를 배포하려고 한다. 이 엔진은 현재 물품 1,000종에 대해 분류를 해주는 훌륭한 친구지만 앞으로 품목이 얼마나 더 늘어날 지 가늠을 할 수 없다. 또한 언제라도 새로운 품목이 들어올 수 있는 이 상황에서 어떤 방법을 쓸 수 있을까?
- 내가 만든 물품 인식 엔진은 참 훌륭하다. 하지만 가끔씩 잘못된 답을 내놓기도 하는데 그 이유가 궁금하다. 모델적 관점에서 왜 틀렸는지 알면 가장 좋겠지만 그것까지는 안돼도 결과론적 관점에서 왜 틀렸는지 알고 싶지는 않을까?? 그 방법은 뭘까?
Similarity Search vs. Softmax Classifier
딥러닝에서 분류 모델을 조금이라도 아는 사람이라면 이해하기 쉬울 것 같다. Backbone network를 통해 나온 feature를 내가 분류하고자 하는 물품의 수만큼의 노드를 가진 layer에 연결시켜 softmax를 계산한다. 그렇게 나온 수 중 가장 큰 값을 가지는 노드의 인덱스가 바로 클래스이다.
이것이 가장 대표적인 softmax classifier이고 backbone으로 Convolution, RNN, Transformer 그 어떤 계열의 네트워크를 써도 상관은 없다. 필요에 따라 골라서 쓸 뿐. 하지만 문제는 물품의 수가 늘어나면 마지막 layer의 크기를 늘려 다시 학습하는 과정이 필수적이다. 대안은... 없다.
하지만 Similarity search의 방법은 조금 다르다. backbone network를 통해 각 입력의 feature representation을 얻어내는 과정은 같으나 이를 분류하는 과정은 친목회를 통해 이루어진다. 나랑 가장 비슷한 친구는 누구일까? 단지 비슷한 친구만 찾아내기 때문에 만약 그 친구의 정체를 모른다면 그저 '나랑 쟤랑 가장 닮았구나...'라는 결론만을 얻을 수 있겠지만(Clustering) 대개의 경우에는 친구의 정체를 알고 있기 때문에 나도 쟤랑 같은 xx구나(Classification)라는 정보를 알 수 있다. 정리부터 하고 조금 더 자세히 들어가보자.
| - | Classifier | Similarity Search |
|---|---|---|
| 동작 원리 | Feature를 클래스 수에 딱맞게 추론 | Feature를 다른 feature들과 직접적으로 비교하여 가장 비슷한 feature를 찾음 |
| 학습 | 네트워크가 Class-wise한 decision boundary를 찾게끔 학습 | Search 자체는 학습이 필요 없으나 좋은 분류 성능을 갖기 위해서 학습을 하게 되며 그 과정에서 feature-wise하게 일대일로 비교하며 학습 |
| 시간 복잡도 | 보통 낮음 | N개의 feature와 일일히 비교하므로 O(N) |
| 메모리 | 분류 품목의 수에 비례 | 가지고 있는 데이터에 비례 |
| 품목 확장성 | 낮음(늘어날 때마다 새로 학습 필요) | 높음(단순히 Gallery에 추가만 해주면 어떻게든 돌아감) |
용어 정리
Gallery: 현재 가지고 있는 데이터
Query: 정체가 궁금한 새로운 데이터
시나리오:나를 제외한 전세계 사람들(gallery) 중에서 나(query)의 도플갱어를 찾아내는 과정이 similarity search
Search Algorithms
Similarity Search에는 크게 3가지 요소가 있다.
1. 어떻게 feature vector를 만들 것인가
2. Vector 간의 거리를 어떻게 정의할 것인가
3. 빠르고 정확한 탐색을 위한 방법은 무엇인가
이 글에서는 대표적인 search 알고리즘만 소개하려고 한다.
Brute Force
이 방법은무식하지만 가장 정확한 방법이다. gallery의 사이즈가 N이라면 탐색 시간은O(N)이 될 것이고 더 자세하게는 feature의 크기가 d라면O(Nd)의 시간이 걸린다. 하지만 gallery의 모두와 거리를 비교하기 때문에 실수란 있을 수 없다.
Cell-probe Method
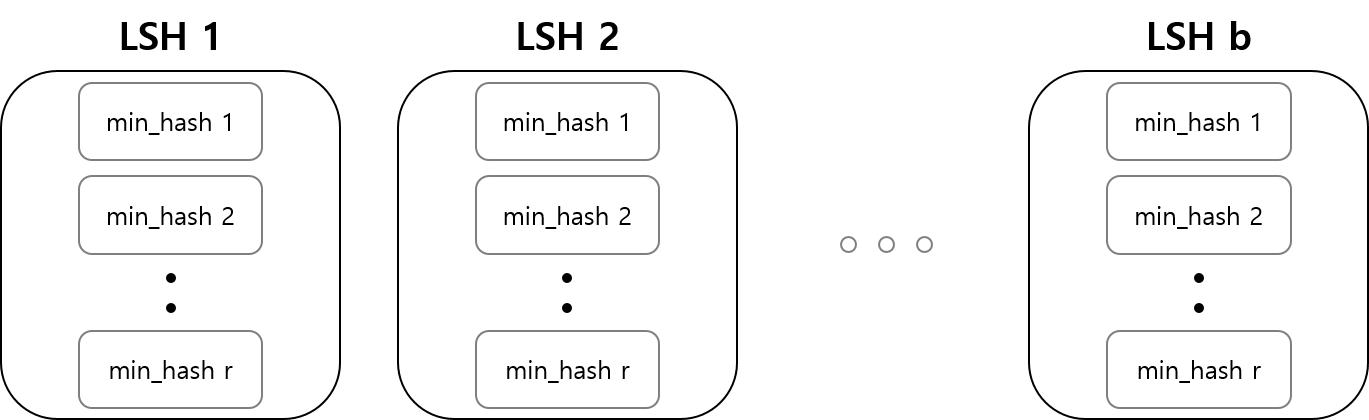
Locality Sensitive Hashing(LSH)으로 대표되는 이 방법은비슷한 데이터는 비슷한 hash code를 가진다는 전제에서 시작한다. 방법은 이러하다.
1.서로 다른 hash function을 가진 (size of k) hash table을 r개 만든다 (이게 하나의 LSH).
2.각 데이터를 만든 r개의 hash table에 모두 넣는다.
3.Query가 들어오면, r개의 hash table을 통해 gallery의 누구와 가장 가까운지 비교한다.
이렇게 하는 이유는 단 하나의 hash table만으로는 유사도가 높지 않은 데이터라 하더라도 같은 hash 값을 가질 수 있기 때문에, 다양한 hash function을 통해 보다 robust한 결과를 얻어내기 위함이다.
원래 같으면 각 데이터의 feature의 subset을 구하여 해당 subset들의 hash 값을 얻어내고, 가장 작은 값을 min hash로 결정하여 두 데이터의 min hash 일치여부를 판단하게 된다. 하지만 이미지의 embedding을 통해 이 방법을 사용하는건 어떻게 하는 건지 이해가 필요하다. (subset을 만드는건가? 만든다면 어떻게 만드는가?)
자세한 내용은 이 블로그에서 친절하게 다루고 있다.
Hierarchical Navigable Small World(HNSW)
여러분이 여행을 출발한다. Pasadena라는 곳을 가고 싶은데 어디에 있는지 모르겠다. 물론 이 지명은 세계 곳곳에 있을 수 있지만 그 중 한 곳을 골라보자.
예를 들어1200 E California Blvd, Pasadena, CA 91125, United States라는 주소가 있다고 하자. 뒤에서부터 읽으면
United States-->CA-->91125-->Pasadena-->California Blvd-->1200 E이다.
이게 HNSW 알고리즘이 동작하는 방식이다.
1.Gallery에서 k개의 데이터를 sampling 한다.
2.그 중 거리가 가장 가까운 데이터를 기준으로 이웃을 조사한다. 이 때 거리를 d라고 하자.
3.해당 이웃들 중 d보다 가까운 거리의 데이터가 있으면 그 데이터를 선택하고 다시 2번으로 간다.
4.설정한 layer의 수 L번 만큼 hierachical하게 진행
이 방법은 L이 크면 클수록, 이웃을 지정하는 hop이 크면 클수록 시간이 오래 걸리지만 더 정확한 결과를 얻을 수 있다. 상황이 반대로 갈수록 global minima를 찾기 어렵다. 하지만 gallery의 사이즈 N이 커질수록 brute force보다 몇백배, 몇천배는 빠르게 검색할 수 있는 강력한 알고리즘이다.
조금 더 자세하게 설명한 블로그가 있으니 참고해도 좋겠다.
출처
https://medium.com/pytorch/image-similarity-search-in-pytorch-1a744cf3469
https://www.secmem.org/blog/2020/05/21/LSH/
https://brunch.co.kr/@kakao-it/300
