영화 데이터(장르, 연령등급, 러닝타임, 감독명) 크롤링
머신러닝 팀 프로젝트를 위한 첫 개인 임무는 특정 연도 국내 개봉작 Top 150 영화들의 제목을 기반으로 필요한 데이터를 네이버에서 크롤링하기였다.
특정 연도 국내개봉작 순위 수집
영화관입장권통합전상망에서 원하는 연도를 설정 후 엑셀파일로 다운
Top 150 데이터 불러오기
import pandas as pd
import numpy as np
movie2010 = pd.read_excel('2010.xlsx', header=4).head(150)
movie2011 = pd.read_excel('2011.xlsx', header=4).head(150)
movie2012 = pd.read_excel('2012.xlsx', header=4).head(150)
movie2012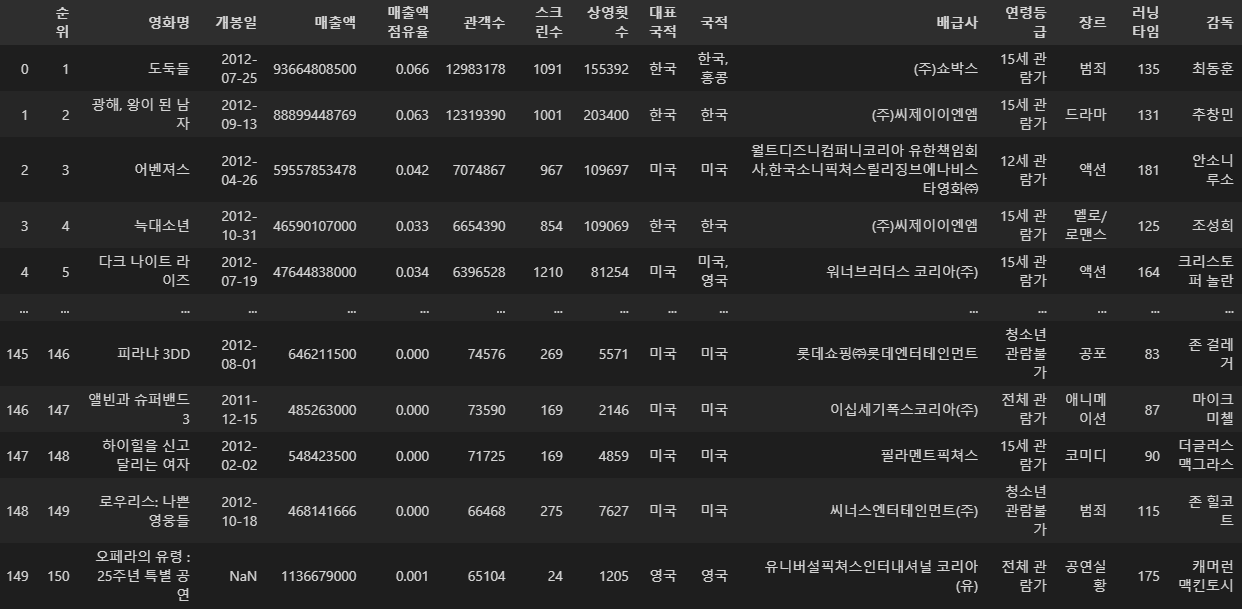
반복문을 통해 네이버 영화 데이터 크롤링
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
import re영화제목 리스트
movie2010_list = movie2010['영화명'].values.tolist()
movie2011_list = movie2011['영화명'].values.tolist()
movie2012_list = movie2012['영화명'].values.tolist()페이지 접근
chrome_options = webdriver.ChromeOptions()
url = 'https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=1&ie=utf8&query=%EC%98%81%ED%99%94'
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
driver.implicitly_wait(10)
driver.get(url)반복문 작성
rate_list = []
genre_list = []
runtime_list = []
producer_list = []
for movie in movie2010_list:
search_box = driver.find_element(By.ID, 'nx_query')
search_button = driver.find_element(By.XPATH, '//*[@id="nx_search_form"]/fieldset/button')
search_box.clear()
search_box.send_keys('영화 ', movie)
search_button.click()
time.sleep(0.2)
try:
info = driver.find_element(By.XPATH, '//*[@id="main_pack"]/div[2]/div[1]/div[3]/div/div/ul/li[2]/a')
info.click()
time.sleep(0.2)
# 한번에 영화검색이 안되면 제목 앞에 '영화' 제거 후 다시 검색
except:
try:
search_box = driver.find_element(By.ID, 'nx_query')
search_button = driver.find_element(By.XPATH, '//*[@id="nx_search_form"]/fieldset/button')
search_box.clear()
search_box.send_keys(movie)
search_button.click()
time.sleep(0.2)
info = driver.find_element(By.XPATH, '//*[@id="main_pack"]/div[2]/div[1]/div[3]/div/div/ul/li[2]/a')
info.click()
except:
# 기본정보 탭 찾을 수 없는 영화만 프린트 후 다음 영화로 넘어감: 엑셀에서 제목 수정 위한 프로세스
print(movie)
continue
# 기본정보 탭 클릭
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
# 관람 가능 연령
try:
rate = soup.select('div.detail_info > dl > div:nth-of-type(2) > dd')
rate_list.append(rate[0].get_text())
except IndexError:
rate_list.append(np.nan)
# 장르
try:
genre = soup.select('div.detail_info > dl > div:nth-of-type(3) > dd')
genre_list.append((genre[0].get_text().split(', ')[0]))
except IndexError:
genre_list.append(np.nan)
# 러닝타임
try:
runtime = soup.select('div.detail_info > dl > div:nth-of-type(5) > dd')
runtime_list.append(re.sub(r'[^0-9]', '', runtime[0].get_text()))
except IndexError:
runtime_list.append(np.nan)
# 감독/출연 탭 클릭
try:
producer_info = driver.find_element(By.XPATH, '//*[@id="main_pack"]/div[2]/div[1]/div[3]/div/div/ul/li[3]')
producer_info.click()
time.sleep(0.2)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
producer = soup.select_one('div.title_box > strong.name > span._text')
producer_list.append(producer.get_text())
except IndexError:
producer_list.append(np.nan)driver.quit()크롤링한 데이터 해당 컬럼에 삽입
movie2010['연령등급'] = rate_list
movie2010['장르'] = genre_list
movie2010['러닝타임'] = runtime_list
movie2010['감독'] = producer_list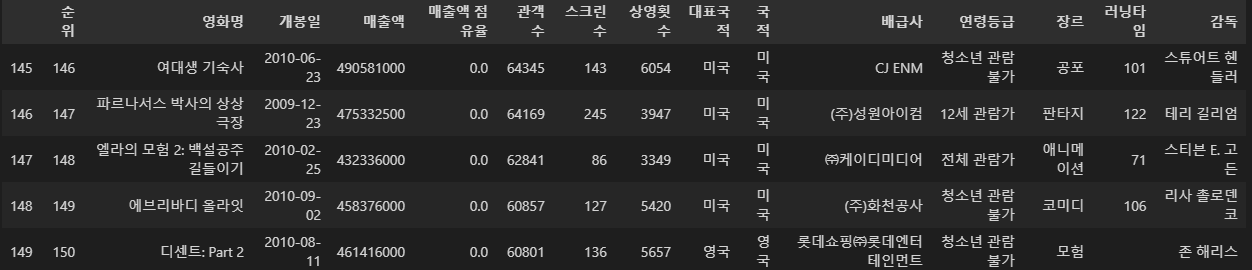

THEO's velog