
1. 문제정의
목표
- 환자데이터를 바탕으로 우방암여부를 판단하자!
- 딥러닝을 활용하여 이진분류를 진행해보자!
- sklearn에서 제공하는 breast_cancer데이터를 이용할것!
- 리아브러리 불어오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split2. 데이터 수집
data = load_breast_cancer()
data3. 데이터 전처리
- 데이터 확인
data.keys()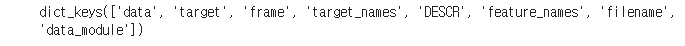
data: 문제데이터, 입력특성
target: 정답데이터
target_names: 정답데이터의 이름
feature_names: 특성의 이름(컬럼명)
DESCR: 데이터 설명
data['target_names']
0: malignant 악성
1: benign 양성
- 문제와 정답 추출하기
x = pd.DataFrame(data['data'], columns = data['feature_names'])
y = pd.DataFrame(data['target'])- train, test로 분리 (test_size = 0.25)
x_train, x_test, y_train, y_test = train_test_split (x,y, random_state =2024, test_size = 0.25)- 데이터 크기 확인
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)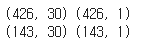
columns 수 = 30
4. 탐색적 데이터 분석
5. 모델 선택 및 하이퍼파리미터
- 도구 불러오기
from tensorflow.keras import Sequential
from tensorflow.keras.layers import InputLayer, Dense- 모델 구조 설계
# 뼈대
model = Sequential()
#입력층
model.add(InputLayer(input_shape = (30,)))
# 중간층 (다층구조) 1번째층 16개, 2번째층 8개 뉴런
model.add(Dense(units = 16, activation ='sigmoid'))
model.add(Dense(units = 8, activation = 'sigmoid'))
#출력층: 출력하고자하는 데이터의 형태를 지정
model.add(Dense(units =1))
model.compile(loss ='binary_crossentropy', optimizer = 'SGD', metrics =['accuracy'])- 오차: 이진분류 > binary_crossentropy
- 평가방법 분류: 정확도/accuracy
- 회귀: loss = mean_squared_error metrics = mse
6. 학습
h1 = model.fit(x_train, y_train, validation_split = 0.2, epochs = 20)7. 평가 및 예측
model.evaluate(x_test, y_test)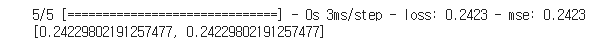
- loss 그래프 보여주기
h1.history['loss']
plt.figure(figsize= (10,5))
plt.plot(h1.history['loss'],label = 'train_loss')
plt.plot(h1.history['val_loss'], label = 'validation_loss')
plt.legend()
plt.show()

열심히 공부합시다! The best is yet to come! 💜