목표
- 손글씨 데이터를 분류하는 딥러닝 모델을 설계해보자!
- 다중분류 딥러닝을 연습해보자!
# 기본라이브러리불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# keras 에서 제공해주는 손글씨 데이터 불러오기
from tensorflow.keras.datasets import mnist# 내부적으로 훈련용데이터, 테스트용 데이토로 구분에서 담겨있음
# 문제와 정답도 나눠어있음
(x_train, y_train),(x_test, y_test)=mnist.load_data()#데이터 크기 확인
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
# 데이터 확인
# 픽셀: 사진에 정보를 가지는 단위
# 특성의 개수?
# 분류, 회귀?
# 중복되지 않는 유일한 값 출력
np.unique(y_train)
# 10위 클래스를 가지는 다중분류
#0~9 까지의 손글씨 데이터
# 손글씨 데이터 확인
plt.imshow(x_train[999], cmap = 'Blues')
# x_train[999]
# 흑백사진 데이터: 얼마나 검증색인지 정도를 숫자로 가짐 (0~255)
# 0: 검정색, 255: 횐색
# matplotlib 에서 기본 색상팔레트가 노란색, 흑백으로 바꿔주고 싶으면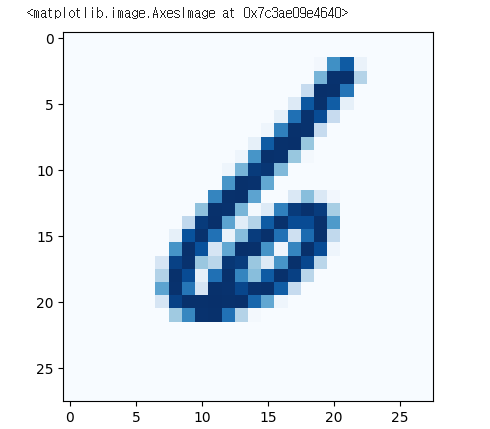
MLP 모델링 (Multi Layer Perceptron) 다층퍼셉트론
입력층위 구조 (28*28 2차원 데이터,출력층의 구조 고려 (다주분류)
학습능력을 위한 중간층의 깊이 고려
loss, optimizer (최적화일고리즘)다중분류에 밎게 설정
학습결과 시각화
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, InputLayer, Flatten
# Flatten: 2차원의 사진데이터를 1차원으로 펴현해주기위한 클래스
# 신형모델 분석을 위해 1차원으로 변경해주어야한다 # 1. 신경망 델 설계
# 뼈대
model = Sequential()
# 입력층 (28*28 차원데이터)
model.add(InputLayer(input_shape = (28,28)))
# 중간층(인닉층),첫번쨰 16, 두번째 8
model.add(Flatten()) # 입력받은 2차원의 사진데이터를 1차원으로 병경
model.add(Dense(units = 16, activation ='sigmoid'))
model.add(Dense(units = 8, activation = 'sigmoid'))
# 출력층 (다중분류 > 틀래스 10개)
model.add(Dense(units =10, activation = 'softmax'))
# 다중분류: 클래스의 개수만큼의 확률겂을 필요로 한다
# 0번 손글씨일 확률 ~~ 9변 손글씨일 확률 까지 총 10개의 확률값이 출력되어야한다!
# 다중분류의 활성화함수: softmax (클래스 개수만큼위 확률겂을 총함 1로 변환해주는 함수)
# 그중 가장 높은 확ㄹ률의 킁애슬르 정답데이터로 예측해나가는 원리출력할 때 필요한 함수 (softmax):
다중분류에서 레이블 값에 대한 각 퍼셉트론의 예측 확률위 합을 1로 설정 sigmoid에 비해 예측 오차의 평균을 줄어주는 효과

방법1:
# 방법 2 가지
# 방법1: 정답데이터 (y_train)의 형태를 10개의 확률값으로 변경하기
from tensorflow.keras.utils import to_categorical
# 범주형데이터(정답)확률값으로 변경해주는 역할
y_train_onehot = to_categorical(y_train)
y_train_onehot[1]
# 마치 원하는코딩을 하듯이 확룰값으로 변경해준다~
# 5일 확률 100%, 나머지는 0%
model.compile(loss = 'categorical_crossentropy', # 다중분류: categorical_crossentropy
optimizer = 'SGD', metrics = ['accuracy'])학습:
h1 = model.fit(x_train,y_train_onehot, validation_split=0.2, epochs = 20)방법2:
#방법2: loss함수를 spare_categorical_crossentropy변경
# 1. 신경망 델 설계
# 뼈대
model = Sequential()
# 입력층 (28*28 차원데이터)
model.add(InputLayer(input_shape = (28,28)))
# 중간층(인닉층),첫번쨰 16, 두번째 8
model.add(Flatten()) # 입력받은 2차원의 사진데이터를 1차원으로 병경
model.add(Dense(units = 16, activation ='sigmoid'))
model.add(Dense(units = 8, activation = 'sigmoid'))
# 출력층 (다중분류 > 틀래스 10개)
model.add(Dense(units =10, activation = 'softmax'))
model.compile(loss ='sparse_categorical_crossentropy',
optimizer = 'SGD',
metrics = ['accuracy'])
# 스스로 내부에서 범주값을 확률으로 변경하여 오차를 계산한다- 학습
h1 = model.fit(x_train,y_train, validation_split=0.2, epochs = 20)평가
model.evaluate(x_test, y_test)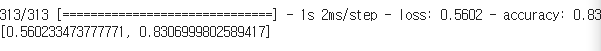
시각화
h1.history['loss']plt.figure(figsize= (10,5))
plt.plot(h1.history['loss'],label = 'train_loss')
plt.plot(h1.history['val_loss'], label = 'validation_loss')
plt.legend()
plt.show()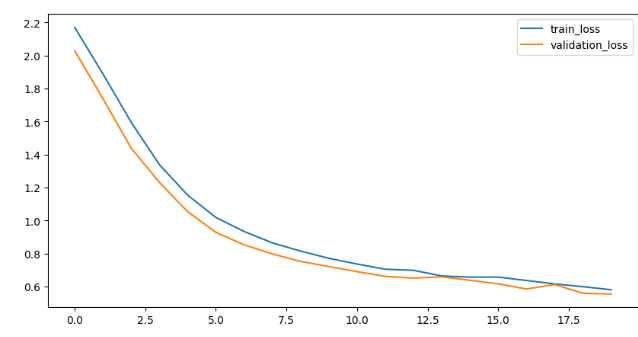

열심히 공부합시다! The best is yet to come! 💜