1. 문제정의
credit 데이터를 사용해서 좋/나쁜 손님 예측해보기 predict if an applicant is 'good' or 'bad' client
2. 데이터 수집
kaggle에 train, test data download
# 필요한 라이브러리 불러오기
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, f1_score, roc_auc_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn import svm
from sklearn.ensemble import RandomForestClassifierdata = pd.read_csv('/kaggle/input/credit-card-approval-98/application_record.csv', encoding = 'utf-8')
record = pd.read_csv('/kaggle/input/credit-card-approval-98/credit_record.csv', encoding ='utf-8')for i in data.columns:
if data[i].dtype == 'object':
cate = data[i].unique()
print(f'{i}\n {cate}({len(cate)})개')
print('-----------------------------')CODE_GENDER
'M' 'F'개
FLAG_OWN_CAR
'Y' 'N'개
FLAG_OWN_REALTY
'Y' 'N'개
NAME_INCOME_TYPE
'Working' 'Commercial associate' 'Pensioner' 'State servant' 'Student'개
NAME_EDUCATION_TYPE
['Higher education' 'Secondary / secondary special' 'Incomplete higher''Lower secondary' 'Academic degree'](5)개
NAME_FAMILY_STATUS
'Civil marriage' 'Married' 'Single / not married' 'Separated' 'Widow'개
NAME_HOUSING_TYPE
['Rented apartment' 'House / apartment' 'Municipal apartment''With parents' 'Co-op apartment' 'Office apartment'](6)개
for i in record.columns:
if record[i].dtype == 'object':
cate1 = record[i].unique()
print(f'{i}\n {cate1}({len(cate1)})개')
print('-----------------------------')STATUS
'X' '0' 'C' '1' '2' '3' '4' '5'개
# Users have potential risks (overdue > 1 month), marked as 1, else marked as 0 record['risk'] = None record['risk'][record['STATUS']=='2']='YES' record['risk'][record['STATUS']=='3']='YES' record['risk'][record['STATUS']=='4']='YES' record['risk'][record['STATUS']=='5']='YES'# cpunt = id별로 데이터 cpunt = record.groupby('ID').count() cpunt
MONTHS_BALANCE STATUS risk
ID
5001711 4 4 0
5001712 19 19 0
5001713 22 22 0
5001714 15 15 0
5001715 60 60 0
... ... ... ...
5150482 18 18 0
5150483 18 18 0
5150484 13 13 0
5150485 2 2 0
5150487 30 30 0
45985 rows × 3 columns
cpunt ['risk'][cpunt['risk']>0]='YES'
cpunt ['risk'][cpunt['risk']==0]='NO'
cpunt = cpunt[['risk']]# data and cpunt have the same col 'ID' so how = inner
new_data = pd.merge(data, cpunt, how ='inner', on = 'ID')
new_data.head()ID CODE_GENDER FLAG_OWN_CAR FLAG_OWN_REALTY CNT_CHILDREN AMT_INCOME_TOTAL NAME_INCOME_TYPE NAME_EDUCATION_TYPE NAME_FAMILY_STATUS NAME_HOUSING_TYPE DAYS_BIRTH DAYS_EMPLOYED FLAG_MOBIL FLAG_WORK_PHONE FLAG_PHONE FLAG_EMAIL OCCUPATION_TYPE CNT_FAM_MEMBERS risk
0 5008804 M Y Y 0 427500.0 Working Higher education Civil marriage Rented apartment -12005 -4542 1 1 0 0 NaN 2.0 NO
1 5008805 M Y Y 0 427500.0 Working Higher education Civil marriage Rented apartment -12005 -4542 1 1 0 0 NaN 2.0 NO
2 5008806 M Y Y 0 112500.0 Working Secondary / secondary special Married House / apartment -21474 -1134 1 0 0 0 Security staff 2.0 NO
3 5008808 F N Y 0 270000.0 Commercial associate Secondary / secondary special Single / not married House / apartment -19110 -3051 1 0 1 1 Sales staff 1.0 NO
4 5008809 F N Y 0 270000.0 Commercial associate Secondary / secondary special Single / not married House / apartment -19110 -3051 1 0 1 1 Sales staff 1.0 NOnew_data['target'] =new_data['risk'] new_data.loc[new_data['target']=='YES','target']=1 new_data.loc[new_data['target']=='NO','target']=0y_train = new_data['target'] y_train
0 0
1 0
2 0
3 0
4 0
..
36452 1
36453 1
36454 1
36455 1
36456 1
Name: target, Length: 36457, dtype: objecttrain_data = new_data train_data.head()
ID CODE_GENDER FLAG_OWN_CAR FLAG_OWN_REALTY CNT_CHILDREN AMT_INCOME_TOTAL NAME_INCOME_TYPE NAME_EDUCATION_TYPE NAME_FAMILY_STATUS NAME_HOUSING_TYPE DAYS_BIRTH DAYS_EMPLOYED FLAG_MOBIL FLAG_WORK_PHONE FLAG_PHONE FLAG_EMAIL OCCUPATION_TYPE CNT_FAM_MEMBERS risk target
0 5008804 M Y Y 0 427500.0 Working Higher education Civil marriage Rented apartment -12005 -4542 1 1 0 0 NaN 2.0 NO 0
1 5008805 M Y Y 0 427500.0 Working Higher education Civil marriage Rented apartment -12005 -4542 1 1 0 0 NaN 2.0 NO 0
2 5008806 M Y Y 0 112500.0 Working Secondary / secondary special Married House / apartment -21474 -1134 1 0 0 0 Security staff 2.0 NO 0
3 5008808 F N Y 0 270000.0 Commercial associate Secondary / secondary special Single / not married House / apartment -19110 -3051 1 0 1 1 Sales staff 1.0 NO 0
4 5008809 F N Y 0 270000.0 Commercial associate Secondary / secondary special Single / not married House / apartment -19110 -3051 1 0 1 1 Sales staff 1.0 NO 0
train_data.rename(columns={'CODE_GENDER': 'gender',
'FLAG_OWN_CAR':'car',
'FLAG_OWN_REALTY':'property',
'CNT_CHILDREN':'childNum',
'AMT_INCOME_TOTAL':'income',
'NAME_INCOME_TYPE':'incType',
'NAME_EDUCATION_TYPE':'eduType',
'NAME_FAMILY_STATUS':'maritalStatus',
'NAME_HOUSING_TYPE':'houseType',
'FLAG_MOBIL':'mobil',
'FLAG_WORK_PHONE':'workphone',
'FLAG_PHONE':'phone',
'FLAG_EMAIL':'email',
'OCCUPATION_TYPE':'employStatus',
'CNT_FAM_MEMBERS':'famNum'}, inplace = True)
train_data.head()ID gender car property childNum income incType eduType maritalStatus houseType DAYS_BIRTH DAYS_EMPLOYED mobil workphone phone email employStatus famNum risk target
0 5008804 M Y Y 0 427500.0 Working Higher education Civil marriage Rented apartment -12005 -4542 1 1 0 0 NaN 2.0 NO 0
1 5008805 M Y Y 0 427500.0 Working Higher education Civil marriage Rented apartment -12005 -4542 1 1 0 0 NaN 2.0 NO 0
2 5008806 M Y Y 0 112500.0 Working Secondary / secondary special Married House / apartment -21474 -1134 1 0 0 0 Security staff 2.0 NO 0
3 5008808 F N Y 0 270000.0 Commercial associate Secondary / secondary special Single / not married House / apartment -19110 -3051 1 0 1 1 Sales staff 1.0 NO 0
4 5008809 F N Y 0 270000.0 Commercial associate Secondary / secondary special Single / not married House / apartment -19110 -3051 1 0 1 1 Sales staff 1.0 NO 0
train_data.dropna()
train_data = train_data.mask(train_data =='NULL').dropna()
train_data.head()
ID gender car property childNum income incType eduType maritalStatus houseType DAYS_BIRTH DAYS_EMPLOYED mobil workphone phone email employStatus famNum risk target
2 5008806 M Y Y 0 112500.0 Working Secondary / secondary special Married House / apartment -21474 -1134 1 0 0 0 Security staff 2.0 NO 0
3 5008808 F N Y 0 270000.0 Commercial associate Secondary / secondary special Single / not married House / apartment -19110 -3051 1 0 1 1 Sales staff 1.0 NO 0
4 5008809 F N Y 0 270000.0 Commercial associate Secondary / secondary special Single / not married House / apartment -19110 -3051 1 0 1 1 Sales staff 1.0 NO 0
5 5008810 F N Y 0 270000.0 Commercial associate Secondary / secondary special Single / not married House / apartment -19110 -3051 1 0 1 1 Sales staff 1.0 NO 0
6 5008811 F N Y 0 270000.0 Commercial associate Secondary / secondary special Single / not married House / apartment -19110 -3051 1 0 1 1 Sales staff 1.0 NO 0
train_data['famNum'].value_counts()
famNum2.0 12697
3.0 5216
1.0 4263
4.0 2576
5.0 307
6.0 51
7.0 18
15.0 3
9.0 2
20.0 1
Name: count, dtype: int64
train_data['famNum']=train_data['famNum'].astype(object)
train_data.loc[train_data['famNum']>=3,'famNum']='3more'
train_data['famNum']2 2.0
3 1.0
4 1.0
5 1.0
6 1.0
...
36452 2.0
36453 2.0
36454 2.0
36455 2.0
36456 1.0
Name: famNum, Length: 25134, dtype: objecttrain_data['famNum'].value_counts() famNum2.0 12697
3more 8174
1.0 4263
Name: count, dtype: int64
# income type
train_data.loc[train_data['incType']=='Pensioner', 'incType']='State servant'
train_data.loc[train_data['incType']=='Student', 'incType'] = 'State servant'
train_data['incType'].value_counts()incType
Working 15622
Commercial associate 7052
State servant 2460
Name: count, dtype: int64train_data.loc[train_data['eduType']=='Incomplete higher','eduType']=='Secondary / secondary special' train_data.loc[train_data['eduType']=='Academic degree','eduType']=='Higher education'
11797 False
11798 False
11799 False
11800 False
11801 False
11802 False
11803 False
11804 False
11805 False
11806 False
11807 False
11808 False
22888 False
22889 False
Name: eduType, dtype: booltrain_data['eduType'].value_counts()eduType
Secondary / secondary special 16808
Higher education 7132
Incomplete higher 993
Lower secondary 187
Academic degree 14
Name: count, dtype: int64train_data.loc[train_data['maritalStatus']=='Single / not married','maritalStatus']='not married' train_data.loc[train_data['maritalStatus']=='Civil marriage','maritalStatus']='married' train_data.loc[train_data['maritalStatus']=='Separated','maritalStatus']='not married' train_data.loc[train_data['maritalStatus']=='Widow','maritalStatus']='not married' train_data['maritalStatus'].value_counts()
maritalStatus
Married 17509
not married 5492
married 2133
Name: count, dtype: int64train_data.loc[train_data['maritalStatus']=='married','maritalStatus']='Married' train_data.loc[train_data['houseType']=='Municipal apartment','houseType']='House / apartment' train_data.loc[train_data['houseType']=='Office apartment','houseType']='House / apartment' train_data.loc[train_data['houseType']=='Co-op apartment','houseType']='House / apartment' train_data['houseType'].value_counts()train_data.loc[train_data['maritalStatus']=='married','maritalStatus']='Married' train_data.loc[train_data['houseType']=='Municipal apartment','houseType']='House / apartment' train_data.loc[train_data['houseType']=='Office apartment','houseType']='House / apartment' train_data.loc[train_data['houseType']=='Co-op apartment','houseType']='House / apartment' train_data['houseType'].value_counts()
houseType
House / apartment 23265
With parents 1430
Rented apartment 439
Name: count, dtype: int64
train_data.loc[train_data['employStatus']=='Core staff','employStatus']= 'officer staff'
train_data.loc[train_data['employStatus']=='Sales staff','employStatus']= 'officer staff'
train_data.loc[train_data['employStatus']=='Private service staff','employStatus']= 'officer staff'
train_data.loc[train_data['employStatus']=='Accountants','employStatus']= 'officer staff'
train_data.loc[train_data['employStatus']=='Medicine staff','employStatus']= 'officer staff'
train_data.loc[train_data['employStatus']=='Secretaries','employStatus']= 'officer staff'
train_data.loc[train_data['employStatus']=='HR staff','employStatus']= 'officer staff'
train_data.loc[train_data['employStatus']=='Realty agents','employStatus']= 'officer staff'
train_data.loc[train_data['employStatus']=='IT staff','employStatus']= 'officer staff'
train_data.loc[train_data['employStatus']=='Drivers','employStatus']= 'Laborers'
train_data.loc[train_data['employStatus']=='Cooking staff','employStatus']= 'Laborers'
train_data.loc[train_data['employStatus']=='Security staff','employStatus']= 'Laborers'
train_data.loc[train_data['employStatus']=='Cleaning staff','employStatus']= 'Laborers'
train_data.loc[train_data['employStatus']=='Waiters/barmen staff','employStatus']= 'Laborers'
train_data.loc[train_data['employStatus']=='Low-skill Laborers','employStatus']= 'Laborers'
train_data['employStatus'].value_counts()employStatus
Laborers 10496
officer staff 10243
Managers 3012
High skill tech staff 1383
Name: count, dtype: int64
시각화
importance features 찾기
sns.countplot(data = train_data, x= 'employStatus', hue ='target')
<Axes: xlabel='employStatus', ylabel='count'>
sns.countplot(data = train_data, x = 'maritalStatus', hue = 'target')
<Axes: xlabel='maritalStatus', ylabel='count'>
sns.countplot(data= train_data, x = 'houseType', hue = 'target')
<Axes: xlabel='houseType', ylabel='count'>
sns.countplot(data= train_data, x = 'eduType', hue = 'target')
<Axes: xlabel='eduType', ylabel='count'>
sns.countplot(data = train_data, x = 'incType', hue = 'target')
<Axes: xlabel='incType', ylabel='count'>
sns.countplot(data = train_data, x= 'famNum', hue = 'target')
<Axes: xlabel='famNum', ylabel='count'>train_data['gender'] = train_data['gender'].replace(['F','M'],[0,1])
train_data['property']= train_data['property'].replace(['Y','N'],[0,1])
train_data['car']= train_data['car'].replace(['Y','N'],[0,1])
train_data['incType'] = train_data['incType'].replace(['Working','Commercial associate','State servant'],[0,1,2])
train_data['eduType']= train_data['eduType'].replace(['Secondary / secondary special','Higher education','Incomplete higher','Lower secondary','Academic degree'],[0,1,2,3,4])
train_data['maritalStatus']=train_data['maritalStatus'].replace(['Married','not married'],[0,1])
train_data['houseType']=train_data['houseType'].replace(['House / apartment','With parents','Rented apartment'],[0,1,2])
train_data['employStatus']= train_data['employStatus'].replace(['Laborers','officer staff','Managers','High skill tech staff'],[0,1,2,3])
train_data['famNum']=train_data['famNum'].replace(['2.0','3more','1.0'],[0,1,2])
train_data['risk']=train_data['risk'].replace(['NO','YES'],[0,1])
categorical_feature = ['incType','eduType','maritalStatus','employStatus','houseType', 'famNum']
one_hot = pd.get_dummies(train_data[categorical_feature])
one_hot.shape
(25134, 6)
total =pd.concat([train_data, one_hot], axis =1)
total.shape
(25134, 26)
total.drop(categorical_feature,axis =1, inplace = True)
total.shape
(25134, 14)
X= pd.DataFrame(total)
y = pd.DataFrame(train_data['target'])
y=y.astype('int')
X_train, X_test, y_train, y_test = train_test_split(X,y,
test_size=0.3)
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X_train, y_train)
LogisticRegression
LogisticRegression()
pre_lr = lr.predict(X_test)
from sklearn.metrics import accuracy_score, confusion_matrix
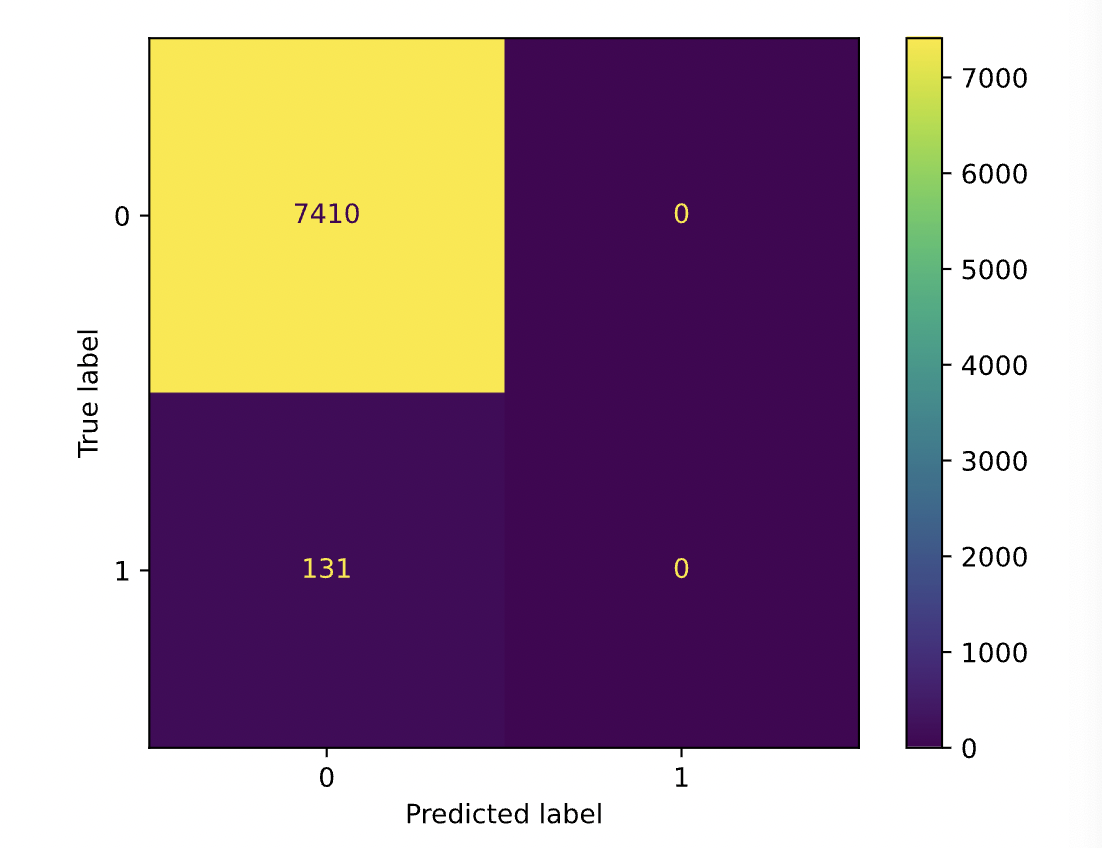
print('Accuracy Score is {:.5}'.format(accuracy_score(y_test, pre_lr)))
print(pd.DataFrame(confusion_matrix(y_test,pre_lr)))
Accuracy Score is 0.98263
0 1
0 7410 0
1 131 0
from sklearn.metrics import ConfusionMatrixDisplay
conf_mat = pd.DataFrame(confusion_matrix(y_test,pre_lr))
disp = ConfusionMatrixDisplay(confusion_matrix(y_test,pre_lr))
disp.plot()<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7ce621e7d8a0>