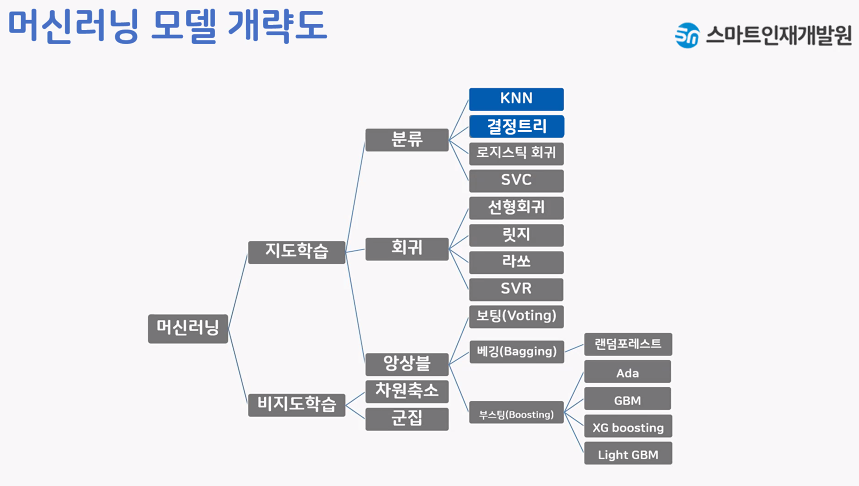
1. 문제정의
- 머신러닝을 사용해서 어떤 문제를 해결할것인지
- 식용버섯과 독버섯을 구분하자
2. 데이터수집
- 정의된 문제를 해결하기위한 데이터 수집
- 사이트에서 다운로드받기, 크롤링해서 찾기, DB에서 가져오기
3. 데이터 전처리
- 데이터 크기확인
- 결측치 확인
- 문제와 정답으로 나누기
- 통계치 확인하기
- 값을 숫자로 변경
> 레이블 인코딩, 원핫인코딩(많이 사용)
4. 탐색적 데이터 분석(생략 가능)
- 데이터를 더 자세하게 바라보자
- 통계기법 사용하기
- 그래프로 그리기
5. 모델 선택 및 하이퍼 파라미터 튜닝
- 모델 선택 : 목적과 데이터에 맞는 모델 고르기
- 하이퍼 파라미터 튜닝 : 모델 적합하게 수정하기
- train_test_split > 데이터 전처리가 완료된 후에 진행 > 5단계는 데이터 전처리가 완료된시점
- DecisionTree 모델 불러오기
6. 학습
- 5단계에서 만든 모델에 전처리 완료된 데이터로 학습하기
7. 예측 및 평가
- 모델의 성능을 평가
- 테스트 데이터로 예측하기
from character → to number
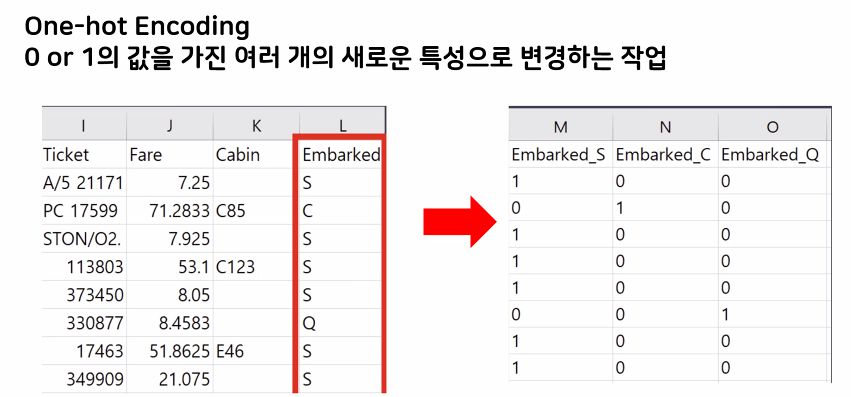
→ separate into embarked → then just one-hot encoding 0 or 1
but weakness is need to use many columns

- Import library 🍏**
# 필요한 library 불어오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split #훈련과 테스트용 셋트 분리
from sklearn.metrics import accuracy_score #평가를 진행할 때 정확도 측정
from sklearn.tree import DecisionTreeClassifier #결정트리모델 가져오기- 데이터 수집 🍊
- 정의된 문제를 해결하기위한 데이터 수집
- 사이트에서 다운로드받기, 쿨롤링해서 찾기, db에서 가져오기
#1. data를 로드하기
data = pd.read_csv('./data/mushroom.csv')
data- 데이터 전처리
- 데이터를 확인해보고 이상치, 경측치 파악후 수정하기
- 데이터마다 모델링하기 좋은 형태로 변환하기
# data크기 확인
data.shape#결측치 여부, 타입 확인
#결측치 > 삭제 or 채우기
# 타입 > 숫자형을로 변환 (글자는 안된다)
data.info()#문자와 답데이터로 분리
y = data['poisonous'] #답안
x = data.iloc[0:,1:] #문제
print(x)
print(y)print(x.shape)
print(y.shape)#통계치확인하기
#평균, 분산, 4분위수 > 숫자형 값에서 확인 가능
data.describe()# 답 데이터의 개수 구하기
# e(edible):식용버섯
#p(poison):독버섯
y.value_counts()값을 숫자로 변경 Label encoding 🍓🍅
- 단순 수치 값으로 mapping하는 작업
- 숫자 값의 크고 작음에 대한 특성으로 인래 예측성능이 떨어지는 경우가 발생할 수 있음
x['habitat'].unique()#데이터를 연경할 dictionary생성
habitat_dic = {
'u':0,
'g':1,
'm':2,
'd':3,
'p':4,
'w':5,
'l':6
}
x['habitat']=x['habitat'].map(habitat_dic)
x['habitat']원핫인코딩 One-hot-encoding 🥝🍇
- 단어를 표현하는 가장 자본적인 표현방법
- 특설을 세부작으로 나눠서 생삿할 수 있음
- 필요한 공간이 계속 늘어나 자장공간 측면에서는 비효율작인 방법
# get_dummies()메소드 활용
x_one_hot = pd.get_dummies(x)
x_one_hot.head()print("원본특상", list(x.columns))
print("원핫인코딩 이후 특성: ",list(x_one_hot.columns))- 탐색적 데이터 분석
- 데이터를 더 자세하게 바라보자
- 통계기법 사용하기
- 그래프로 그리기
- 모델 Modeling 🥛🧁🧃 선택 및 하이퍼 파라미터 튜닝
- 모델 선택 : 목적과 데이터에 맞는 모델 고르기
- hyper parameter: 모델 적합하게 수정하게
#훈련용 세트와 평가 세트로 분리
#x_one_hot, y
#train_test_split함수 사용
x_train,x_test,y_train,y_test=train_test_split(x_one_hot,y,
test_size = 0.3)
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)- decision Tree 모델 불러오기
#decisionTree 모델 불러오기
tree = DecisionTreeClassifier(max_depth = 3)- 학습
tree.fit(x_train,y_train)- 예측 및 평가 (Predict and judge)
pre = tree.predict(x_test)
preaccuracy_score(pre,y_test)print("예측 정확도: {0: .4f}".format(accuracy_score(pre,y_test)))
열심히 공부합시다! The best is yet to come! 💜