1. 데이터 수집
Import library
from sklearn.datasets import load_filesCall datasets from saved folder
train_data_url = 'data/aclImdb/train'
test_data_url = 'data/aclImdb/test'Review train data
reviews_train = load_files(train_data_url, shuffle = True)
reviews_trainreviews_test = load_files(test_data_url, shuffle = True)
reviews_testTo decide which key will be y_train
reviews_train.keys()# pos,neg
reviews_train['target_names']2. 데어터 전처리
- br태그제거
text_train = [txt.replace(b'<br />', b'') for txt in reviews_train['data']]
text_test = [txt.replace(b'<br />', b'') for txt in reviews_test['data']]- because the train and test size is big, in order to reduce process time,we choose train size: 5000 and test size: 2000
text_train = text_train[:5000]
text_test = text_test[:2000]
y_train = reviews_train['target'][:5000]
y_test = reviews_test['target'][:2000]3. 토큰화(CountVectorizer, LinearSVC)
from sklearn.pipeline import make_pipelineBow _ SVM이 합쳐진 pipeline 완성
pipe_model = make_pipeline(CountVectorizer(), LinearSVC())# pipeline학습하기
pipe_model.fit(text_train, y_train)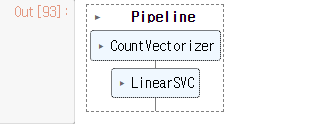
pipe_model.score(text_train, y_train)pipe_model.score(text_test, y_test)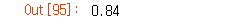
pipe_model.predict(reviews)from sklearn.model_selection import GridSearchCV#pipe model 이 가지고 있는 단계
pipe_model.steps
param = {
'countvectorizer__max_df' : [500,700,900],
'countvectorizer__min_df' : [20,40,60],
'countvectorizer__ngram_range': [(1,1),(1,2)],
'linearsvc__C':[0.5,1,1.5]
}
grid = GridSearchCV(pipe_model, param , cv = 5)grid.fit(text_train, y_train)
grid.best_score_
grid.best_params_
final_model.fit(text_train,y_train)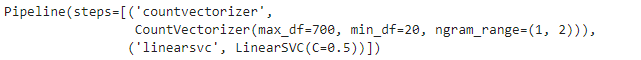
final_model.score(text_train, y_train)final_model.score(text_test,y_test)0.8305

열심히 공부합시다! The best is yet to come! 💜