
3.1 연결리스트란?
연결리스트를 이루는 노드는 데이터 필드와 링크 필드로 구성된다. 데이터 필드에는 데이터 값이 저장되고, 링크 필드에는 다음 노드를 가리키는 포인터가 저장된다. 우리가 연결리스트에서 첫번째 노드를 가리키는 포인터를 알고있다면, 포인터를 따라 순차적으로 연결리스트에 저장된 내용을 탐색할 수 있다. 그렇다면 마지막 노드의 링크 필드의 포인터는 무엇을 가리키는 것이 타당할까? 다음 노드가 존재하지 않고 어떠한 주소가 저장되어야 하므로 NULL로 설정하면 알맞다.
연결리스트의 경우 데이터를 새로 저장할 때마다 필요한 메모리 공간을 할당받는 동적 프로그래밍이 가능하다. 그리고 리스트와 다르게 데이터의 삽입/삭제가 간단한 편이다. 리스트의 경우 중간에 있는 데이터를 삽입/삭제하면 이후의 데이터를 모두 한 칸씩 밀거나 당기는 연산을 필요로 했다. 이 경우 데이터의 수가 증가하게 되면 매우 비효율적인 연산이 된다. 하지만 연결리스트의 경우 링크 필드의 포인터를 수정하는 것으로 문제를 해결할 수 있다.
물론 연결리스트가 장점만 가지는 것은 아니다. 만약 n번째 데이터를 찾으려면, index가 존재하지 않고 메모리 상에 흩어져 있는 데이터들이 포인터로 연결되어 있으므로 첫 번째 노드부터 순차적으로 탐색할 수 밖에 없다.
3.2 Pseudo code 구현
첫 번째 노드를 가리키는 포인터를 head로 정의한다.
초기 상태에는 head는 NULL값을 가진다.
첫 노드가 수정되어 head가 바뀌는 경우, head값을 바꿔주는 것을 고려해야 한다.
insert_first(head, item):
p <- malloc() // 동적 할당을 통해 새로운 노드 p 생성
if(p==NULL)
then error "OVERFLOW"
p->data <- item
p->link <- head // 맨 처음 추가되므로 현재의 head 값 저장
head <- p // head는 가장 앞선 노드를 가리켜야 하므로 p값으로 수정
return head
// 연결리스트의 중간에 노드를 삽입하기 위해선 이전 노드를 가리키는 포인터 pre가 필요하다.
// pre->link를 수정해 새로 할당한 노드를 가리키게 한다. 아래 이미지 참조.
insert(head, pre, item):
p <- malloc()
if(p==NULL)
then error "OVERFLOW"
p->data <- item
p->link <- pre->link
pre->link <- p
return head
delete_first(head):
if(head==NULL)
then error "UNDERFLOW"
removed <- head // removed가 첫 노드를 가리키도록 저장
head <- head->link // 첫 노드를 삭제할 것이므로 head를 두번째 노드를 가리키도록 수정
free(removed) // 동적 메모리 반환
return head
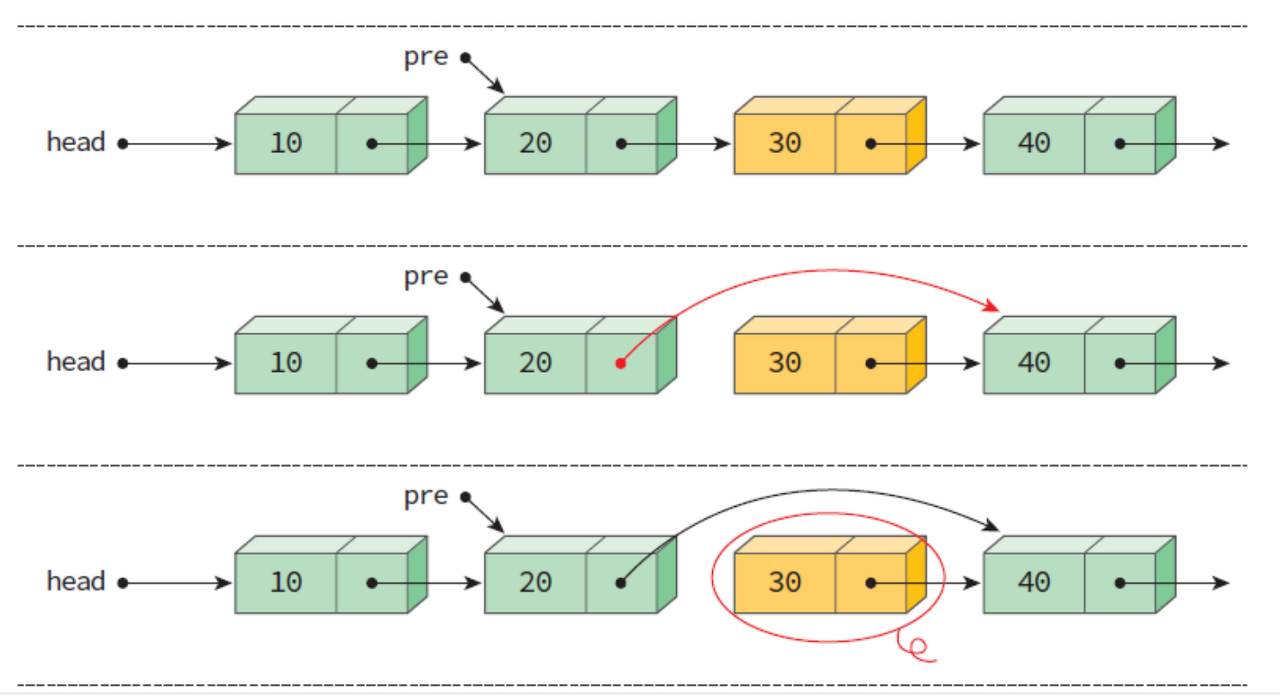
delete(head, pre):
if(head==NULL)
then error "UNDERFLOW"
removed <- pre->link
pre->link <- removed->link
free(removed)
return head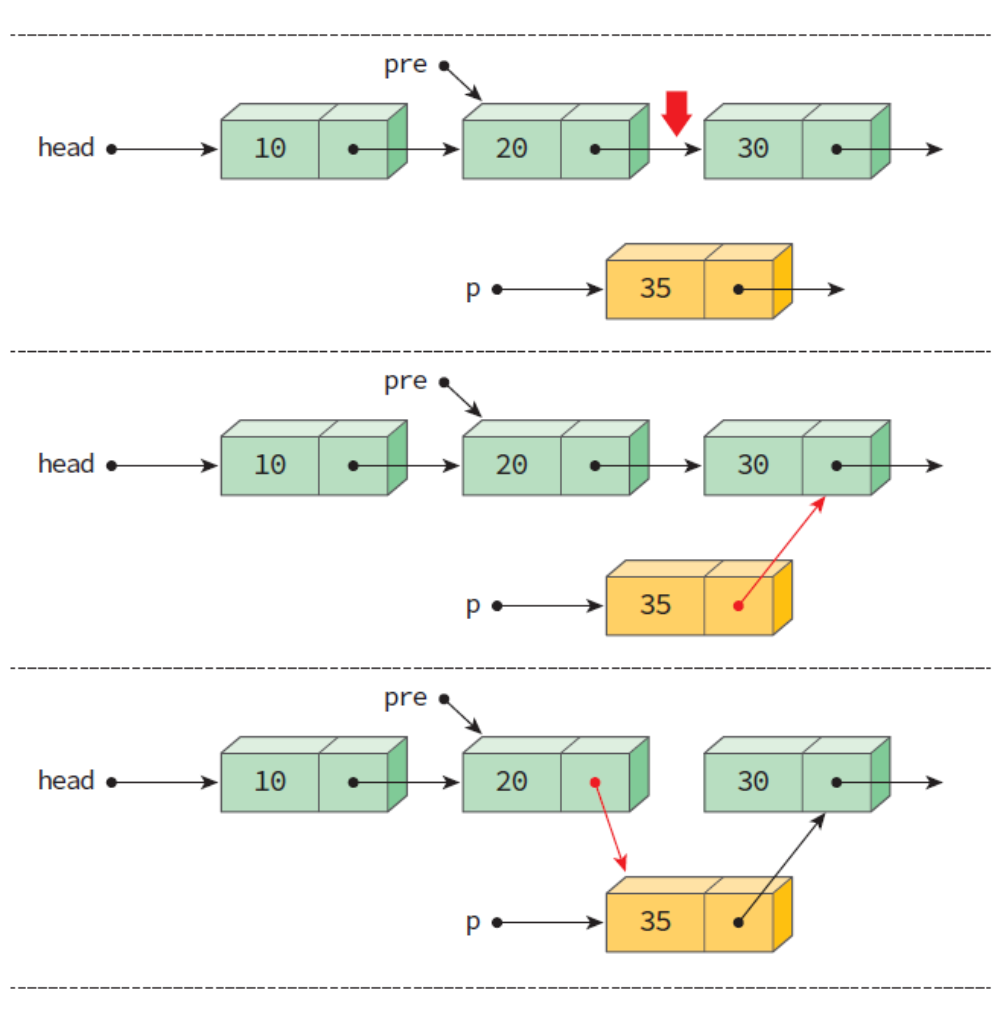
3.3 연결리스트 구현
#include <stdio.h>
#include <stdlib.h>
typedef int element;
// 노드의 정의
// 노드는 자기 자신을 가리킬 수 있는 포인터를 포함한 자기 참조 구조체로 정의됨.
typedef struct ListNode{
element data; // 데이터 필드
struct ListNode *link; // 링크 필드: 다음 노드의 주소 저장
} ListNode;
void error(char *message){
fprintf(stderr, "%s\n", message);
exit(1);
}
ListNode* insert_first(ListNode *head, int value){
// malloc 함수를 통해 동적 할당
ListNode *p = (ListNode *)malloc(sizeof(ListNode));
// malloc 함수가 동적 할당에 실패하면 NULL값 반환
// 오류 처리
if(p == NULL){
error("MEMORY ALLOCATION FAIL");
}
p->data = value;
p->link = head;
head = p;
return head;
}
// pre 뒤에 새로운 노드 삽입
ListNode* insert(ListNode *head, ListNode *pre, int value){
ListNode *p = (ListNode *)malloc(sizeof(ListNode));
if(p == NULL){
error("MEMORY ALLOCATION FAIL");
}
p->data = value;
p->link = pre->link;
pre->link = p;
return head;
}
ListNode* delete_first(ListNode *head){
ListNode *removed;
if(head == NULL) return NULL; // 삭제할 노드가 없는 경우 head값인 NULL 반환
removed = head;
head = removed->link;
free(removed);
return head;
}
// pre 뒤에 노드 삭제
ListNode* delete(ListNode *head, ListNode *pre){
ListNode *removed;
removed = pre->link;
pre->link = removed->link;
free(removed);
return head;
}
void print_list(ListNode *head){
for(ListNode *p = head; p != NULL; p = p->link){
printf("%d->", p->data);
}
printf("NULL\n");
}
int main()
{
ListNode *head = NULL; // 초기 상태
for(int i = 0; i<5; i++){
head = insert_first(head, i);
print_list(head);
}
for(int i = 0; i<5; i++){
head = delete_first(head);
print_list(head);
}
return 0;
}-실행결과-
0->NULL
1->0->NULL
2->1->0->NULL
3->2->1->0->NULL
4->3->2->1->0->NULL
3->2->1->0->NULL
2->1->0->NULL
1->0->NULL
0->NULL
NULL3.4 연결리스트를 통한 스택 구현
스택에서는 top에 데이터를 삽입/삭제한다. 연결리스트를 통해 스택을 구현하려면 top을 head로 설정하는 것이 자연스럽다. 스택에서는 top에서만 연산이 일어나고, 연결리스트에서는 head가 가리키는 노드를 변경하는 것이 가장 쉽기 때문이다.
#include <stdio.h>
#include <stdlib.h>
typedef int element;
typedef struct StackNode{
element data;
struct StackNode *link;
} StackNode;
typedef struct{
StackNode *top;
} LinkedStackType;
// 초기화 함수
void init(LinkedStackType *s){
s->top = NULL;
}
// 공백 상태 검출 함수
int is_empty(LinkedStackType *s){
return (s->top == NULL);
}
// 삽입 함수
void push(LinkedStackType *s, element item){
StackNode *tmp = (StackNode *)malloc(sizeof(StackNode));
// 포화 상태일 경우 동적 할당에 실패
if(tmp == NULL){
fprintf(stderr, "OVERFLOW\n");
exit(1);
}
tmp->data = item;
tmp->link = s->top;
s->top = tmp;
}
// 삭제 함수
element pop(LinkedStackType *s){
if(is_empty(s)){
fprintf(stderr, "UNDERFLOW\n");
exit(1);
}
else{
StackNode *tmp = s->top;
s->top = tmp->link;
int data = tmp->data;
free(tmp);
return data;
}
}
// 출력 함수
void print_stack(LinkedStackType *s){
StackNode *p;
for(p = s->top; p != NULL; p = p->link){
printf("%d->", p->data);
}
printf("NULL\n");
}
int main(){
LinkedStackType *p;
init(p);
push(p, 1); print_stack(p);
push(p, 2); print_stack(p);
push(p, 3); print_stack(p);
pop(p); print_stack(p);
pop(p); print_stack(p);
pop(p); print_stack(p);
return 0;
}-실행결과-
1->NULL
2->1->NULL
3->2->1->NULL
2->1->NULL
1->NULL
NULL3.5 연결리스트를 통한 큐의 구현
큐에서는 front에서 데이터의 삭제, rear에서 데이터의 삽입 연산이 진행되므로 head를 front로 설정하고 포인터 변수 rear를 추가로 설정한다. 큐의 경우 삽입/삭제 함수가 생각할 여지가 있으므로 pseudo code를 작성해 이해해보자.
init(front):
front <- NULL
enqueue(front, rear, item):
tmp <- malloc()
if(tmp==NULL)
then error "OVERFLOW"
tmp->data <- item
tmp->link <- NULL // 마지막에 삽입되므로 tmp->link는 NULL
// generic case: rear->link에 tmp를 할당하고, rear<-tmp를 통해 rear가 마지막 노드를 가리키도록 함
// specific case: OVERFLOW는 위에서 정의하였으므로, 초기 상황을 가정해보자.
// 초기 상황에서는 새 노드를 만들어 front와 rear 모두 새 노드를 가리키도록 해야한다.
// 또한 rear->link도 정의할 수 없기 때문에 case를 나누어 처리하도록 하자.
if(front==NULL)
then front <- tmp
rear <- tmp
else rear->link <- tmp
rear <- tmp
dequeue(front, rear):
if(front==NULL)
then error "UNDERFLOW"
// generic case: tmp에 front를 할당한 후, front<-front->link로 head를 변경 이후 free(tmp)
// specific case: UNDEFLOW는 위에서 정의하였으므로, 노드가 하나 있는 큐를 생각해보자.
// front, rear가 한 노드를 가리키는 상황. generic case의 flow로 생각해보면 front가 NULL값을 가지고
// rear가 가리키는 노드의 메모리는 반환된 상태이다. case를 나누지 않아도 처리 가능하다.
tmp <- front
front <- front->link
data <- tmp->data
free(tmp)
return data
#include <stdio.h>
#include <stdlib.h>
typedef int element;
typedef struct QueueNode{
element data;
struct QueueNode *link;
} QueueNode;
typedef struct{
QueueNode *front, *rear;
} LinkedQueueType;
// 초기화 함수
void init(LinkedQueueType *q){
q->front = NULL;
}
// 공백 상태 검출 함수
int is_empty(LinkedQueueType *q){
return (q->front == NULL);
}
// 삽입 함수
void enqueue(LinkedQueueType *q, element item){
QueueNode *tmp = (QueueNode*)malloc(sizeof(QueueNode));
// 포화 상태일 경우 동적 할당에 실패
if(tmp == NULL){
fprintf(stderr, "OVERFLOW\n");
exit(1);
}
tmp->data = item;
tmp->link = NULL;
if(is_empty(q)){
q->front = tmp;
q->rear = tmp;
}
// 공백 상태인 큐에 첫 노드가 추가되면 포인터 front = rear = tmp
// 초기 상황에서 노드가 존재하지 않고 front만 NULL값을 갖는 상황이므로 rear->link가 정의되지 않음
else{
q->rear->link = tmp;
q->rear = tmp;
}
}
// 삭제 함수
element dequeue(LinkedQueueType *q){
if(is_empty(q)){
fprintf(stderr, "UNDERFLOW\n");
exit(1);
}
else{
QueueNode *tmp = q->front;
q->front = q->front->link;
int data = tmp->data;
free(tmp);
return data;
}
}
// 출력 함수
void print_queue(LinkedQueueType *q){
QueueNode *p;
for(p = q->front; p != NULL; p = p->link){
printf("%d->", p->data);
}
printf("NULL\n");
}
int main(){
LinkedQueueType *p;
init(p);
enqueue(p, 1); print_queue(p);
enqueue(p, 2); print_queue(p);
enqueue(p, 3); print_queue(p);
dequeue(p); print_queue(p);
dequeue(p); print_queue(p);
dequeue(p); print_queue(p);
return 0;
}-실행결과-
1->NULL
1->2->NULL
1->2->3->NULL
2->3->NULL
3->NULL
NULLLinked List 부터는 포인터를 많이 활용하고 삽입/삭제 연산 시 여러 포인터 값을 순서에 맞게 변경해야 한다. 머리 속에서 구현하려고 하면 자칫 실수할 수 있으니 헷갈리는 부분은 그림으로 그려가며 차근차근 학습하는 것이 중요하다.
