
6.1 해싱이란?
해싱은 탐색을 위한 알고리즘으로 최선의 경우 의 시간 안에 탐색을 가능하게 해준다. 해싱의 기본적인 아이디어는 정의역에 해당하는 키(key) 값을 해시 함수에 넣어 나온 값을 활용해 정보가 담겨 있는 해시 테이블의 index에 직접 접근할 수 있도록 하는 것이다.
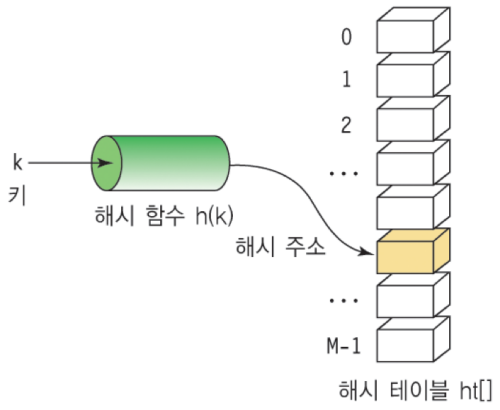
최선의 경우를 고려해보자. 해시 테이블의 크기가 충분히 크고 모든 키 값에 대한 해시 함수의 계산 값이 다르다면 각 해시 주소는 하나만의 키와 연결된다. 그렇다면 원하는 정보를 탐색할 때, 키 값을 통해 의 시간에 탐색을 마칠 수 있다.
하지만 실제의 경우, 정의역인 키 값의 범위가 매우 크므로 하나의 키당 하나의 해시 테이블 공간을 할당할 수 없다. 인 경우가 발생하게 되는 것이다. 이를 충돌(collision)이라고 한다. 충돌이 발생하게 되면 두번째 삽입되는 데이터는 첫번째 데이터가 이미 삽입돼 있기 때문에 해당 주소를 사용할 수 없다. 이후에 이 문제를 연결리스트를 통해 해결하는 Chaining에 대해 소개하겠다.
◼ 해시 함수
해싱 과정 중 충돌이 많이 발생하게 되면 한 주소에 많은 양의 데이터가 쌓이고, 이는 곧 성능의 저하로 이어진다. 이러한 문제를 방지하기 위해 적합한 해시 함수를 사용할 필요성이 있다.
- 좋은 해시 함수의 조건
1. 계산이 빨라야 한다.
2. 충돌이 적어야 한다.
해시 함수로 보통 키 값(k)을 해시 테이블의 크기(M)으로 나눈 나머지 값을 사용한다. 이때 해시 테이블의 크기를 소수로 정하였을 때, 해시 함수 값을 고르게 분포시킨다. 이후에 이를 실제 데이터에 적용해 충돌 횟수에 대해 생각해보자.
6.2 Chaining
Chaining은 한 해시 값에 여러 키가 할당될 때, 키들을 연결리스트를 통해 해시 값에 연결한다. 이때 충돌이 많이 발생하지 않는다면 해시 값을 계산해 테이블 index로 이동 후 연결리스트를 따라가며 빠르게 키를 탐색할 수 있다.
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
// 테이블 크기 소수로 설정
#define TABLE_SIZE 13
typedef struct HashNode{
int data;
struct HashNode* link;
} HashNode;
int hash(int key){
return key % TABLE_SIZE;
}
HashNode *hash_table[TABLE_SIZE];
// 삽입 함수
void add(int key){
// hash 값 계산
int hash_value = hash(key);
HashNode *p = hash_table[hash_value];
// 링크를 직접 바꿔 주기 위해 이중포인터에 hash_table 주소 할당
HashNode **q = &hash_table[hash_value];
HashNode *r = (HashNode *)malloc(sizeof(HashNode));
if(r == NULL){
fprintf(stderr, "MEMORY ALLOCATION FAIL");
exit(1);
}
else{
r->data = key;
// linked list 가장 앞에 새로운 노드 추가
r->link = p;
*q = r;
}
}
// 탐색 함수
void search(int key){
HashNode *p = hash_table[hash(key)];
int com_num = 0;
for(; p; p=p->link){
com_num++;
if(key == p->data){
break;
}
}
if(p == NULL){
printf("Couldn't find the name.\n");
printf("%d key comparisons were made.\n", com_num);
}
else{
printf("%d was found.\n", key);
printf("%d key comparisons were made.\n", com_num);
}
}
// 삭제 함수
void delete(int key){
HashNode *p = hash_table[hash(key)];
HashNode **q = &hash_table[hash(key)];
int com_num = 0;
while(p){
com_num++;
if(key != p->data){
q = &(p->link);
p = p->link;
}
else break;
}
if(p == NULL){
printf("Couldn't find the name.\n");
printf("%d key comparisons were made.\n", com_num);
}
else{
*q = p->link;
free(p);
printf("The name was successfully deleted!\n");
printf("%d key comparisons were made.\n", com_num);
}
}
// hash_table 출력 함수
void print_chain(HashNode *ht[]){
HashNode *p;
for(int i = 0; i<TABLE_SIZE; i++){
printf("[%d]->", i);
for(p = ht[i]; p; p=p->link){
printf("%d->", p->data);
}
printf("\n");
}
}
int main(){
srand(time(NULL)); // 시드를 현재 시간으로 설정하여 매번 다른 난수 생성
// 50개의 난수 생성하여 해시 테이블에 추가
for (int i = 0; i < 50; i++) {
int random_key = rand() % 1000;
add(random_key);
}
print_chain(hash_table);
return 0;
}-실행결과-
[0]->169->364->962->325->
[1]->599->235->118->976->
[2]->964->548->509->
[3]->939->601->
[4]->446->407->849->
[5]->564->239->551->304->174->
[6]->552->396->266->58->
[7]->293->722->
[8]->346->671->944->73->957->918->242->463->
[9]->438->919->230->
[10]->361->400->88->426->
[11]->869->583->544->362->
[12]->350->51->25->974->6.3 성능 분석
해시 테이블에 저장할 데이터:
http://ftp.cs.stanford.edu/pub/sgb/words.dat
해시 테이블의 크기 M 값에 따라 충돌 횟수를 비교하고, 각 단어를 1회씩 검색하였을 때 수행되는 비교 연산의 횟수를 구해보자.
각 해시 값에서 충돌 횟수는 (해시 값에 해당하는 노드의 수 - 1)로 정의 하였다.
words.dat 파일에는 총 5757개의 5글자 단어가 저장되어 있다. M2, M4, M6는 소수이다.
M1: 7000
M2: 6997
M3: 12000
M4: 11117
M5: 22000
M6: 22307
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define N 5757
#define HASH_PRIME 7000
//M1: 7000, M2: 6997, M3: 12000, M4: 11117, M5: 22000, M6: 22307
// 해시 함수
int hash(char key[5])
{
int i;
long long x;
x=0;
for (i=0; i<4; i++) {
x=x+key[i];
x=x<<8;
}
x=x+key[4];
return x%HASH_PRIME;
}
int main() {
FILE *fp; // file pointer
char words[N][6];
// 해시 테이블, 충돌 횟수, 비교 횟수 초기화
int hash_table[HASH_PRIME] = {0};
int collision = 0, comparison = 0;
// 오류 처리
if ((fp=fopen("words.dat", "r")) == NULL)
printf("Couldn't read file.\n");
// 단어 포함하지 않은 첫 4줄 스킵
for (int i=1; i<=4; i++) {
while (getc(f)!='\n');
}
// 5757개 단어 words 리스트에 저장
for (i=0; i<N; i++) {
fscanf(f, "%5c", words[i]);
while (getc(f)!='\n');
}
// 파일 닫기
fclose(fp);
// 충돌 횟수 계산
for(int i=0; i<N; i++){
if(hash_table[hash(words[i])]==0){
hash_table[hash(words[i])] = 1;
}
else collision++;
}
// 해시 테이블 초기화
for(int i=0; i<HASH_PRIME; i++){
hash_table[i] = 0;
}
// 비교 횟수 계산
for(int i=0; i<N; i++){
hash_table[hash(words[i])]++;
comparison += hash_table[hash(words[i])];
}
printf("collision: %d\n", collision);
printf("comparison: %d\n", comparison);
return 0;
}-실행결과-
M1: collision: 2305
comparison: 9356
M2: collision: 1821
comparison: 8115
M3: collision: 2733
comparison: 11633
M4: collision: 1235
comparison: 7216
M5: collision: 1359
comparison: 7550
M6: collision: 655
comparison: 6469◼ 결과 분석
HASH_PRIME 값을 합성수로 사용할 경우, 비슷한 크기의 소수에 비해 충돌이 많이 발생한다는 것을 확인할 수 있었다. 특히 (M3,M4), (M5,M6)를 비교했을 때 합성수의 경우가 충돌 수가 약 2배 많게 나타났다. HASH_PRIME 값이 커질수록 충돌 수가 적어지는 경향이 나타났지만, M3에서 예외적으로 M1에 비해 충돌이 더 많이 일어났다.
5757개의 단어를 해시에 할당했기 때문에 만약 해시 값이 중복되는 경우 없이 최대 1개씩 할당된다면 HASH_PRIME 값에 상관없이 비교 횟수는 5757이 나온다. 그러므로 각 HASH_PRIME에 따른 비교 횟수와 5757의 차이를 계산해 같은 해시 값이 중복된 경우가 많은 지, 적은 지 상대적인 판단이 가능하다. M4의 경우 차이가 1459로 나타났다. 그렇다면 충돌이 많이 발생한 M1과 M3의 경우는 어떨까? M1은 차이가 3599, M3는 차이가 5876으로 나타나 M3의 경우 최선의 경우보다 2배 넘도록 비교 연산을 수행해주어야 했다.
HASH_PRIME 값에 따라 연산의 효율성이 결정되므로 사용하려는 데이터의 크기, 소수의 여부 등을 고려하여 적절한 HASH_PRIME 값을 선정할 필요가 있다.
