
5.1 우선순위 큐와 히프란?
◼ 우선순위 큐는 데이터들이 우선순위를 가지고 있어 우선순위가 높은 데이터부터 처리되는 자료구조이다. 우선순위 큐는 컴퓨터의 여러분야에 이용된다. 대표적으로 운영체제에서의 작업 스케줄링을 예로 들 수 있다. 우리가 여러 프로세서를 동시에 사용할 때 우선순위 큐를 통해 프로세스의 우선순위를 스케줄링한다.
연결리스트와 히프를 통한 우선순위 큐의 구현을 비교해보도록 하겠다.
- 연결리스트를 통한 구현:
새로운 노드가 삽입될 때 우선순위 값 비교를 하며 삽입 위치를 찾는다. 그러므로 시간복잡도
노드가 삭제될 때 우선순위가 가장 높은 첫번째 노드가 삭제되므로 시간복잡도
N번의 삽입과 삭제가 일어날 때 시간복잡도는
- 히프를 통한 구현:
삽입의 경우 시간복잡도
삭제의 경우 시간복잡도
N번의 삽입과 삭제가 일어날 때 시간복잡도는
아직 히프에 대해 학습하진 않았지만 히프를 사용한 방법이 연결리스트를 통한 구현에 비해 굉장히 빠르다는 것을 알 수 있다. 본격적으로 히프에 대해 알아보자.
◼ 히프는 특정 조건을 만족시키는 완전 이진 트리이다.
max heap: 부모 노드의 키 값이 자식 노드의 키 값보다 크거나 같은 완전 이진 트리
min heap: 부모 노드의 키 값이 자식 노드의 키 값보다 작거나 같은 완전 이진 트리
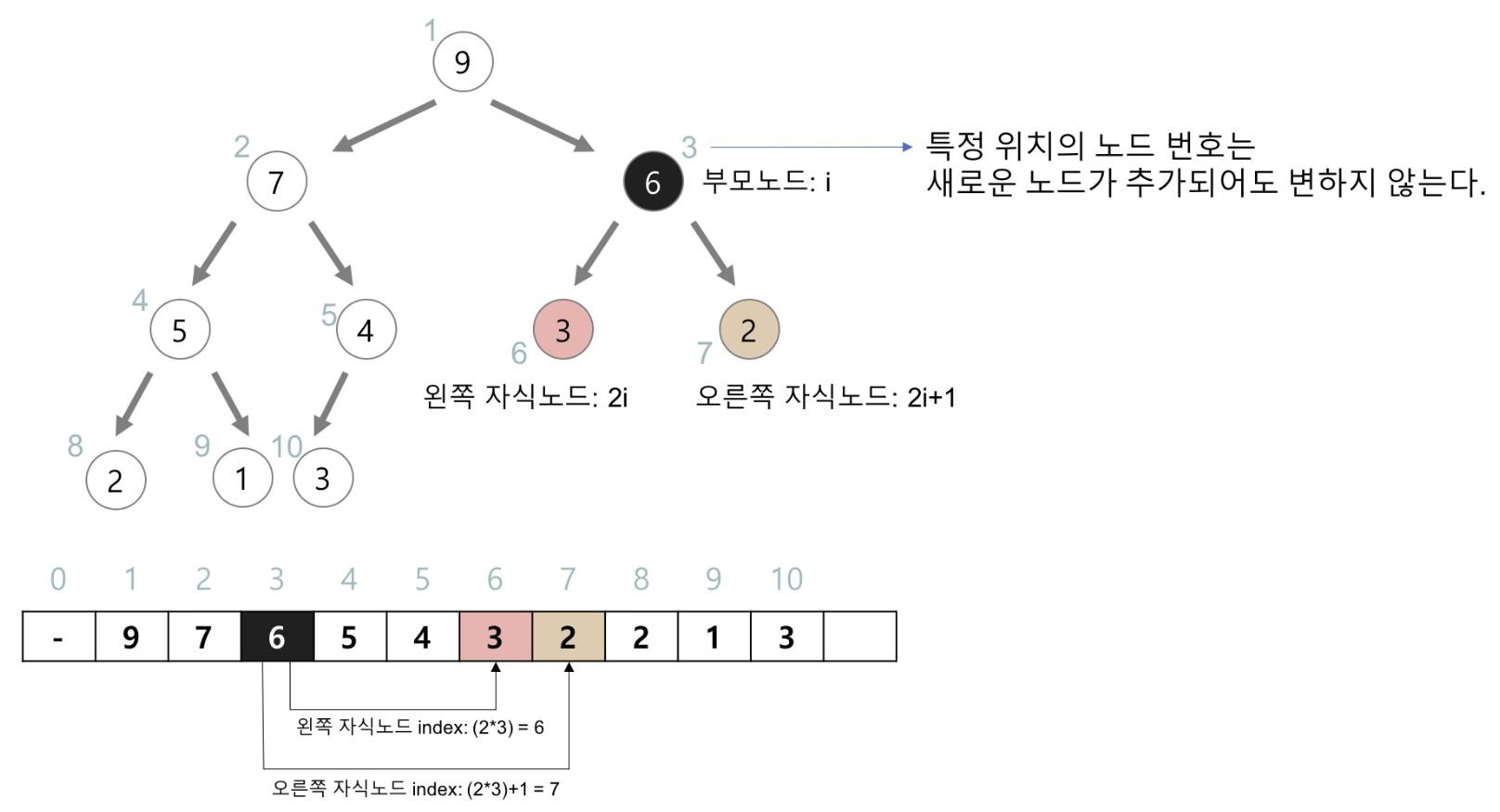
히프는 완전 이진 트리이므로 각 노드에 index를 부여할 수 있다. root 노드의 index를 1로 설정하고(계산 편의성) 순서대로 index를 부여한다. 깊이 N인 경우 에서 번째 노드를 포함한다. 예를 들어 1245번째 노드는 깊이 10의 222번째 노드임을 계산할 수 있다.
노드의 index를 통해 자식 노드, 부모 노드의 index 값을 계산할 수 있다.
히프의 각 노드에 index를 부여했기 때문에 히프를 배열로 표현 가능하다. 이 배열에 위의 공식을 적용해 수평적으로 표현된 배열에서 부모나 자식 노드에 접근 가능하다.
5.2 Heapify
히프의 삽입, 삭제 연산과 히프의 조건이 깨졌을 때 재구조화를 통해 히프를 유지하는 Heapify에 대해 알아보고, 시간복잡도를 고려해보자.
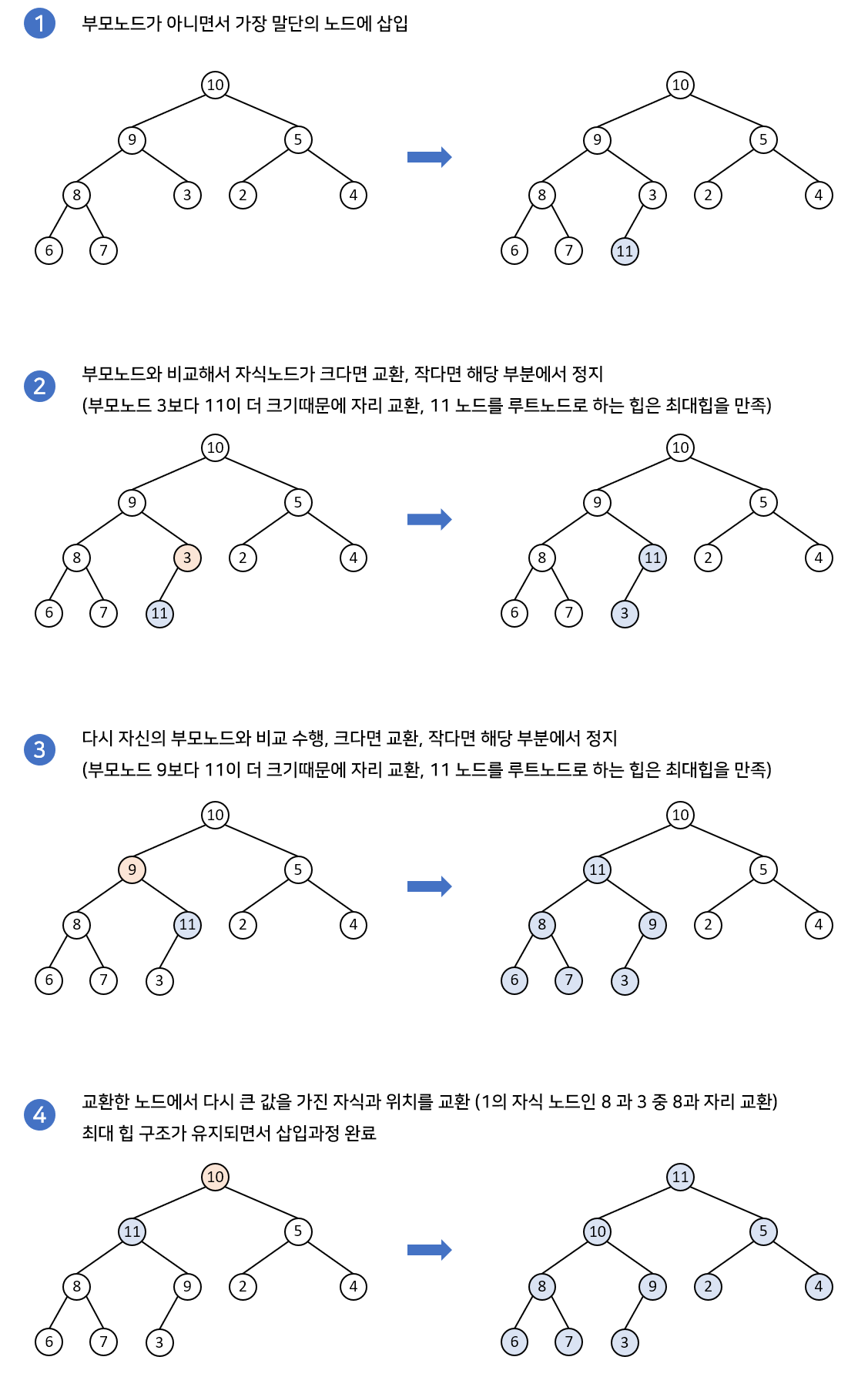
- 삽입 연산
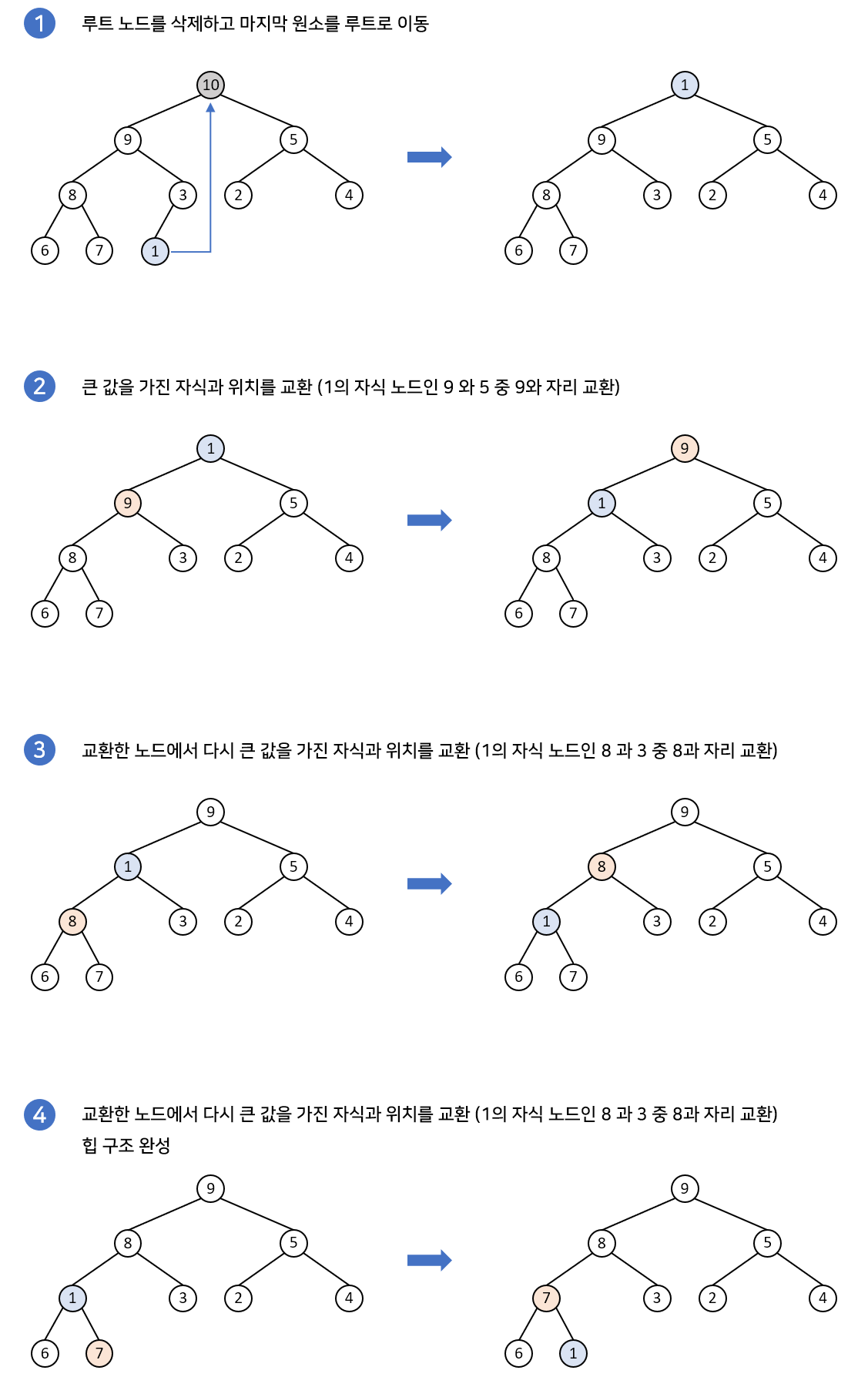
- 삭제 연산
- 시간복잡도
삽입 연산에서 새로운 노드와 부모 노드를 비교해 교환한다. 최악의 경우 루트 노드까지 올라가므로 히프의 높이에 해당하는 비교 연산과 쓰기 연산이 일어난다. 완전 이진 트리의 높이는 대략 이므로 삽입 연산의 시간복잡도는 으로 나타난다.
삭제 연산도 마찬가지로 자식 노드와 비교해 교환하는 부분에서 최악의 경우 말단 노드까지 내려가야 하므로 삭제 연산의 시간복잡도 또한 이다.
5.3 히프의 구현
#include <stdio.h>
#include <stdlib.h>
#define MAX_ELEMENT 200
typedef struct {
int key;
} element;
typedef struct {
element heap[MAX_ELEMENT];
int heap_size;
} HeapType;
// 생성 함수
HeapType* create(){
return (HeapType*)malloc(sizeof(HeapType));
}
// 초기화 함수
void init(HeapType* h){
h->heap_size = 0;
}
// 현재 요소의 개수가 heap_size인 히프 h에 item을 삽입한다.
// 삽입 함수
void insert_max_heap(HeapType* h, element item){
int i;
i = ++(h->heap_size);
// 트리를 거슬러 올라가면서 부모 노드와 비교하는 과정
while ((i != 1) && (item.key > h->heap[i / 2].key)) {
h->heap[i] = h->heap[i / 2];
i /= 2;
}
h->heap[i] = item; // 새로운 노드를 삽입
}
// 삭제 함수
element delete_max_heap(HeapType* h){
int parent, child;
element item, temp;
item = h->heap[1];
temp = h->heap[(h->heap_size)--];
parent = 1;
child = 2;
while (child <= h->heap_size) {
// 현재 노드의 자식노드 중 더 작은 자식노드를 찾는다.
if ((child < h->heap_size) &&
(h->heap[child].key) < h->heap[child + 1].key)
child++;
if (temp.key >= h->heap[child].key) break;
// 한 단계 아래로 이동
h->heap[parent] = h->heap[child];
parent = child;
child *= 2;
}
h->heap[parent] = temp;
return item;
}
int main(void){
element e1 = {10}, e2 = {5}, e3 = {30};
element e4, e5, e6;
HeapType* heap;
heap = create(); // 히프 생성
init(heap); // 초기화
// 삽입
insert_max_heap(heap, e1);
insert_max_heap(heap, e2);
insert_max_heap(heap, e3);
// 삭제
e4 = delete_max_heap(heap);
printf("< %d > ", e4.key);
e5 = delete_max_heap(heap);
printf("< %d > ", e5.key);
e6 = delete_max_heap(heap);
printf("< %d > \n", e6.key);
free(heap);
return 0;
}-실행결과-
< 30 > < 10 > < 5 > 5.4 기타
5.4.1 우선순위에 범위가 존재하는 경우
이 경우 삽입과 삭제 연산 모두 의 시간복잡도로 처리할 수 있는 방법이 있다. 우선순위의 범위가 1 이상 50 이하로 주어져 있다고 가정해보자. 이때 50개의 연결리스트를 생성해 각 우선순위 당 하나의 연결리스트를 할당하면 삽입, 삭제 연산 시간복잡도는 모두 이다. 하지만 이때 우선순위가 같은 데이터는 어느 것이 먼저 처리되어도 상관이 없다고 가정한다. 이러한 방식은 다음에 알아볼 해싱과 연관이 있다.
5.4.2 Build Heap
