
The Bias-Variance Trade-Off
검정 MSE는 대부분 U자 형태의 모습을 보이고 있었다. 이는 통계에서 분산과, 편향에 의해 발생하는 현상인데, 우선 식으로 확인해보면 다음과 같다. ( 와 는 검정(=test)관측치이다. )
이때, 좌변의 는 검정 MSE에 대한 기대값을 의미하며, 우변은 각각 의 분산과 편향의 제곱, 그리고 축소불가능 오차였던 오차 의 분산의 합으로 나타나있다. 일반적으로 검정MSE의 기대값은 아주 큰 수의( 우리가 상상하기 어려울수도 있는) 훈련세트를 활용해서 에 대해 반복적으로 추정을 한 후, 에 최종적으로 검정을 했을 때 얻어지는 검정 MSE들의 평균이다.
위 식에서 알아둬야 할 것은 이전 글의 그림들과 아래에서 확인할 수 있었지만 검정MSE로 표현된 빨간선은 언제나 파선보다 위에 있다는 점이다.
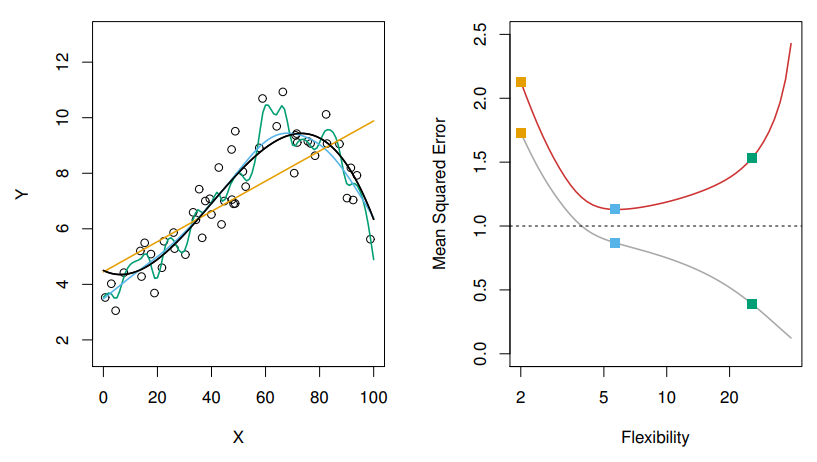
그 이유에 대한 해답이 식에 나타나 있는데 일반적으로 분산인 와 제곱편향인 값은 양수로 표현이 된다. 따라서 축소불가능오차인 에 부가적인 양수값이 더해지는 것이기에 검정MSE의 기대값은 언제나 파선아래로 내려올 수 없음을 확인할 수 있다.
분산이란 무엇을 의미할까?
분산은 기존의 를 추정해왔던 것과 다르게 다른 훈련자료를 통해서(아니면 훈련자료에 어떤 변화를 주어서) 추정했을 때, 의 값이 변동되는 정도를 의미한다. 당연히 기존의 훈련자료와 새로운 훈련자료, 검정자료들은 추정했던 값과의 차이는 존재한다. 그렇지만 이 차이를 줄이는 것이 우리의 목표이기도 하기에( 그래야 MSE값을 줄일 수 있으니까! ), 최대한 많이 변동되지 않는 모델을 찾는것이다. 위 그래프에서 확인할 수 있듯 녹색선은 실제 데이터 분포를 잘 표현하고 있다. 그말은 즉, 유연성이 높다고 표현이 되며, 데이터의 작은 변화에도 그래프에 큰 변동이 발생됨을 의미한다. 이와 반대로 오렌지선은 선형으로 데이터를 표현하고 있으며, 데이터가 변화한들 추세선에는 큰 변화가 없을 것이라고 기대한다.
편향은 무엇을 의미할까?
편향은 Real-World에서의 문제를 훨씬 단순한 (차원의) 모델로 표현하기 때문에 발생하는 오차이다. 이를 설명하기에는 복잡한 과정들이 포함되어있지만, 쉽게 표현하면 다음과 같다
1. 에 대해 와 선형의 상관관계가 존재한다고 가정을한다.
(가정은 가정일뿐, Real-World의 문제는 단순한 상관관계가 존재하기 어려움을 알아두자)
2. 이전 그래프의 비선형적인 예시에 우리가 가정한 선형의 식은 훈련관측치가 많다해도 어느정도의 추정을 잘하지 못할 것을 안다. 이는 곧 편향이 발생한 예이다.
3. 그에 비해 선형적인 예시와 우리가 가정한 선형식은 훈련관측치가 많으면 많을수록 정확하게추정을 찾아갈 것이다.
결론적으로는 위에서 언급했듯 유연성의 증가는 곧 분산의 증가를 가져오게 된다. 다만 분산의 증가와 다르게 편향은 감소하는 경향을 보이는데, 유연성이 증가하면 초기에 편향은 빠르게 감소하는 모습을 보인다. 그리고 어느 일정한 정도의 유연성에 도달하면, 그 후로 분산이 빠르게 증가하는 보습을 보이게 된다. 그 결과 U자형 곡선이 만들어지는 이유가 여기에서 나타난다.
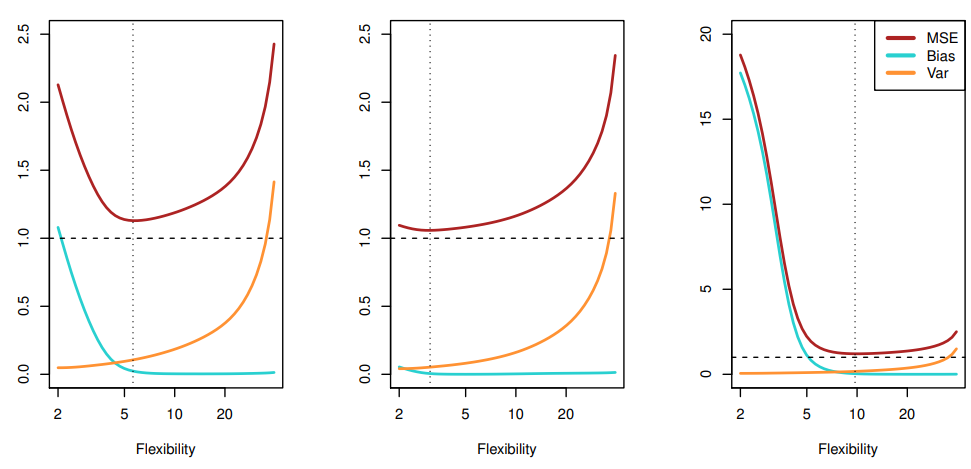
위 그림은 앞선 3가지 그래프들에 대해 위 식을 적용해 그래프로 표현했다. MSE, Bias, Var값이 나타나 있으며, 모델들 마다 MSE값이 최저인 유연성의 지점들이 다 다르다. 자료의 특징들이 잘 반영되어있다는 증거이기도 하며, 맨 처음 trade-off 라는 표현은 결국, 분산과 제곱편향 둘다 너무 한쪽으로 치우치지 않으면서 낮은 값을 찾아가는 과정이 어렵기 때문에 사용했다고 본다.
분류 유형에서의 설정들
분류에서의 예측은 회귀와는 약간 다른점이 있다. 회귀에서는 특정 값을 예측하는 반면, 분류는 어떤 class에 속하게 될지 예측하게 된다. 를 가지고 를 추정할 때, 은 질적변수( 회귀에서는 양적변수였다 )가 된다. 분류에서 를 추정하는 방법은 Train Error Rate를 사용하게 된다. Train Error Rate는 말그대로 추정한 값을 훈련데이터에 적용했을 때 발생하는 오차에 대한 비율을 의미한다.
는 실제 질적변수를, 는 로 예측된 번째 관측치(obs.)를 나타내며, 는 지시변수 (Indicator Variable)이다. 는 두 변수가 같으면 0을, 다르면 1을 반환하게 된다. 즉 위 식은 잘못 분류된 비율을 반환해주는 것을 의미한다.
그렇다면 우리는 결국 훈련에 사용되지않았던 데이터들을 잘 예측하는지 궁금해 하기에 Test Error Rate에 대한 식은 다음과 같다
앞선 식과 다른점은 검정 관측치인 를 사용했고, 를 추정했다는 점이다. 좋은 분류는 결국 위 식의 값이 작은 것, 즉 검정오차가 작은 것을 의미하게 된다. 잘못 분류된 비율을 나타내는 것이므로 적은 수치가 좋은 것이다.
베이즈 분류기
검정오차율( Test Error Rate )은 앞선 수식들로 하여금 예측변수 값이 주어지게 되면, 각 값들을 가장 가능성 높은 클래스에 배정(할당)한 후에 평균을 내어 최소화하는 것을 나타낸다. 그렇다면, 의 값은 가장 가능성 높은 클래스에 잘 배정이 되어야 함을 의미한다.
위 식은 조건부확률( Conditional Probability )로 를 만족할 때, 가 일 확률로 표현된다. 이는 단순하지만 '베이즈 분류기'라고 불린다.
Bayes Graph
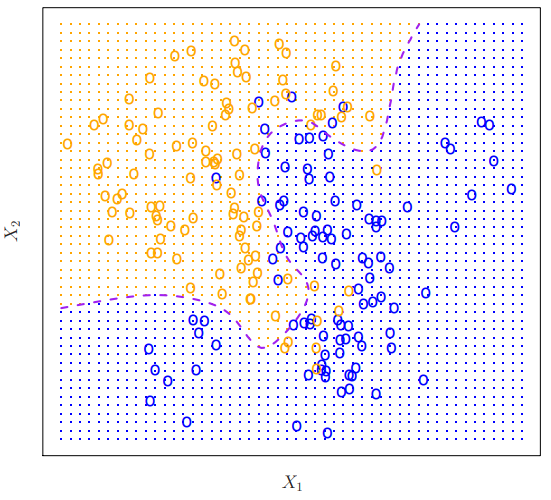
위 그림은 주황색과 파란색관측치( 원으로 표현되어있음 )가 각각 100개씩 나타나있다. 이 자료 한정이지만, 우리는 자료의 분포, 데이터 생성방식을 알고있기에 조건부 확률을 계산할 수 있음을 미리 설정해둔다. (즉 실제로는 모르는 경우가 더 많다는 얘기이다. ) 주황색영역은 > 50% 인 집합을 나타내며, 파란색영역은 그 반대인 <= 50%인 집합을 나타내고 있다. 보라색 점선은 이 둘의 조건부확률이 정확히 50%인 지점을 나타내고 베이즈 결정경계( Bayes Decision Boundary ) 라고 부른다.
베이즈 분류기에서의 검정오차율은 best lower한 값이고, 이를 베이즈 오차율( Bayes Error Rate ) 이라고 부른다. 앞서 기술한 내용 중
검정오차율( Test Error Rate )은 앞선 수식들로 하여금 예측변수 값이 주어지게 되면, 각 값들을 가장 가능성 높은 클래스에 배정(할당)한 후에 평균을 내어 최소화하는 것을 나타낸다.
라고 얘기했었다. 그렇다면 결국 베이즈 오차율은
이면서 곧,
로 표현할 수 있다.
기대값 는 가능한 모든 값에 대해 평균을 나타낸 것이며, 베이즈 오차율은 0보다 큰 값이 나오게 된다. 이는 Real-World의 모집단에서는 클래스가 같을 경우에는 값의 추정이 1이되므로 오차는 0이되지만, 클래스가 겹쳐지는 현상이 발생할 때는(오분류된 것을 의미한다.) 값이 1보다 작아 오차율에 가산되기 때문이다.
K-Nearest Neighbors
우리는 베이즈 분류기가 질적 반응변수를 가진 데이터에 적합하다는 것을 안다. 다만 앞서 기술하였듯, 우리는 실제 와 를 모르기 때문에 조건부분포를 알 수 없다. 따라서 베이즈 분류기는 다른 기법들에 어떤 표준을 제공하며, 주어진 에 대해 의 조건부분포를 추정해 가장 높은 추정확률을 가지는 클래스로 관측치를 분류하게 된다. 이에 대한 적합한 예시는 KNN에서 잘 나타난다. KNN의 K는 양의 정수값을 나타내며 Nearest Neighbors는 말 그대로 근접한 이웃 관측값들을 의미한다. 훈련 데이터 에서 가장 가까운 개의 점( 으로 표시할 예정)을 식별 후 클래스 에 대한 조건부확률을 개의 점들에 대한 비율로 나타내게 된다. 이후에는 베이즈 규칙을 활용해 검정 관측치인 을 확률이 가장 높았던 클래스로 할당하게 된다. 이에 대한 식은 다음과 같다.
KNN GRAPH_1
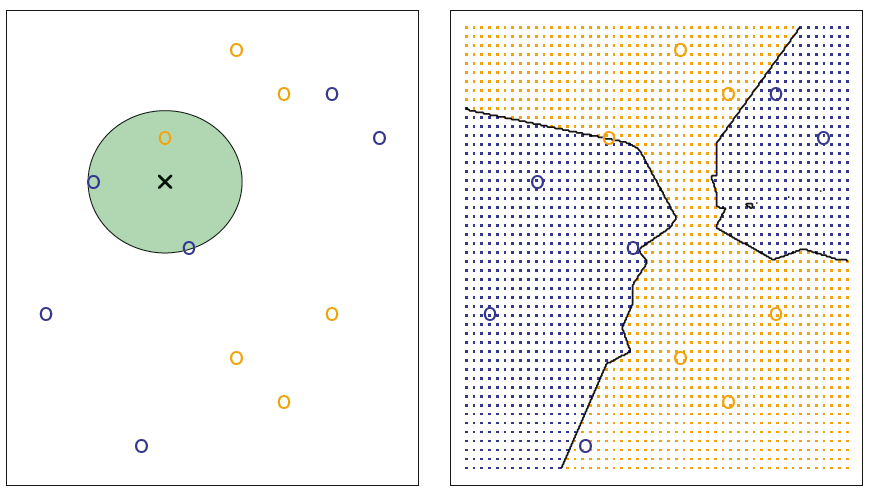
좌측의 그림은 파란색 원6개 주황색 원6개에 대해 일때의 'X'를 추정하는 그림이다. 가 설정되면, 추정하고자 하는 값 주위의 원을 형성하게 되며 원 안에 속한 클래스 비율을 계산하게 된다. 파란색 원이 2개, 주황색 원이 1개이므로 각각의 비율은 와 로 나타낼 수 있다. 이 때 베이즈 분류기는 'X'에 대해 더 높은 클래스인 파란색 원으로 값을 추정할 것이다. 모든 값에 을 적용하게 되면 오른쪽 그림과 같이 결정경계가 생성되며, 어느정도 분류를 잘하고 있음을 보여준다.
KNN GRAPH_2
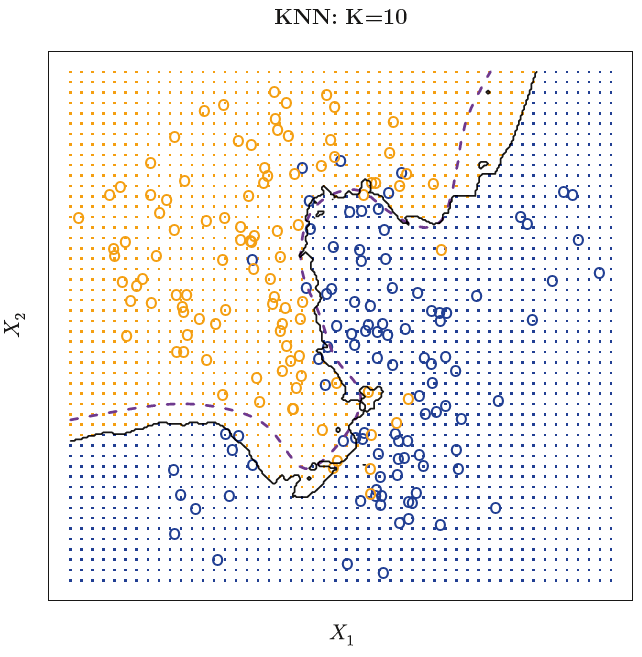
실제로 앞선 예제그림(Bayes Graph)에서 의 값을 부여했을 때, 기존에 존재하던 결정경계와 꽤 잘 들어맞음을 확인할 수 있다.
그렇다고 값을 함부로 설정하면 안되는 예는 다음과 같다.
KNN GRAPH_3
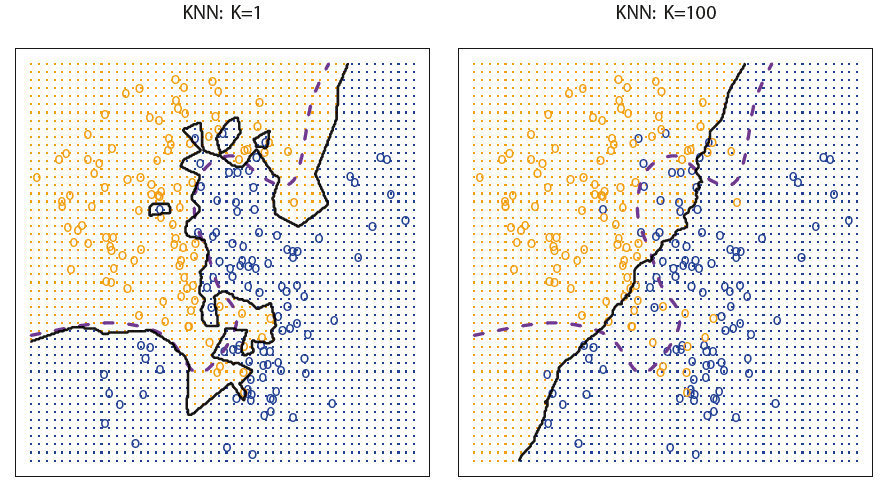
과 일 때의 예제인데, 생각보다 결정경계를 잘 예측하지 못하는 모습을 보여준다. 이는 곧 값이 작을수록 데이터에 유연해지고, 클수록 덜 유연해짐을 나타내고 있다.
결론적으로 회귀와 분류 모두 적절한 수준의 유연함을 추구하도록 노력해야 하는 점을 앞선 사례들을 통해 확인할 수 있었다.
