
모델 정확도 평가
통계학에서는 생각보다 꽤 많은 통계학습 기법이 있다. 이는 통계에서 다루게 되는 자료들이 특정 통계기법 한 가지만으로 좋은 성능을 내는 것이 아니기 때문이다. 그렇기에 자료들마다 최적의, 최고의 통계기법을 선택하는 것이 실제로 통계적인 학습을 수행하는 데 가장 어려운 부분이다.
학습의 품질 측정하기
앞서 오차얘기를 하면서 MSE(Mean Squared Error)에 대해 언급했었다. MSE는 자료(= Data)가 주어졌을때, 통계기법들을 통해 예측을 한 값이 실제값과 차이가 얼마나 되는가에 대한 측도로 제시되었다. 회귀(Regression) 문제에서 자주 사용하며, 다음과 같이 정의할 수 있다.
는 실제값을 나타내고, 는 번째 관측치(Observation)에 대한 예측값을 나타낸다. MSE는 제곱을 한 값이기 때문에 0보다 크지만, 0에 가까우면 가까울 수록 예측값이 실제값과 차이가 나지 않는다는 것이므로, 잘 예측했다고 볼 수도 있지만, 때로는 과적합(Overfit) 된 것이 아닌지 확인해보아야 하는 경우도 있다.
쉽게 현실에 접목해서 생각해본다면, MSE는 이전에 존재하는(= train data) 값들의 예측에는 사실 관심이 없고, 앞으로 미래에 있을 우리가 모르는(= test data) 값들의 예측에 관심이 있기 때문에 최대한 오차가 적었으면 하는 마음을 가지고 있다. 그 예로 이전 주가들을 학습해 다음날의 주가를 예측하거나, 평년 날씨와 기온데이터를 바탕으로 앞으로의 날씨 및 기온 예측 등등 생각보다 일상 속에는 예측에 관한 이야기들이 많이 존재하고 있다.
Test Data의 MSE는 어떻게 줄일 수 있을까?
일반적으로 Test Data의 MSE는 Test Set에 대한 MSE를 평가하여, Minimum(Test set MSE)를 찾는것이 주된 목표이다. 그러나 현실세계에서는 Test Data가 따로 구분되어 있지 않을 수도 있으며, 이럴때는 Train Set로 MSE를 최소로 하는 방법을 찾거나, Train Set을 Train, Valid, Test Set으로 구분하여 검정을 해보는 방법을 생각해 볼 수도 있다. 물론!, 좋은방법은 아니다. 당연한 얘기지만 Train Set의 MSE가 낮다한들, Test Set의 MSE가 가장 낮을 것이라는 보장은 어느 누구도 해줄 수 없기 때문이다.
3가지의 그래프 유형들을 예시로 살펴보자
Graph 1
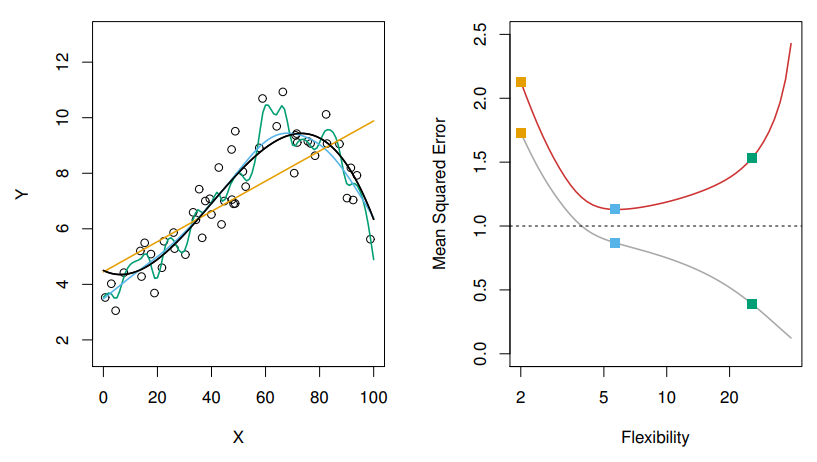
위 그래프의 좌측은 을 가지고 임의의 데이터들을 생성한 것이다. 그래프의 선의 색은 각각 다른방식으로 데이터들을 추정한 선인데, 그래프를 해석하면 다음과 같다
- 오렌지색 선은 선형회귀로 표현한 그래프이고 전반적인 추세는 표현할 수 있지만, 데이터 자체에 대해 유연한 모습( fit with data )은 보이지 않고 있다.
- 파란색, 녹색선은 비교적 데이터에 유연한 편인데, 평활 스플라인을 적용한 그래프들이며, 둘의 차이는 평활도의 차이이다. 유연성이 높으면 녹색선, 적절하면 파란선이 도출된다.
우측그래프는 유연함의 정도에 따른 Train MSE(회색선), Test MSE(붉은선)값을 나타낸다. 각 포인트들은 좌측 그래프의 3가지 표현방식을 나타낸다. 수평의 파선은 앞서 언급했던 축소불가능 오차( : Irreducible Error)이다
- Train MSE는 유연함의 정도가 커질수록 MSE값이 줄어드는 것을 볼 수 있다.
- Test MSE는 유연함의 정도가 커지면 MSE가 줄어들다가 일정 Point에서 다시 증가하는 것을 볼 수있다.
- 파란색의 적합은 Train MSE와 Test MSE값의 차이가 크지않으며, 적절한 MSE를 유지하는 것을 확인할 수 있고, 제일 좋은 모델이라고 판단할 수 있다.
Graph 2
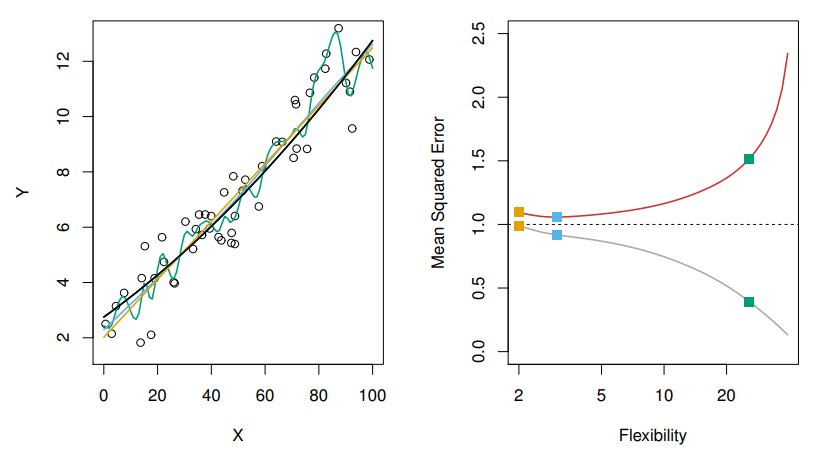
위와 그래프 생성 및 색상에 관한 개념은 동일하다. 다만 데이터가 이번엔 선형의 모습을 보이고 있으며, 오렌지그래프와 파란그래프는 대략적인 추세를 잘 표현하고 있으며, MSE도 비교적 낮은 모습을 보여주고 있다. 반면 녹색그래프는 너무 유연한 나머지 심한 과적합이 된 것을 볼 수 있다.
Graph 3
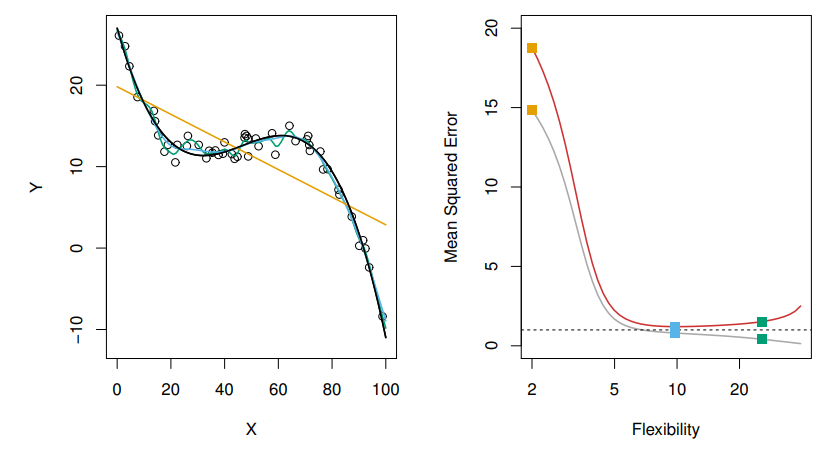
마지막 그래프는 비선형의 예를 보여주고 있다. 당연한 얘기지만 오렌지그래프는 전혀 예측을 하지못해 MSE의 값이 크게 도출되었다. 파란그래프와 녹색그래프는 추세를 잘 예측하고 있는 편이며, MSE도 낮은 편이다. 다만 여전히 너무 유연한 것은 대략적인 추세를 예측하는 것보다는 좋지않음을 보여주고 있다.
앞선 얘기들과 그래프 예제를 통해 우리는 검정 MSE를 최소로 하는 점을 찾아야 하는것을 주된 목표로 해야한다는 것을 알게 되었다. 그래프 예제에서는 데이터의 형태에 따라 적절한 모델을 설정해야하는 것을 아게 되었고, 모델을 설정하면서 최소의 MSE를 찾아가기 위한 방법들을 계속해서 확인해볼 예정이다.
