
용어정리
- 훈련 : 모델에 데이터를 전달한 후 데이터들의 규칙을 학습하는 과정
- 모델 : 알고리즘이나 수식들을 구체화하여 표현한 것, 보통 프로그램으로 알고리즘을 구현한 것
- 정확도 : 훈련데이터를 가지고 테스트데이터를 예측했을 때 정답률
- 샘플 : 관측된 데이터를 의미한다 ( 1 row = 1 sample )
- 샘플링 편향 ( Sampling Bias ) : 훈련set와 테스트set에 데이터가 골고루 섞여있지 않은 것을 의미한다.
KNN
K-Nearest Neighbor Algorithm (KNN)은 데이터에 대한 정답을 주위 데이터에서 찾는다. 즉, 주위 데이터의 클래스 수를 파악하고, 그 중 다수의 클래스에 속한다고 판단하는 알고리즘. 구분할 데이터의 개수는 로 지정한다. 예시는 다음과 같다.
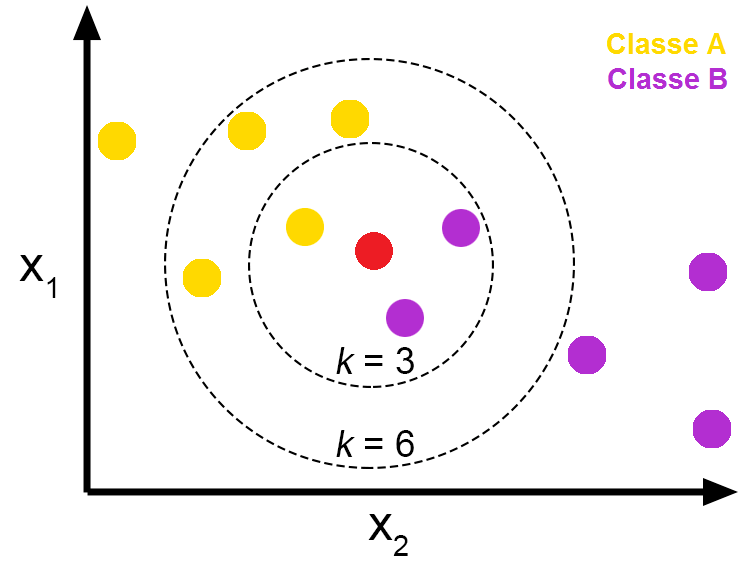
위 그림에서 빨간점을 예측한다고 했을 때, 일때( 주변 데이터의 개수를 3개로 볼 때 )와 일때( 주변 데이터의 개수를 6개로 볼 때 )의 예측하는 클래스는 달라진다. 일때는 주위에 보라색 2개, 노란색 1개이므로 빨간점을 보라색으로 예측하게 된다. 반면 일때 노란색은 4개, 보라색은 2개이므로 빨간점을 노란색으로 예측하게 된다.
KNN 알고리즘은 파이썬에서 다음과 같이 불러올 수 있다.
import sklearn
model = sklearn.neighbors.KNeighborsClassifier()
or
from sklearn.neighbors import KNeighborsClassifier()
model = KNeighborsClassifier(n_neighbors = k)
# k에 주위 데이터를 몇개를 분석할 건지 입력하면 된다.또한 앞으로 많은 알고리즘들은 위와 같이 호출한 뒤 fit(), predict(), score()메서드를 통해서 학습하고, 예측하고, 정확도를 판단한다.
model.fit( 훈련데이터, 정답데이터 )
model.predict( 테스트데이터 )
model.score( 실제데이터, predict한 데이터 )지도학습, 비지도학습
머신러닝은 크게 지도학습(Supervised Learning)과 비지도학습(Unsupervised Learning)으로 구분이 된다. 지도학습은 정답이 존재하는 방법이고, 비지도학습은 정답이 존재하지않아 특성을 데이터의 특성을 찾아가는 방법으로 볼 수 있다.
그렇다면 지도학습은 정답이 존재한다고 했는데, 어떤과정으로 이루어지는가?
지도학습은 훈련(학습)하기위한 Input( = data )이 존재하고 정답을 맞추기 위한 target이 존재하게 된다. 이 것들을 가지고 앞서 언급했던 model.fit()과 같은 method를 사용해서 정답을 맞히기 위한 과정을 학습하게 된다.
비지도학습은 Chap.6에서 언급예정이다.
훈련 Set, 테스트 Set
일반적으로 훈련 데이터와 테스트 데이터는 구분되어 있다. 다만 구분되어 있지 않을 때는 훈련 데이터에서 일부를 테스트 데이터로 활용하기도 한다. 이때, 훈련에 사용하는 데이터를 훈련 Set로 부르고, 테스트에 사용하는 데이터를 테스트 Set으로 분류한다. 훈련 Set와 테스트 Set를 나누는 비율은 꽤나 다양한데, 전체 통합된 데이터에서 7:3, 8:2로 나누는 경우도 있고, 예를들어 8:2로 나눴을 경우엔 훈련 -> 테스트 하기 전 검증 Set라는 것을 따로 만들어 검증해보는 경우도 존재한다. 이는 사실 다양하게 데이터를 활용해서 시도해보는 것을 추천하며, 익숙해지는 것 또한 존재한다.
Sklearn을 활용한 훈련, 테스트 Set 생성하기
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split( X, y, stratify = y, random_state = 42 )
X_train.shape, X_test.shape, y_train.shape, y_test.shape생각보다 쉽게 Train, Test Set들을 생성할 수 있다. stratify 옵션은 train set과 test set에서의 정답에 대한 비율, 예를들면 y 전체 정답에 대한 비율이 7:3이라면 train과 test로 나눈 set들에도 정답에 대한 비율이 7:3으로 동일하게 나눠지는 효과를 준다. 즉, 적절하게 학습을 하고 예측에 대한 정확도를 높이기 위한 과정 중 한가지이다.
