- RMSE(Root Mean Squared Error) : 실제 정답과 예측한 값의 차이의 제곱을 평균한 값의 제곱근(내용추가)
- RSS(Root Square Sum; 잔차제곱합) :
1. Baseline
- 문제 해결을 시작할 때 쉽게 사용해볼 수 있는 샘플
- Kernel(커널) : 주피터 노트북 형태의 파일이 캐글 서버에서 실행될 때 그 프로그램을 일컫는 개념
- missingno 라이브러리 : missingno 라이브러리의 matrix 함수를 사용하면, 데이터의 결측 상태를 시각화를 통해 살펴볼 수 있습니다.
- 고급 인덱싱
- loc : 라벨값 기반의 2차원 인덱싱
df.lob[행 인덱싱값, 열 인덱싱값(선택)]- 슬라이스, index data의 리스트 사용 가능
- iloc : 순서를 나타내는 정수 기반의 2차원 인덱싱
- 순서를 나타내는 정수(integer) 인덱스만 받음
- 그 외는 loc 인덱서와 동일
- loc : 라벨값 기반의 2차원 인덱싱
- apply() : 행/열/전체의 원소에 원하는 연산을 지원
- seaborn.kdeplot() : 이산형 데이터를 커널 밀도 추정(KDE)을 사용하여 일변량 또는 이변량 밀도곡선 분포를 그려줌
- 블렌딩(Blending) 기법 = 앙상블(Ensemble) 기법
- 여러가지 모델을 종합하여 결과 얻는 기법
- 하나의 강한 머신러닝 알고리즘보다 여러 개의 약한 머신러닝 알고리즘이 낫다
- 비정형 데이터 분류 ⇨ 딥러닝, 정형 데이터 분류 ⇨ 앙상블
- 더 유연성 있는 모델을 만들며 더 좋은 예측결과를 기대할 수 있음
| 앙상블 학습 유형 | 문제유형 | 자료형 | 설명 |
|---|---|---|---|
| Voting (보팅) | 분류 | categorical | 여러 모델이 분류해 낸 결과들로부터 다수결 투표를 통해 최종 결과를 선택하는 방법 |
| Averaging (에버리징) | 회귀 | numerical | 각 모델이 계산해 낸 실숫값들을 평균 혹은 가중평균하여 사용하는 방법 |
2. 최적 모델 찾기
- 파라미터 : 데이터 분석을 통해 얻은 값
- ex) 션형회귀 y_pred = W*x +b 에서 W가 파라미터
- 하이퍼파라미터 : 사용자가 직접 입력하는 값, 예측 알고리즘 모델의 문제점을 위해 조절됨
- ex) epoch값 등
- 하이퍼파라미터 조합하는 방법
- 그리드 탐색
- 사람이 먼저 탐색할 하이퍼 파라미터의 값들을 정해두고, 그 값들로 만들어질 수 있는 모든 조합을 탐색
- 장점 : 최적의 조합을 찾을 수 있는 가능성이 언제나 열려 있음
- 단점 : 가능성 또한 랜덤성에 의존하기 때문에 언제나 최적을 찾는다는 보장은 없음
- 랜덤 탐색
+ 사람이 탐색할 하이퍼 파라미터의 공간만 정해두고, 그 안에서 랜덤으로 조합을 선택해서 탐색하는 방법
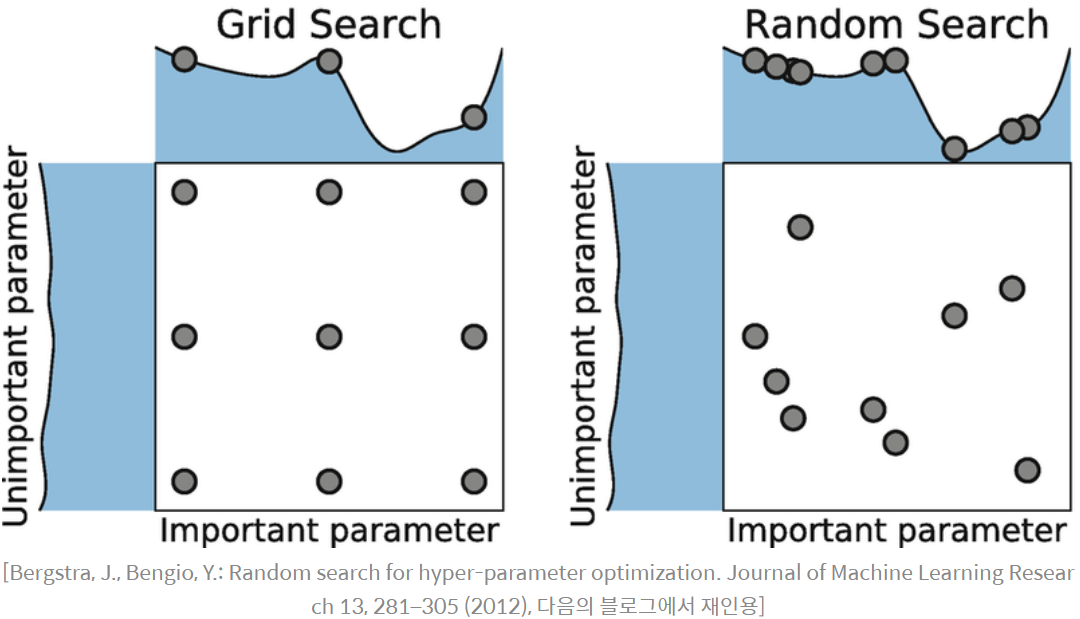
- 그리드 탐색
- GridSearchCV() : 다양한 파라미터를 입력하면 가능한 모든 조합을 탐색(사이킷런 라이브러리) - 예시 추가
- scoring종류 : 분류(Classification)/클러스터링(Clustering)/회귀(Regression)
- 모델 평가 규칙
| 인자 | 설명 |
|---|---|
| param_grid | 탐색할 파라미터의 종류 (딕셔너리로 입력) |
| scoring | 모델의 성능을 평가할 지표 |
| cv | cross validation을 수행하기 위해 train 데이터셋을 나누는 조각의 개수 |
| verbose | 그리드 탐색을 진행하면서 진행 과정을 출력해서 보여줄 메세지의 양 (숫자가 클수록 더 많은 메세지를 출력합니다.) |
| n_jobs | 그리드 탐색을 진행하면서 사용할 CPU의 개수 |
- pandas.DataFame.sort_values() : 두 축 중 하나를 따라 값을 기준으로 정렬
- axis = 0(index; default), 1(columns)
