1. 분포가설과 분산표현
- 희소표현(Sparse Representation) : 벡터의 특정 차원에 단어 혹은 의미를 직접 매핑하는 방식
- ex)
사과:[0, 0], 바나나:[1, 1], 배:[0, 1]
- ex)
- 분포 가설(distribution hypothesis) : 유사한 맥락에서 나타나는 단어는 그 의미도 비슷하다 라는 것
- 단어의 분산 표현(Distributed Representation)
- 벡터에 단어의 의미를 여러 차원에 분산하여 표현
- ex) 유사한 맥락에 나타난 단어끼리는 두 단어 백터 사이의 거리를 가깝게, 그렇지 않으면 멀어지도록 조정
- 장점 : 단어 간의 유사도 를 계산으로 구할 수 있음
2. Embedding 레이어
- 단어의 분산 표현을 구현하기 위한 레이어 ⇨ 컴퓨터용 단어 사전
- Embedding 레이어만 훈련하기 위한 방법 : ELMo, Word2Vec, Glove, FastText 등
- Embedding size = 단어를 깊기 표현
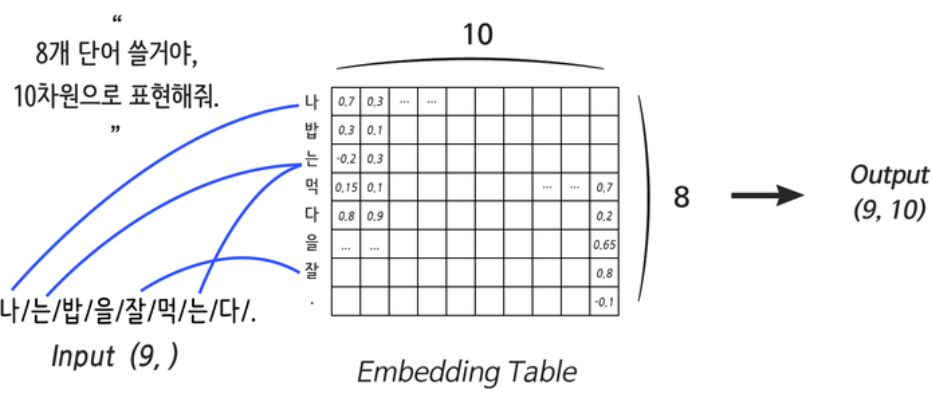
- 룩업 테이블(Lookup Table) : 주어진 연산에 대해 미리 계산된 결과들의 집합(배열)
원-핫 벡터로 표현된 서로 다른 두 단어가 항상 직교한다는 것은 모든 단어가 단어 간 관계를 전혀 반영하지 못한 채 각각 독립적인 상태로 존재함을 의미
- 원-핫코딩 자체는 '단어에 순번(인덱스)을 매겨서 표현하는 방식' 이지만, 단어 사전을 구축하고 단어를 사전의 인덱스로 변환만 해주면 Embedding 레이어를 완벽하게 사용할 수 있다
- 주의 사항❗
- 어떤 연산 결과를 Embedding 레이어에 연결시키는 것은 불가능
- Embedding 레이어는 입력에 직접 연결되게 사용해야 한다는 것
3. Recurrent 레이어
1) RNN
- 순차적인(Sequential) 특성 : 문장, 영상, 음성 등의 데이터의 특성
- 연관성과는 상관 없음
- ex)
[1, 2, 3, 오리, baby, 0.7]도 요소들 간의 연관성이 없지만 시퀀스 데이터
- But! 인공지능 예측을 위해 요소간 연관성이 있어야 하므로 딥러닝에서의 시퀀스 데이터는 순차적인 특성을 필수로 갖음.
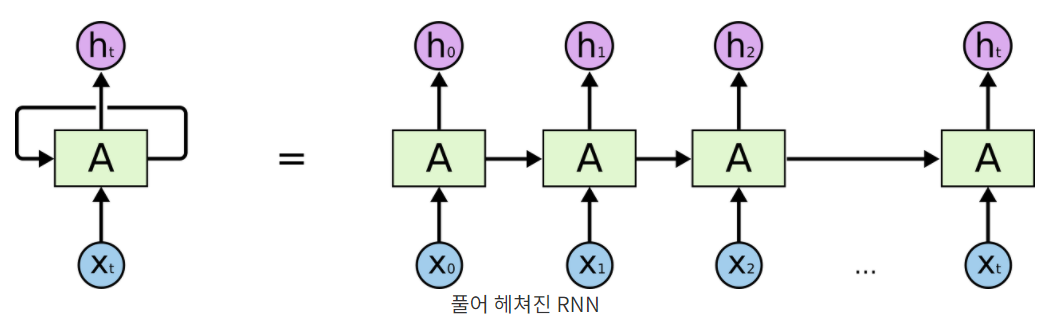
- Recurrent Neural Network 또는 Recurrent 레이어(이하 RNN)
- 스스로를 반복하면서 이전 단계에서 얻은 정보가 지속되도록 함
- 문장 데이터에 특화된 레이어
- (입력의 차원, 출력의 차원)에 해당하는 단 하나의 Weight를 순차적으로 업데이트
- 주의 : RNN의 입력으로 들어가는 모든 단어만큼 Weight를 만드는 게 아님
- 단점 : 처리 속도가 느림
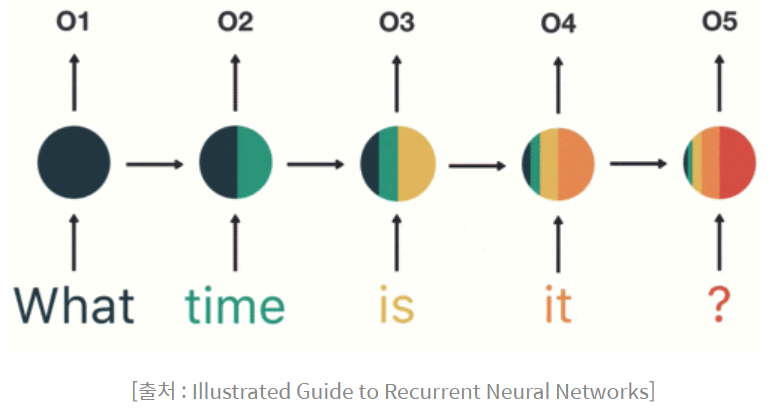
- 기울기 소실(Vanishing Gradient) 문제
- 위 그림에서 What의 정보가 마지막 입력인 '?'에서는 거의 희석된 모습
- 입력의 앞부분이 뒤로 갈수록 옅어져 손실이 발생
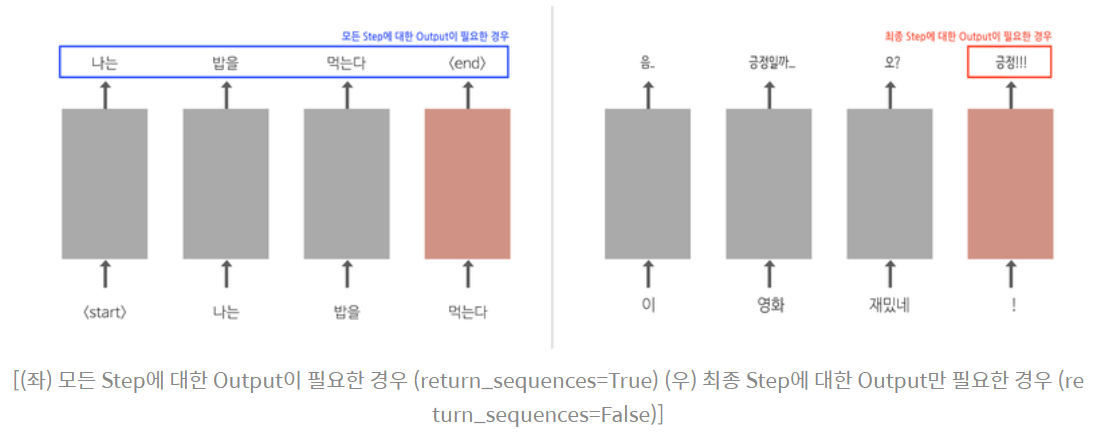
2) LSTM
-
Long Short-Term Memory의 약어
-
기울기 소실 문제를 해결하기 위해 고안된 4종류의 서로 다른 Weight를 가진 RNN 레이어
RNN의 네트워크 구조 특성상, 입력되는 문장이 길수록 초기에 입력된 단어들의 미분 값이 매우 작아지거나 커지는 현상이 발생
- Vanishing Gradient : 미분 값이 너무 작아짐 ⇨ 가중치 업데이트가 잘 안되어 학습이 잘 이뤄지지 않음
- Exploding Gradient : 미분 값이 너무 커짐 ⇨ 가중치 업데이터가 너무 커서 학습이 불안정
-
Cell state : LSTM의 3개의 Gate Layer을 이용하여 정보의 반영 여부를 결정해 줌
- Forget Gate Layer : cell state의 기존 정보를 얼마나 잊어버릴지를 결정
- Input Gate Layer : 새롭게 만들어진 cell state를 기존 cell state에 얼마나 반영할지를 결정
- Output Gate Layer : 새롭게 만들어진 cell state를 새로운 hidden state에 얼마나 반영할지를 결정
-
LSTM의 변형 모델
- 엿보기 구멍(peephole connection)
- Gate layer들이 cell state를 쳐다보게 만드는 것
- GRU(Gated Recurrent Unit)
- Forget Gate와 Inpurt Gate를 Update Gate로 합치고, Cell State와 Hidden State를 합침
- 기존 LSTM보다 단순한 구조
- LSTM과 구조상, 분석결과상 차이가 없음
- 장점 : LSTM에 비해 GRU가 학습할 가중치(Weight)가 더 적음(LSTM의 1/4)
- 엿보기 구멍(peephole connection)
| 분류 | 장점 |
|---|---|
| LSTM | GRU에 비해 Weight가 많기 때문에 충분한 데이터가 있는 상황에 적합 |
| GRU | 적은 데이터에도 웬만한 학습 성능을 보여줌 |
3) 양방향(Bidirectional) RNN
- 진행 방향이 반대인 RNN을 2개 겹쳐놓은 형태
- 기계번역 같은 테스크에 유리함
- RNN의 2배 크기 Weight가 정의됨(∵ Weight와 역방향 Weight를 각각 정의하므로)
오늘도 어려운 용어들이...🤪 정리 안되는 부분 다시 읽어보면서 정리 해보자!
2022.10.04
- Sequential data 란?
- RNN, LSTM의 특징 정리
위 항목 위주로 정리해보자
