1. 텍스트 요약(Text Summarization)
- 긴 길이의 문서(Document) 원문을 핵심 주제만으로 구성된 짧은 요약(Summary) 문장들로 변환하는 것
- 요약 전후에 정보 손실 발생이 최소화되어야 함(중요) ⇨ '정보 압축 과정'과 동일

1) 추출적 요약(Extractive Summarization)
- 원문의 문장을 추출하여 요약하는 방식
- ex) 네이버 뉴스의 요약봇(TextRank 알고리즘)
2) 추상적 요약(Abstractive Summarization)
- 원문에서 내용이 요약된 새로운 문장 생성
- 자연어 생성(Natural Language Generation, NLG)의 영역
- '어느 것이 핵심문장인지'를 판별한다는 점에서 문장 분류(Text Classification) 문제로 볼 수 있음
RNN은 학습 데이터의 길이가 길어질수록 먼 과거의 정보를 현재에 전달하기 어렵다는 '장기의존성(long term dependencies)' 문제가 있음. 이 문제를 해결하기 위해 LSTM과 GRU가 등장했지만, 이 둘도 부족해서 어텐션(Attention) 메커니즘이 등장함
2. 인공신경망으로 텍스트 요약 훈련시키기
📌목표 : seq2seq으로 추상적 요약(Abstractive Summarization)방식의 텍스트 요약기 만들기
-
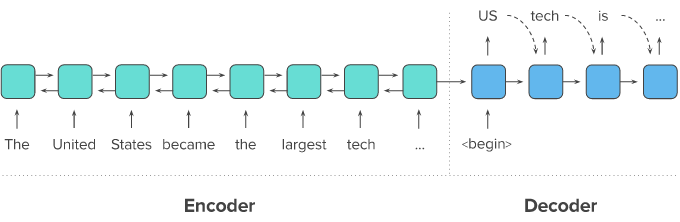
seq2seq
- 두 개의 RNN 아키텍처를 사용하여 입력 시퀀스로부터 출력 시퀀스를 생성해내는 자연어 생성 모델
- 인코더 역할 : 원문을 고정 (context) 백터로 변환
- 디코더 역할 : context 벡터로 요약문장 완성
-
LSTM
- 바닐라 RNN과 차이점 : time step의 셀에 hidden state뿐만 아니라, cell state도 함께 전달한다는 점
- context 벡터로 hidden state
h, cell statec로 두개 필요

-
시작/종료 토큰 : 데이터의 예측 대상 시퀀스의 앞, 뒤에는 시작 토큰과 종료 토큰을 넣어주는 전처리
- 시작 토큰 SOS
- 종료 토큰 EOS

-
어텐션 메커니즘(Attention Mechanism)
- 인코더의 모든 step의 hidden state의 정보가 context 벡터에 반영
3. 실습
- NLTK의 불용어(stopwords) 사용
- NLTK(Natural Language Toolkit) : 영어 기호, 통계, 자연어 처리를 위한 라이브러리
- tf.keras.callbacks.EarlyStopping : 특정 조건시, 학습 조기 종료 함수
Summa패키지 : summarize 모듈을 제공
