1.빅데이터 연대기
| GRS (Google File System) | 하둡(Hadoop) | 스파크(Spark) | |
|---|---|---|---|
| 언어 | Java 프로그래밍 언어 기반 | java와 Scala가 기본 언어 | |
| 특징 | - Google - 분산처리에 적합한 파일시스템 - 복제가 용이함 | - Apache 재단 - 빅데이터용 오픈소스 - HDFS(Hadoop Distributed File System)와 MapReduce | - RDD(Resilient Distributed Dataset; 탄력적 분산 데이터셋)를 이용 |
 |  |  |
2. 빅데이터 양대산맥
1) Hadoop Ecosystem
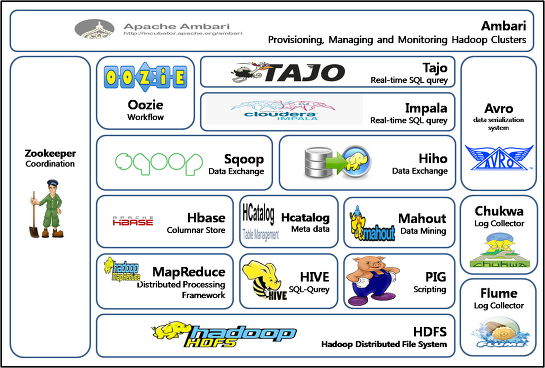

- 컴포넌트 역할별
- 컴포넌트(Component) : 프로그래밍에 있어 재사용이 가능한 각각의 독립된 모듈

- 컴포넌트(Component) : 프로그래밍에 있어 재사용이 가능한 각각의 독립된 모듈
데이터 수집(Data Ingestion) : 스쿱(Sqoop), 플럼(Flume)
데이터 처리(Data Processing) : 하둡 분산파일시스템(HDFS), 맵리듀스(MapReduce), 얀(Yarn), 스파크(Spark)
데이터 분석(Data Analysis) : 피그(Pig), 임팔라(Impala), 하이브(Hive)
데이터 검색(Data Exploration) : 클라우데라 서치(Cloudera Search), 휴(Hue)
기타 : 우지(Oozie), HBase, 제플린(Zeppelin), SparkMLlib, 머하웃(mahout)
2) Spark Ecosystem
- 하둡 기반의 빅데이터 생태계를 이루는 주요한 컴포넌트로 어울려 존재함
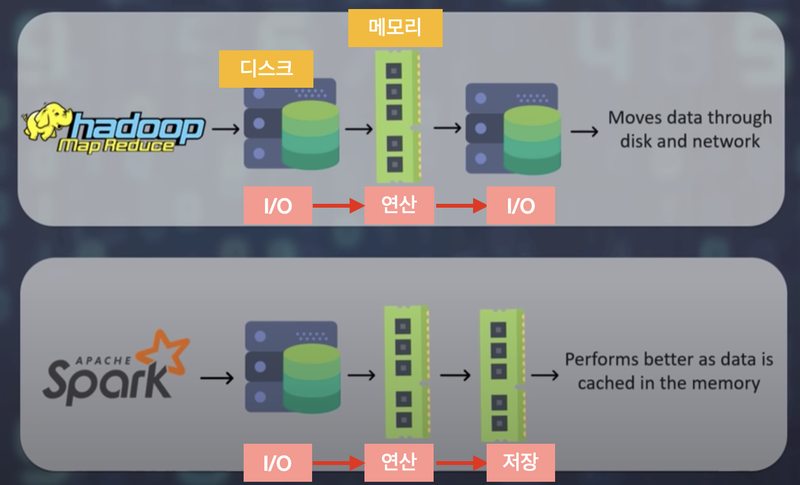
- 스파크는 In-memory 기반의 클러스터 컴퓨팅 데이터 처리 프로그램
- 특징
- 하둡의 HDFS 같이 스파크의 전용 분산 데이터 저장 시스템을 별도로 가지고 있지 않다
- 유연한 확장성이 강조된 설계 사상

RDD(탄력적 분산 데이터 셋; Resilient Distributed Dataset)
- 스파크는 RDD(Resilient Distributed Dataset)를 구현하기 위한 프로그램
- 장점
- 메모리 기반의 대량의 데이터 연산이 가능
- 하둡보다 100배는 빠른 연산을 가능
- 특징
- In-Memory
- Fault Tolerance
- Immutable(Read-Only) : 불변(Read-Only, 메모리의 데이터를 읽기 전용)
- Partition : RDD데이터의 부분을 표현하는 단위(데이터를 여러 대의 머신에 분할해서 저장
1) RDD 생성(Creation)
- 내부에서 만들어진 데이터 집합을 병렬화하는 방법: parallelize()함수
- 외부의 파일을 로드하는 방법: .textFile() 함수
2) RDD 동작(Operation)
- Transformations : RDD에게 변형 방법(연산 로직, 계보, lineage)을 알려주고 새로운 RDD를 만듬
- Actions : 실제 연산의 수행(결과값 출력 및 저장)
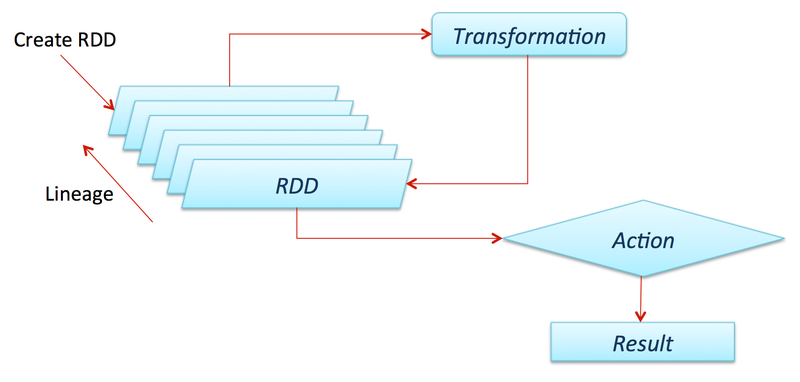
- RDD의 생성, transformations 동작, actions 동작을 도식화
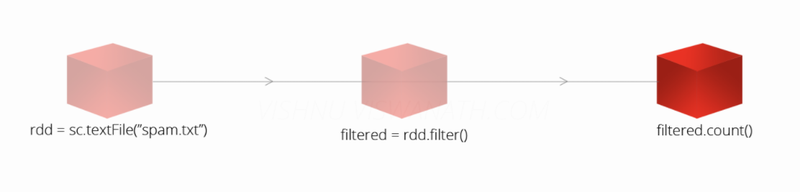
sc.textFile()RDD 생성 But, 실제 RDD의 lineage(계보)filter()transformations의 함수counts()Actions의 함수, 실제 RDD가 생성되는 시점

느긋한 계산법
- 결괏값이 필요할 때까지 계산을 늦추다가 정말 필요한 시기에 계산을 수행하는 방법
SparkContext
-
스파크의 엔트리포인트(= SparkContext) 객체선언
- 스파크는 SparkContext라는 특수 객체를 만들어 이 객체를 통해 스파크의 모든 기능에 접근함
- SparkContext를 생성한다 = 스파크를 초기화한다(Initializing Spark)

-
동장 방식
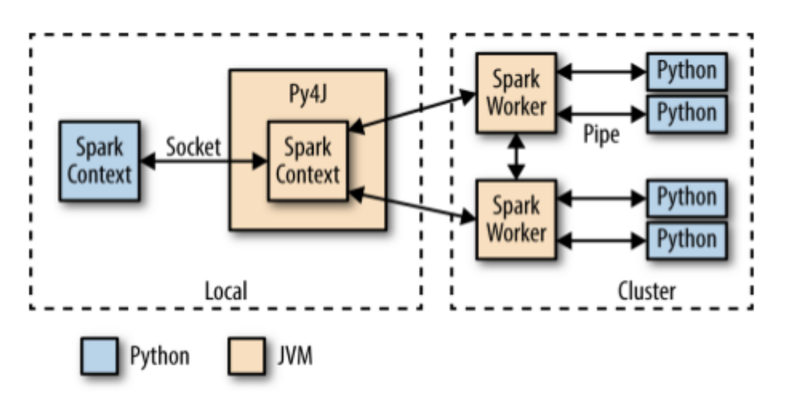
-
주요내용
- 문법: pyspark.SparkContext()
- 스파크 기능의 기본 엔트리 포인트입니다.
- 스파크 클러스터와 연결을 나타내며 RDD를 만들고 브로드캐스트 하는데 사용될 수 있습니다.
- JVM 당 하나만 활성화, 새로운 것을 만들기 전에 것은 활성을 중지해야 함
